PyTorch 2.0 编译的挑战
自 PyTorch 2.0 (PT2) 及其强大的新编译基础设施发布以来,研究人员和工程师们受益于模型执行速度和运行时效率的显著提高。然而,这些收益也伴随着代价:初始编译可能会成为一个显著的瓶颈,特别是对于像 Meta 内部用于推荐的大型复杂模型而言。
了解编译瓶颈
PT2 引入了一个编译步骤,在执行之前将 Python 模型代码转换为高性能机器代码。
虽然结果是更快的训练和推理,但编译非常大型的模型可能需要长达一个小时或更长时间,尤其是在冷启动时,对于我们一些具有 Transformer 之外复杂模型架构的内部推荐模型而言。
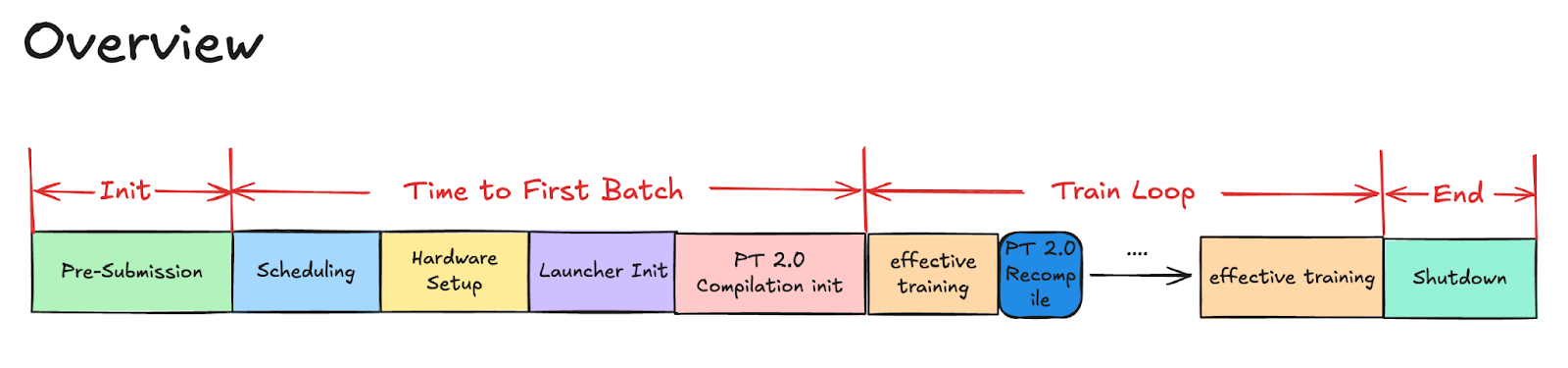
图 1. 训练概述
2024 年末,我们启动了一项重点计划,旨在分解和缩短我们最大的基础模型之一的 PT2 编译时间。我们首先运行一项全面的、长时间的编译任务,对 PT2 编译过程进行详细分析。
Tlparse
Tlparse 解析结构化的 Torch 跟踪日志并输出分析数据的 HTML 文件。这使我们能够识别编译各个阶段的瓶颈。
使用设置了 TORCH_TRACE 环境变量的 PyTorch 运行
TORCH_TRACE=/tmp/my_traced_log_dir example.py
|
将输入馈送到 tlparse
tlparse /tmp/my_traced_log_dir -o tl_out/ |
结果将日志组织成几个易于理解的部分,突出显示每次分析重新启动的时间、任何图中断等。它还提供跟踪文件,帮助您详细分析执行和性能。
如果您需要更多信息来运行 Tlpase,可以参考这些步骤。
示例结果:
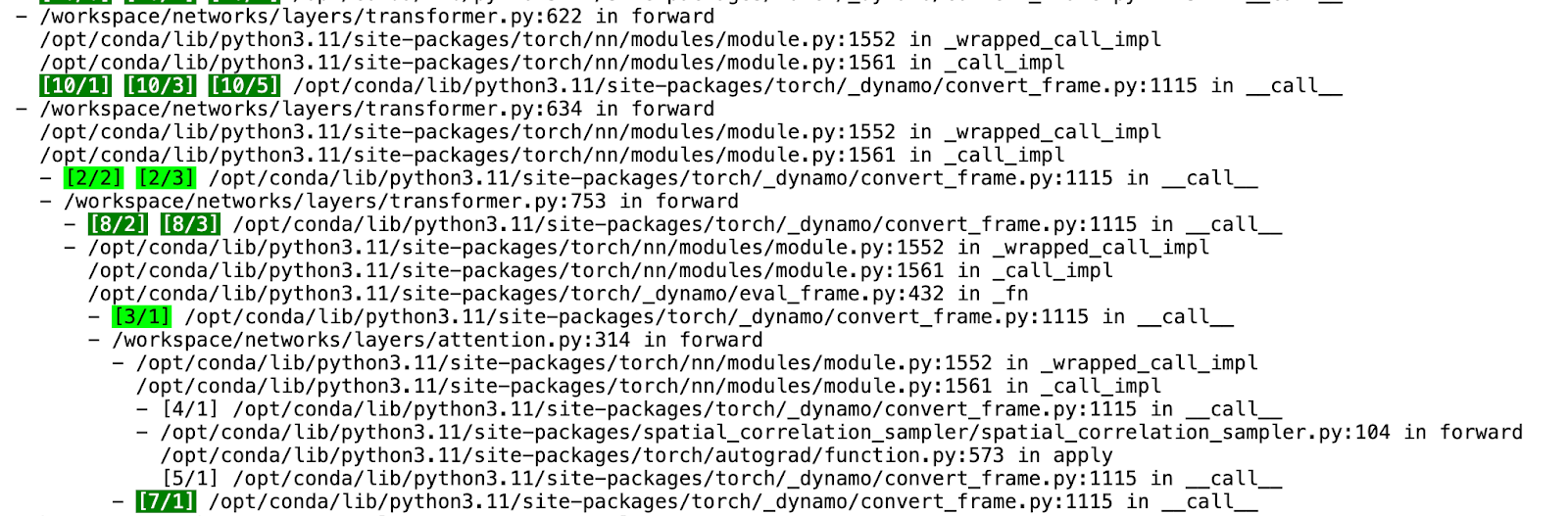
图 2. PT2 编译 HTML
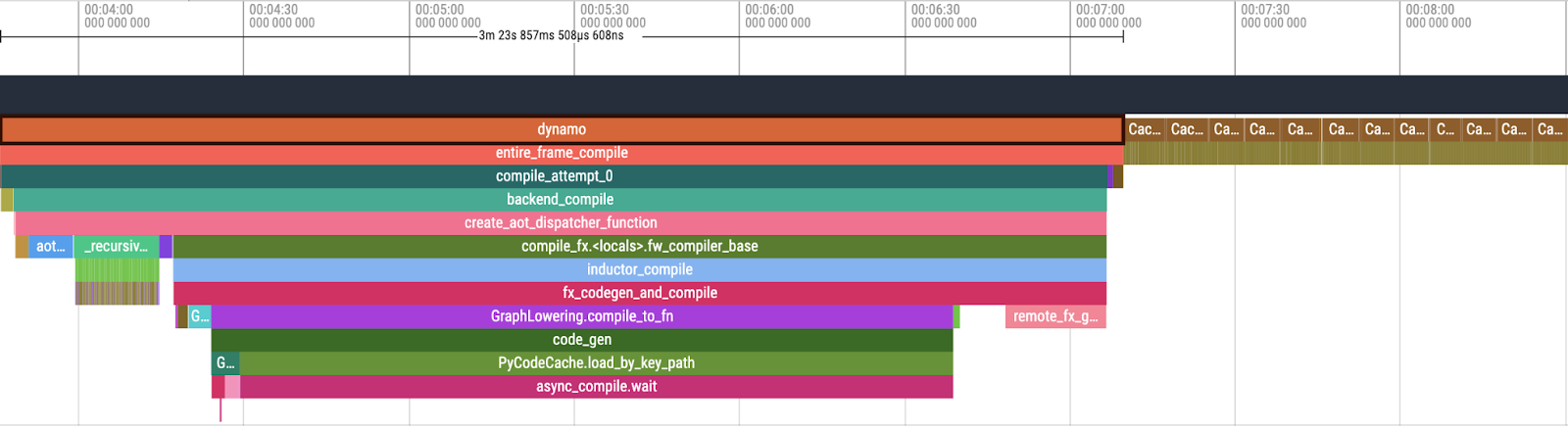
图 3. Perfetto UI 中 PT2 编译概述
在检查 Tlparse 的输出时,我们关注 PT2 编译堆栈的以下关键组件:
- Dynamo:负责动态图转换和优化的初始阶段。
- AOTInductor (AOTDispatch):将 PyTorch 的自动梯度引擎重载为跟踪自动微分,以生成提前反向跟踪。
- TorchInductor:一种深度学习编译器,可为多个加速器和后端生成快速代码。对于 NVIDIA 和 AMD GPU,它使用OpenAI Triton 作为关键构建块。
在此分析之后,我们系统地解决了每个瓶颈区域,并进行了有针对性的改进,以减少整体编译时间。
| 阶段 | 时间(独占,秒) |
| 总计 | 1825.58 |
| Dynamo | 100.64 (5.5%) |
| AOTDispatch | 248.03 (13.5%) |
| TorchInductor | 1238.50 (67.8%)
大部分是 async_compile.wait (843.95) |
| CachingAutotuner.benchmark_all_configs | 238.00 (13.0%) |
| 剩余 (inductor) | 0.41 (0%) |
缩短 PT2 编译时间的关键重点领域
根据对基线编译作业的分析,我们确定了几个关键领域,以期缩短整体编译时间,尤其是对于冷启动:
- 识别并优化最耗时的区域,以最大程度地减少编译次数。
- 增强async_compile.wait 过程,以加速 Triton 编译。
- 有效修剪Triton 自动调优配置,特别是用户定义的内核配置,以减少编译时间和基准测试时间。
- 提高整体PT2 缓存性能并提高下游作业的缓存命中率。
技术深入探讨
在过去一年中,我们与 Meta 的多个团队合作,开发并实施了几项旨在减少 PT2 编译时间的新技术。以下是我们应用于基础模型的关键技术概述。
1. 通过 Triton 编译实现最大并行度
此优化包括两项关键改进:避免在父进程中进行 Triton 编译,以及通过在工作进程中调用 Triton 并使用未来缓存来更早地启动 Triton 编译,以增加编译过程的并行度。
具体而言,我们的并行编译工作器现在编译 Triton 内核并将编译结果直接传递给父进程,消除了父进程中冗余编译的需要。这增强了并行性并减少了整体编译时间。
2. 动态形状标记
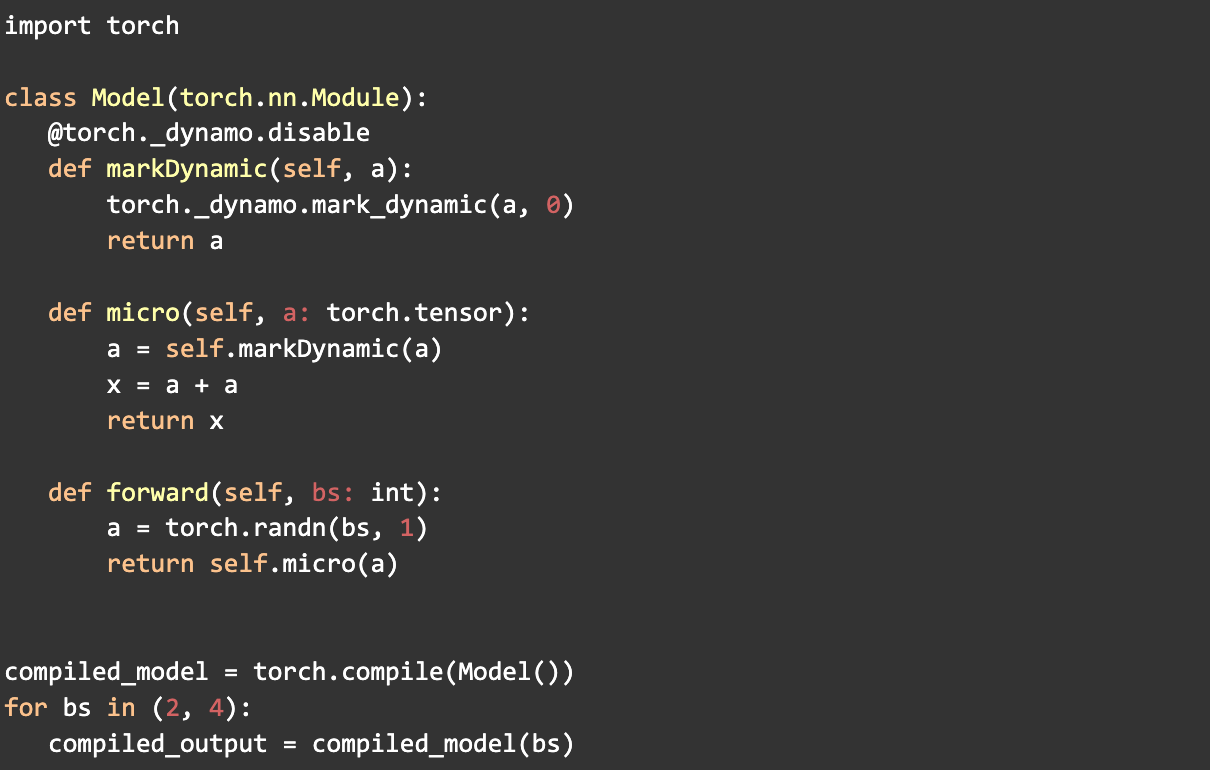
- mark_dynamic
使用 PyTorch 的mark_dynamic API 有助于在编译前识别动态形状。由于许多重新编译发生在编译期间张量形状发生变化时,将这些形状标记为动态可以显著减少重新编译的次数。这反过来又提高了整体 PT2 编译时间。
此过程涉及将张量标记为动态并单独处理专门化。最初,确定专门化以及如何最好地将它们标记为动态具有挑战性,需要大量的实验并且证明非常复杂。
在此过程中,我们开发了工具和技术来简化 mark_dynamic 的使用,包括在 tlparse 中增强了动态信息日志记录。
例子
- TORCH_COMPILE_DYNAMIC_SOURCES
动态源白名单 (TORCH_COMPILE_DYNAMIC_SOURCES) 的引入,通过提供一种简单友好的方式来标记参数为动态而无需修改底层代码,改善了参数动态形状的处理。此功能还支持将整数标记为动态,并允许使用正则表达式来包含更广泛的参数,从而增强了灵活性并缩短了编译时间。
例子

3. 自动调优配置剪枝
我们发现,应用于基础模型的用户内核和用户定义配置的数量显著影响 PT2 编译。
因为 PT2 自动调优会自动对每个内核的许多可能的运行时配置进行基准测试,以找到最有效的配置,这在有许多内核和配置时可能非常耗时。
为了解决这个问题,我们开发了一个流程来识别最耗时的内核,并确定最佳的运行时配置以在代码库中实现。这种方法显著减少了编译时间。
4. 提高缓存命中率
配置文件引导优化 (PGO) 会破坏缓存,导致非确定性缓存键,从而导致缓存未命中并导致编译时间过长。
无 PGO

有 PGO

为解决此问题,团队实现了哈希函数以生成一致的符号 ID 以进行稳定分配,并使用线性探测以避免符号冲突 (详情)。
这一改变显著提高了作业内部暖运行和使用远程缓存的不同作业的缓存命中率。
5. 优化内核启动
常规 Triton 内核由于需要在编译时进行 C++ 代码生成而具有较高的启动成本,并且在广告模型上的缓存命中率较低。StaticCudaLauncher 是 PyTorch 用于 Triton 生成的 CUDA 内核的新启动器,我们将其用作所有 Triton 内核的默认启动器。这使得冷启动和热启动的编译时间都更快。
6. 巨型缓存
MegaCache 将多种 PT2 编译缓存类型整合在一起——包括 Inductor(核心 PT2 编译器)、Triton bundler(用于 GPU 代码)、AOT Autograd(用于高效梯度计算)、Dynamo PGO(配置文件引导优化)和自动调优设置等组件——形成一个可以轻松下载和共享的单一存档。
通过整合这些元素,MegaCache 提供了以下改进:
- 最大程度地减少对远程服务器的重复请求
- 缩短模型设置时间
- 提高启动和重试作业的可靠性,即使在分布式或云环境中也是如此
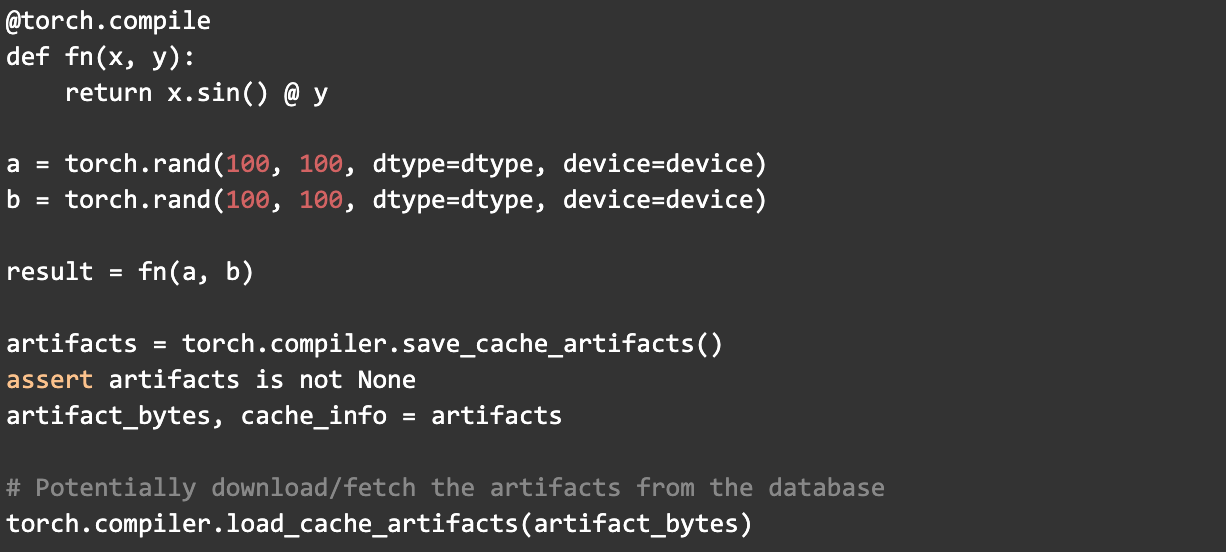
Mega-Cache 提供两个编译器 API
- torch.compiler.save_cache_artifacts()
- torch.compiler.load_cache_artifacts()
以此为例
成果与影响:编译速度提高 80% 以上
得益于我们的优化工作,我们最大的基础模型之一在离线训练期间的编译时间在过去一年中减少了 80% 以上,从大约 3000 秒缩短到不到 500 秒。
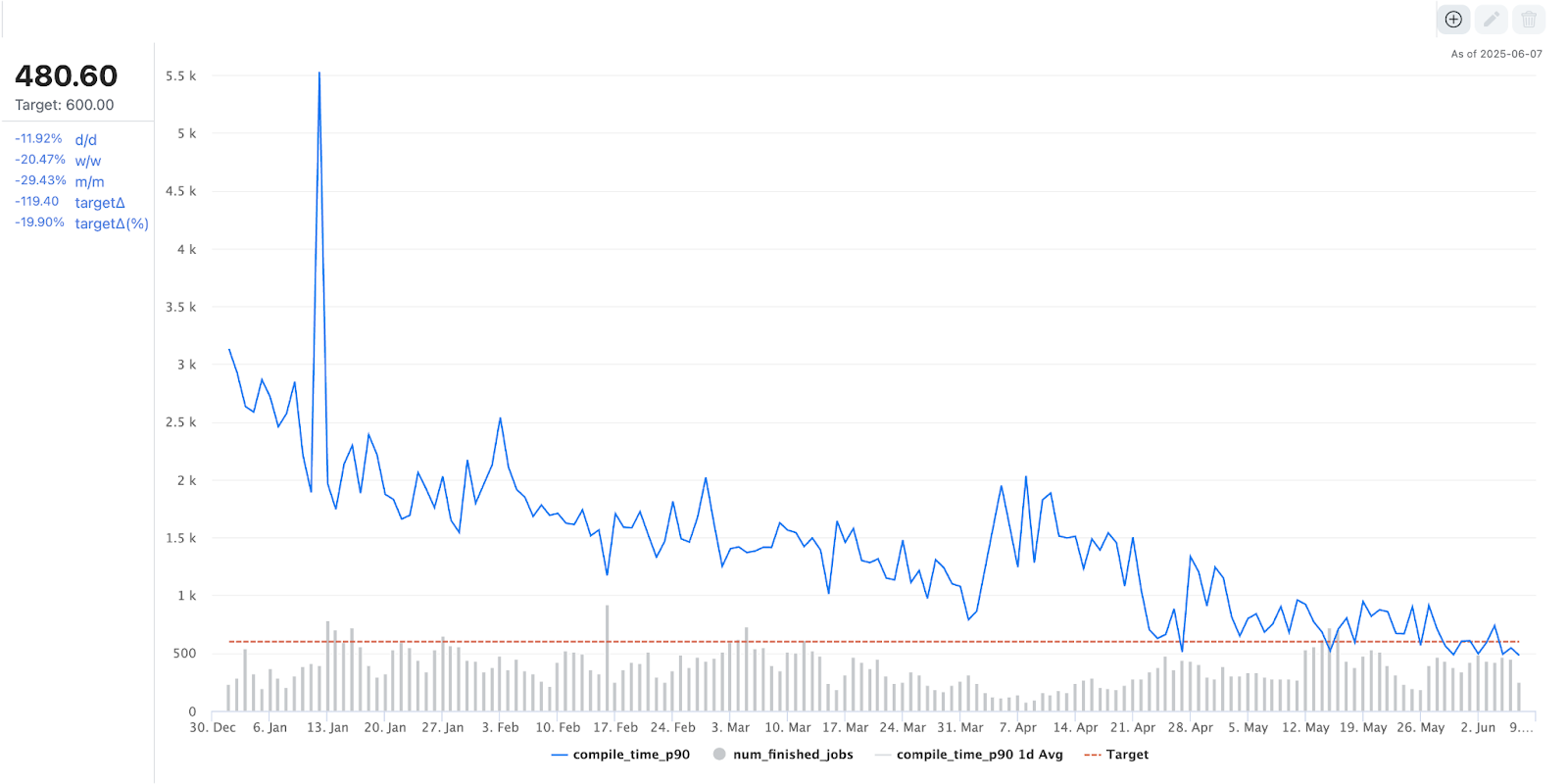
图 4. PT2 编译时间趋势
结语
我们已将这些优化集成到 PT2 编译器堆栈中,使其成为所有使用 PT2 编译模型用户的默认设置。我们通用的转换方法旨在使 Meta 生态系统之外的各种模型受益,我们欢迎在现有工作的基础上进行持续讨论和改进。
致谢
非常感谢Max Leung、Musharaf Sultan、John Bocharov 和 Gregory Chanan 提供富有洞察力的支持和评审。