概述
近年来,AI 模型的日益复杂对硬件提出了越来越高的计算能力要求。为了解决这个问题,人们提出了降低精度数字格式。Bfloat16 是一种自定义的 16 位浮点格式,专为 AI 设计,包含一个符号位、八个指数位和七个尾数位。Bfloat16 具有与 float32 相同的动态范围,因此无需特殊的处理,例如损失缩放。因此,在运行深度神经网络进行推理和训练时,bfloat16 可以直接替代 float32。
第三代英特尔® 至强® 可扩展处理器(代号 Cooper Lake)是首款原生支持 bfloat16 的通用 x86 CPU。英特尔® 高级矢量扩展-512 (Intel® AVX-512) 中引入了三个新的 bfloat16 指令:VCVTNE2PS2BF16、VCVTNEPS2BF16 和 VDPBF16PS。前两个指令执行从 float32 到 bfloat16 的转换,最后一个指令执行 bfloat16 对的点积。在 Cooper Lake 上,bfloat16 的理论计算吞吐量是 float32 的两倍。在下一代英特尔® 至强® 可扩展处理器上,bfloat16 的计算吞吐量将通过高级矩阵扩展 (Intel® AMX) 指令集扩展得到进一步提升。
英特尔和 Meta 此前曾合作在 PyTorch 上启用 bfloat16,相关工作在 Cooper Lake 发布时的一篇博客中发表。在该博客中,我们介绍了原生 bfloat16 支持的硬件进步,并展示了 DLRM、ResNet-50 和 ResNext-101-32x4d 中 bfloat16 相较于 float32 性能提升 1.4 倍至 1.6 倍。
在这篇博客中,我们将介绍 PyTorch 1.12 中 bfloat16 的最新软件增强功能,它将适用于更广泛的用户场景,并展示更高的性能提升。
Bfloat16 的原生级优化
在 PyTorch CPU bfloat16 路径上,计算密集型操作符(例如卷积、线性运算和 BMM)使用 oneDNN (oneAPI 深度神经网络库) 在支持 AVX512_BF16 或 AMX 的英特尔 CPU 上实现最佳性能。其他操作符,例如张量操作符和神经网络操作符,在 PyTorch 原生级别进行了优化。我们已将 bfloat16 内核级优化扩展到大多数密集张量操作符,适用于推理和训练(稀疏张量 bfloat16 支持将在未来工作中涵盖),具体包括:
- Bfloat16 矢量化:Bfloat16 以无符号 16 位整数存储,需要将其转换为 float32 才能进行加、乘等算术运算。具体来说,每个 bfloat16 矢量将被转换为两个 float32 矢量,进行相应的处理,然后再转换回来。而对于非算术运算,例如 cat、copy 等,它只是简单的内存复制,不涉及数据类型转换。
- Bfloat16 规约:对 bfloat16 数据进行规约时,使用 float32 作为累加类型以保证数值稳定性,例如求和、BatchNorm2d、MaxPool2d 等。
- Channels Last 优化:对于视觉模型,从性能角度来看,Channels Last 是比 Channels First 更可取的内存格式。我们为 Channels Last 内存格式上的所有常用 CV 模块实现了完全优化的 CPU 内核,同时兼顾了 float32 和 bfloat16。
使用自动混合精度运行 Bfloat16
要在 bfloat16 上运行模型,用户通常可以显式地将数据和模型转换为 bfloat16,例如:
# with explicit conversion
input = input.to(dtype=torch.bfloat16)
model = model.to(dtype=torch.bfloat16)
或利用 torch.amp (Automatic Mixed Precision) 包。autocast 实例作为上下文管理器或装饰器,允许脚本的某些区域以混合精度运行,例如:
# with AMP
with torch.autocast(device_type="cpu", dtype=torch.bfloat16):
output = model(input)
通常,显式转换方法和 AMP 方法具有相似的性能。尽管如此,我们建议使用 AMP 运行 bfloat16 模型,因为:
- 自动回退带来更好的用户体验:如果您的脚本包含不支持 bfloat16 的运算符,autocast 会隐式地将其转换回 float32,而显式转换的模型会给出运行时错误。
- 激活和参数的混合数据类型:与将所有模型参数转换为 bfloat16 的显式转换不同,AMP 模式将以混合数据类型运行。具体来说,输入/输出将保留为 bfloat16,而参数(例如权重/偏差)将保留为 float32。激活和参数的混合数据类型将有助于提高性能,同时保持精度。
性能提升
我们使用 Intel® Xeon® Platinum 8380H CPU @ 2.90GHz(代号 Cooper Lake)对 TorchVision 模型的推理性能进行了基准测试,每个插槽单实例(批处理大小 = 2 x 物理核心数)。结果显示,bfloat16 相对于 float32 具有 1.4 倍至 2.2 倍的性能提升。
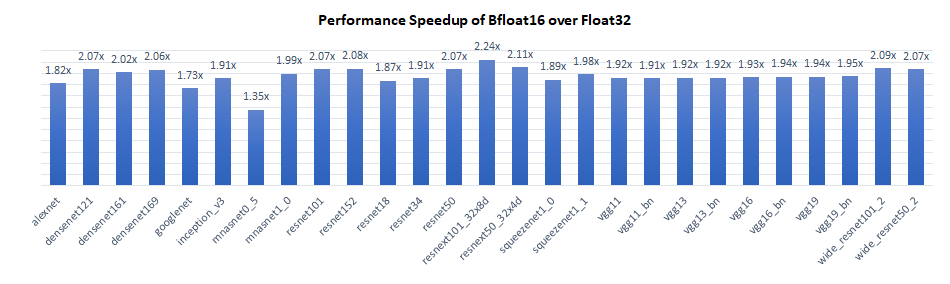
Bfloat16 相较于 float32 的性能提升主要来自三个方面:
- 计算密集型操作符利用了新的 bfloat16 原生指令 VDPBF16PS,使硬件计算吞吐量翻倍。
- Bfloat16 的内存占用仅为 float32 的一半,因此理论上内存带宽密集型操作符的速度将快两倍。
- 在 Channels Last 模式下,我们特意为所有感知内存格式的操作符保持相同的并行化方案(Channels First 模式下无法做到这一点),这增加了每层输出传递到下一层时的数据局部性。基本上,它使数据更接近 CPU 核心,并且数据无论如何都将驻留在缓存中。在这种情况下,由于内存占用较小,bfloat16 的缓存命中率将高于 float32。
结论与未来工作
在这篇博客中,我们介绍了 PyTorch 1.12 中引入的 bfloat16 最新软件优化。在第三代英特尔® 至强® 可扩展处理器上的结果显示,bfloat16 在 TorchVision 模型上比 float32 实现了 1.4 倍到 2.2 倍的性能提升。随着 AMX 指令支持的引入,预计在下一代英特尔® 至强® 可扩展处理器上将实现进一步的改进。尽管本博客的性能数据是使用 TorchVision 模型收集的,但这种优势适用于所有拓扑结构。未来,我们将继续将 bfloat16 优化工作扩展到更广泛的范围!
致谢
本博客中呈现的结果是 Meta 和 Intel PyTorch 团队共同努力的成果。特别感谢 Meta 的 Vitaly Fedyunin 和 Wei Wei,他们付出了宝贵的时间并提供了实质性的帮助!我们共同为改善 PyTorch CPU 生态系统迈出了又一步。