引言和背景
Opacus 凭借其最新的增强功能,在支持大型模型私有训练方面取得了显著进展。最近,我们引入了快速梯度裁剪 (FGC) 和幽灵裁剪 (GC),使开发人员和研究人员无需实例化每样本梯度即可执行梯度裁剪。与依赖钩子的原生 Opacus 实现相比,这些方法减少了 DP-SGD 的内存占用。
即使有了这些进步,训练大型模型(例如大型语言模型 (LLM))对 Opacus 来说仍然是一个重大挑战。随着对大型模型私有训练的需求持续增长,Opacus 支持数据并行和模型并行技术至关重要。目前,Opacus 支持差分隐私分布式数据并行 (DPDDP) 以实现多 GPU 训练。虽然 DPDDP 有效地跨多个 GPU 和节点扩展模型训练,但它要求每个 GPU 存储一份模型和优化器状态副本,从而导致高内存需求,特别是对于大型模型。
这种限制强调了对替代并行化技术的需求,例如完全分片数据并行 (FSDP),它可以通过模型、梯度和优化器状态分片来提高内存效率并增加可扩展性。在训练 Llama 或其他大型语言模型的背景下,通常会根据模型大小采用不同的并行化策略来扩展训练。
- 1D 并行:对于小型模型(<10 亿参数),使用 DDP 或 FSDP。
- 2D 并行:对于中型模型(10-100 亿参数),FSDP 结合张量并行 (TP)。
- 4D 并行:对于大型模型(>100 亿参数),FSDP 结合 TP、流水线并行 (PP) 和上下文并行 (CP)。
通过采用 FSDP(示例),Opacus 正在增强其能力,以促进 LLM 更高效和可扩展的私有训练或微调。这一发展标志着在满足机器学习社区不断变化的需求方面迈出了充满希望的一步,为 2D 和 4D 并行等高级并行化策略支持中大型模型的私有训练铺平了道路。
FSDP 结合 FGC 和 GC
完全分片数据并行 (FSDP) 是一种强大的数据并行技术,通过有效管理多个 GPU 工作器之间的内存使用,可以训练更大的模型。FSDP 允许在工作器之间对模型参数、梯度和优化器状态进行分片,这显著减少了训练所需的内存占用。尽管这种方法会由于训练期间的参数收集和丢弃而产生额外的通信开销,但通常可以通过将其与计算重叠来减轻成本。
在 FSDP 中,即使每个微批次数据的计算仍然是每个 GPU 工作器的本地计算,但一次为一个块(例如,一个层)收集完整的参数,从而降低内存占用。一旦一个块被处理,每个 GPU 工作器会丢弃从其他工作器收集的参数分片,只保留其本地分片。因此,峰值内存使用量由每层的参数+梯度+优化器状态的最大大小以及激活的总大小决定,这取决于每个设备的批处理大小。有关 FSDP 的更多详细信息,请参阅 PyTorch FSDP 论文。
FSDP 结合 FGC 或 GC 的流程如下:
- 前向传播
- 对于层中的每个层
- [FSDP 钩子] 收集层的完整参数
- 层的前向传播
- [FSDP 钩子] 丢弃层的完整参数
- [Opacus 钩子] 存储层的激活
- 对于层中的每个层
- 重置 optimizer.zero_grad()
- 第一次反向传播
- 对于层中的每个层
- [FSDP 钩子] 收集层的完整参数
- 层的反向传播
- [Opacus 钩子] 使用 FGC 或 GC 计算每样本梯度范数
- [FSDP 钩子] 丢弃层的完整参数
- [FSDP 钩子] reduce_scatter 层的梯度 → 不必要
- 对于层中的每个层
- 使用每样本梯度范数重新缩放损失函数
- 重置 optimizer.zero_grad()
- 第二次反向传播
- 对于层中的每个层
- [FSDP 钩子] 收集层的完整参数
- 层的反向传播
- [FSDP 钩子] 丢弃层的完整参数
- [FSDP 钩子] reduce_scatter 层的梯度
- 对于层中的每个层
- 在每个设备上为其对应的参数分片添加噪声
- 在每个设备上为其对应的参数分片应用优化器步骤
 图 1:基于 FSDP 的 Opacus 中快速梯度裁剪或幽灵裁剪的工作流程。请注意计算和通信之间存在重叠 – 1) 在前向传播中:当前层 (l) 的计算与下一层 (l+1) 参数的 all_gather 重叠。2) 在反向传播中:当前层 (l) 的梯度计算与上一层 (l+1) 梯度的 reduce_scatter 和下一层 (l-1) 参数的 all_gather 重叠。
图 1:基于 FSDP 的 Opacus 中快速梯度裁剪或幽灵裁剪的工作流程。请注意计算和通信之间存在重叠 – 1) 在前向传播中:当前层 (l) 的计算与下一层 (l+1) 参数的 all_gather 重叠。2) 在反向传播中:当前层 (l) 的梯度计算与上一层 (l+1) 梯度的 reduce_scatter 和下一层 (l-1) 参数的 all_gather 重叠。
如何在 Opacus 中使用 FSDP
训练循环与标准 PyTorch 循环相同。与以前的 Opacus 一样,我们使用
PrivacyEngine(),它配置模型和优化器以运行 DP-SGD。- 要启用 FSDP 的幽灵裁剪,请使用参数
grad_sample_mode="ghost_fsdp"。 - 此外,在初始化优化器并调用
make_private()之前,我们使用 FSDP2Wrapper 封装模型。
FSDP2Wrapper 将 FSDP2(FSDP 的第二个版本)应用于根模块以及每个不需要 functorch 来计算每样本梯度范数的 torch.nn 层。依赖 functorch 的层类型不会单独使用 FSDP2 封装,因此会落入根模块的通信组中。连接到根模块通信组的层将首先被取消分片(在前向/反向传播开始时),最后被重新分片(在整个前向/反向传播之后)。这将影响峰值内存,因为连接到根模块的层不会在该层执行后立即重新分片。
我们在实现中使用 FSDP2,因为以前的版本 (FSDP) 与幽灵裁剪的两次反向传播设置不兼容。
from opacus import PrivacyEngine
from opacus.utils.fsdp_utils import FSDP2Wrapper
def launch(rank, world_size):
torch.cuda.set_device(rank)
setup_distributed_env(rank, world_size)
criterion = nn.CrossEntropyLoss() # example loss function
model = ToyModel()
model = FSDP2Wrapper(model) # different from DPDDP wrapper
optimizer = optim.SGD(model.parameters(), lr=args.lr)
privacy_engine = PrivacyEngine()
model_gc, optimizer_gc, criterion_gc, train_loader, = privacy_engine.make_private(
module=model,
optimizer=optimizer,
data_loader=train_loader,
noise_multiplier=noise_multiplier
max_grad_norm=max_grad_norm,
criterion=criterion,
grad_sample_mode="ghost_fsdp",)
# The training loop below is identical to that of PyTorch
for input_data, target_data in train_loader:
input_data, target_data = input_data.to(rank), target_data.to(rank)
output_gc = model_gc(input_data) # Forward pass
optimizer_gc.zero_grad()
loss = criterion_gc(output_gc, target_data)
loss.backward()
optimizer_gc.step() # Add noise and update the model
world_size = torch.cuda.device_count()
mp.spawn(
launch,
args=(world_size,),
nprocs=world_size,
join=True,
)内存分析
我们提供了 GPT2 系列模型完全微调的内存消耗结果。我们只训练 Transformer 块;嵌入层(token 嵌入层、位置嵌入层)被冻结。
图 2 报告了使用幽灵裁剪方法训练模型时 FSDP2 与 DPDDP 支持的最大批处理大小。对于 1.5B 参数的 GPT2 模型,在 1x8 A100 40GB GPU 上使用 FSDP2,我们可以实现比 DPDDP 大 2.6 倍的批处理大小。对于大型模型 (>1B),FSDP2 显示出显著改进,其中参数和优化器状态的大小占据主导地位。

图 2:在 1x8 A100 40GB GPU 节点上,使用基于幽灵裁剪的 DP-SGD 训练一系列 GPT2 模型时的最大批处理大小。我们使用莎士比亚数据集,最大序列长度为 1024,并使用 float32 AdamW 优化器。
表 1 显示了给定步骤的峰值内存和步骤执行后占用的总内存。值得注意的是,模型初始化后 FSDP2 的总内存比 DPDDP 低 8 倍,因为 FSDP2 将模型分片到 8 个 GPU。FSDP2 和 DPDDP 的前向传播都大约增加了 ~10GB 的峰值内存,因为在这两种并行类型中激活都没有分片。对于反向传播和优化器步骤,DPDDP 的峰值内存与模型大小成正比,而 FSDP2 的峰值内存与模型大小除以工作器数量成正比。通常,随着模型大小的增加,FSDP2 的优势变得更加明显。
表 1:在 1x8 A100 40GB GPU 节点上,使用基于幽灵裁剪的 DP-SGD(AdamW 优化器,iso 批处理大小为 16)训练 GPT2-xl 模型 (1.5B) 时,排名 0 的内存估计。峰值内存表示步骤期间分配的最大内存,总内存是执行给定步骤后占用的内存量。
| DPDDP | FSDP2 | |||
| 峰值内存 (GB) | 总内存 (GB) | 峰值内存 (GB) | 总内存 (GB) | |
| 模型初始化 | 5.93 | 5.93 | 1.08 | 0.78 |
| 前向传播 | 16.17 | 16.13 | 11.31 | 10.98 |
| GC 反向传播 | 22.40 | 11.83 | 12.45 | 1.88 |
| 优化器步骤 | 34.15 | 28.53 | 3.98 | 3.29 |
| 优化器零梯度 | 28.53 | 17.54 | 3.29 | 2.59 |
延迟分析
表 2 显示了使用 DP-DDP 和 FSDP2 对 Llama-3 8B 模型进行 LoRA 微调的最大批处理大小和延迟数字。我们观察到,对于使用幽灵裁剪的 DP-SGD,FSDP2 支持的批处理大小几乎是 DP-DDP 的两倍,但对于相同的有效批处理大小,吞吐量 (0.6x) 较低,而 DP-DDP 则使用钩子。在这种特定设置下,使用 LoRA 微调时,FSDP2 不会带来任何显著改进。但是,如果数据集的样本序列长度为 4096,而 DP-DDP 无法容纳,则 FSDP2 变得必不可少。
表 2a:Llama-3 8B (可训练参数:6.8M) 在 Tiny Shakespeare 数据集上进行 LoRA 微调,AdamW 优化器,32 位精度,最大序列长度 512,1x8 A100 80GB GPU。此处,我们不使用任何梯度累积。
| 训练方法 | 并行化 | 每个设备的最大批处理大小 | 总批处理大小 | 每秒 token 数 | 每秒样本数 |
|---|---|---|---|---|---|
| SGD
(非私有) |
DP-DDP | 4 | 32 | 18,311 ± 20 | 35.76 ± 0.04 |
| FSDP2 | 4 | 32 | 13,158 ± 498 | 25.70 ± 0.97 | |
| 8 | 64 | 16,905 ± 317 | 33.02 ± 0.62 | ||
| 带钩子的 DP-SGD | DP-DDP | 4 | 32 | 17,530 ± 166 | 34.24 ± 0.32 |
| 带幽灵裁剪的 DP-SGD | DP-DDP | 4 | 32 | 11,602 ± 222 | 22.66 ± 0.43 |
|
FSDP2 |
4 | 32 | 8,888 ± 127 | 17.36 ± 0.25 | |
| 8 | 64 | 10,847 ± 187 | 21.19 ± 0.37 |
表 2b:Llama-3 8B (可训练参数:6.8M) 在 Tiny Shakespeare 数据集上进行 LoRA 微调,AdamW 优化器,32 位精度,最大序列长度 512,1x8 A100 80GB GPU。此处,我们启用梯度累积以将总批处理大小增加到 256。
| 训练方法 | 并行化 | 每个设备的最大批处理大小 | 梯度累积步数 | 总批处理大小 | 每秒 token 数 | 每秒样本数 |
|---|---|---|---|---|---|---|
| 带钩子的 DP-SGD | DP-DDP | 4 | 8 | 256 | 17,850 ± 61 | 34.86 ± 0.12 |
| 带幽灵裁剪的 DP-SGD | DP-DDP | 4 | 8 | 256 | 12,043 ± 39 | 23.52 ± 0.08 |
| FSDP2 | 8 | 4 | 256 | 10,979 ± 103 | 21.44 ± 0.20 |
表 3 显示了 Llama-3 8B 完全微调的吞吐量数字。目前,带有幽灵裁剪的 FSDP2 不支持绑定的参数(嵌入层)。我们在微调期间冻结这些层,这将可训练参数从 8B 减少到 7.5B。如表 3 所示,即使每个设备的批处理大小为 1,DP-DDP 也会抛出 OOM 错误。而使用 FSDP2,每个设备可以适应批处理大小为 8,从而实现 Llama-3 8B 的完全微调。
为了比较 FSDP2 与 DP-DDP 的完全微调,我们将 AdamW 优化器更改为 SGD(无动量),并通过冻结归一化层和门投影层的权重将可训练参数从 7.5B 减少到 5.1B。这使得 DP-DDP 可以以 2 的批处理大小运行(如果启用梯度累积则为 1)。在此设置下,我们观察到在 iso 批处理大小下,FSDP2 比 DP-DDP 快 1.65 倍。
表 3:Llama-3 8B 在 Tiny Shakespeare 数据集上进行幽灵裁剪 DP-SGD 完全微调,最大序列长度 512,1x8 A100 80GB GPU。
| 设置 | 并行化 | 每个设备的最大批处理大小 | 梯度累积步数 | 总批处理大小 | 每秒 token 数 | 每秒样本数 |
| 可训练参数:7.5B 优化器:AdamW |
DP-DDP | 1 | 1 | 8 | OOM | OOM |
| FSDP2 | 8 | 1 | 64 | 6,442 ± 68 | 12.58 ± 0.13 | |
| 可训练参数:5.1B 优化器:SGD |
DP-DDP | 2 | 1 | 16 | 5,173 ± 266 | 10.10 ± 0.52 |
| FSDP2 | 2 | 1 | 16 | 4,230 ± 150 | 8.26 ± 0.29 | |
| DP-DDP | 2 | 4 | 64 | OOM | OOM | |
| 1 | 8 | 64 | 4,762 ± 221 | 9.30 ± 0.43 | ||
| FSDP2 | 8 | 1 | 64 | 7,872 ± 59 | 15.37 ± 0.12 |
正确性验证
我们对带有 FSDP 的幽灵裁剪 DP-SGD 在 Meta 内部用例上进行了集成测试,该用例包括一个 Llama-3 8B 模型,并使用 LoRA 微调进行下一个单词预测任务。我们的结果表明,带有 FSDP 的幽灵裁剪与 DP-DDP 的训练损失大致相同(可忽略不计的差异)。之前的结果以及单元测试(链接)已证明了实现的正确性。
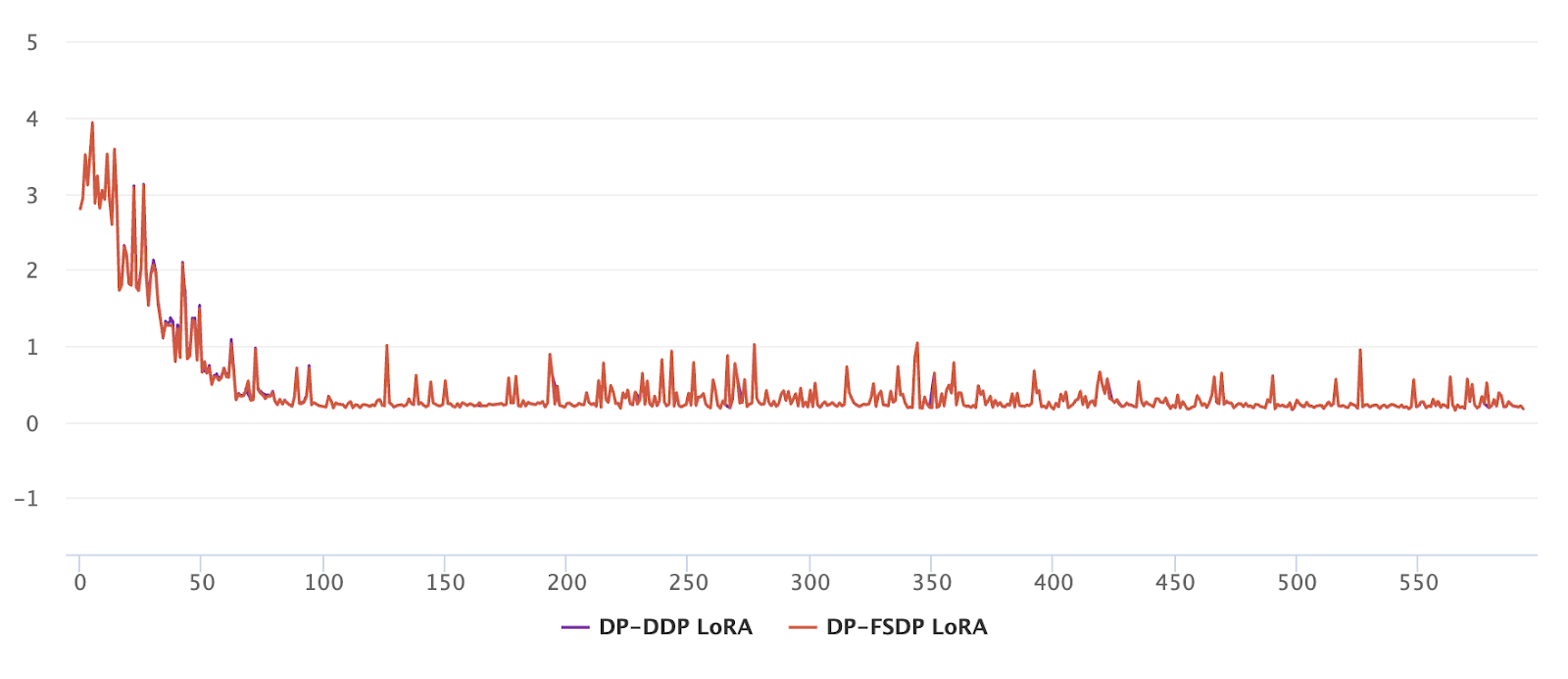
图 3:Llama-3 8B 使用幽灵裁剪 DP-SGD 进行下一个单词预测任务的 LoRA 微调的训练损失(y 轴)与迭代次数(x 轴)。
局限性
当前版本的 FSDP 不支持以下场景:
- 具有绑定参数的层。
- 在训练阶段冻结/解冻可训练参数。
以下是当前 FSDP2 幽灵裁剪梯度累积实现的两个主要限制。
-
- 延迟
- 当前 FSDP2 梯度累积的实现会在每次反向传播后同步梯度。由于幽灵裁剪有两次反向传播,对于 k 个梯度累积步骤,我们有 2k 次梯度同步调用 (reduce_scatter)。
- 这是因为当每次前向传播有两次反向传播时,不能直接使用 no_sync。
- 理想情况下,对于 k 个梯度累积步骤,我们应该只有 1 次梯度同步调用。
- 在 LoRA 微调的情况下,reduce_scatter 的延迟可以忽略不计。此外,通过合理的计算/通信重叠,这种开销可以被掩盖。
- 延迟
- 内存
-
- 梯度累积使用一个额外的缓冲区来存储累积的梯度(分片),无论梯度累积步数是多少。
- 当梯度累积步数为 1 时,我们希望避免使用额外的缓冲区。这并非 FSDP2 特有,而是 Opacus 库的普遍瓶颈。
主要收获
- 对于可训练参数较小的模型,例如 LoRA 微调
- 建议尽可能使用带梯度累积的 DP-DDP。
- 如果 DP-DDP 因所需的序列长度或模型大小而抛出 OOM 错误,则切换到 FSDP2。
- 对于具有相当多可训练参数的完全微调
- 建议使用 FSDP2,因为它比 DP-DDP 具有更高的吞吐量
- 在大多数情况下,FSDP2 是唯一的选择,因为即使批处理大小为 1,DP-DDP 也会触发 OOM。
- 上述观察结果适用于私有和非私有情况。
结论
在这篇文章中,我们介绍了 Opacus 中完全分片数据并行 (FSDP) 与快速梯度裁剪 (FGC) 和幽灵裁剪 (GC) 的集成,展示了它扩展具有超过 10 亿可训练参数的大型模型私有训练的潜力。通过利用 FSDP,我们证明了可以完全微调 Llama-3 8B 模型,这是由于内存限制而无法通过差分隐私分布式数据并行 (DP-DDP) 实现的壮举。
Opacus 中 FSDP 的引入标志着 Opacus 库的重大进步,为 LLM 的私有训练提供了可扩展且内存高效的解决方案。这一发展不仅增强了 Opacus 处理大型模型的能力,而且为未来集成其他模型并行化策略奠定了基础。
展望未来,我们的重点将是启用带有幽灵裁剪的 2D 并行,并将 FSDP 与使用钩子的原生 Opacus 集成。这些努力旨在进一步优化训练过程,减少延迟,并将 Opacus 的适用性扩展到更大、更复杂的模型。我们对这些进步将解锁的可能性感到兴奋,并致力于突破私有机器学习的界限。此外,我们邀请开发人员、研究人员和爱好者加入我们,共同踏上这段旅程。您的贡献和见解在我们继续增强 Opacus 的过程中是无价的。