要点速览
NJT(嵌套不规则张量)将 DRAMA 模型的推理效率提升了 1.7 倍-2.3 倍,使其在基于 LLM 的编码器类别中更具生产就绪性,尤其是在处理可变长度序列时。
引言和背景
基于大型语言模型 (LLM) 的编码器最近的进展显示出可喜的成果,许多模型在评估排行榜上名列前茅。然而,挑战在于将这些复杂的模型投入生产,这通常需要大量的计算资源和基础设施。
为了解决优化 LLaMA 编码器的挑战,我们选择探索 DRAMA,这是一种利用裁剪 LLaMA 主干的密集检索模型。DRAMA 模型在各种版本(包括基础版(0.1B)、大型版(0.3B)和 1B 版)中总体表现良好。具体而言,DRAMA-base 以其在英语和多语言检索任务中的出色表现脱颖而出,尽管其尺寸紧凑,只有 0.1B 非嵌入参数。其质量使其成为客户的一个有吸引力的选择。然而,与其实现相关的高成本阻碍了其广泛采用。为了解决这一挑战,我们探索使用嵌套张量进一步优化模型,使其成为生产环境的可行解决方案。
通过利用嵌套张量,我们观察到DRAMA模型的推理效率大幅提高,效率提升了 1.7 到 2.3 倍。这一突破对于在实际应用中部署基于 LLM 的编码器具有重要意义。
什么是 NJT
torchtune 中的样本打包、TensorFlow 中的不规则张量、ModernBert 中的去填充以及Pytorch 中的嵌套张量都解决了可变长度序列数据的挑战,但方法不同。虽然所有方法都旨在简化序列建模,但它们的抽象和性能影响因框架和用例而异。
PyTorch 的嵌套张量是 Python 张量的一个子类,它通过高效的打包内部表示提供了一个统一的接口来处理不规则形状的数据。
PyTorch 中有两种类型的嵌套张量,通过它们的构造布局来区分:`torch.strided` 或 `torch.jagged`。建议使用 Jagged 布局的嵌套张量 (NJT),这也是本博客关注的重点。值得注意的是,由于完全用 Python 实现,NJT 会产生一定的即时开销,在较小的输入尺寸上更为明显。建议在可能的情况下编译 NJT,以消除此开销并从运算符融合中获得性能提升。
NJT 张量可以通过将张量列表传递给 `torch.nested.nested_tensor` 并带有 `layout=torch.jagged` 参数来创建。这将输入复制到打包的、连续的内存块中。NJT 目前支持单个不规则维度。
当模型部署通常对具有不同长度的大批量序列执行推理时,嵌套张量会从中受益。鉴于这种查询模式,使用常规张量进行推理需要批次中的所有序列都填充到相同的长度,当批次由许多短序列和一个长序列组成时,这尤其浪费。相比之下,嵌套张量通过原生支持对不同序列长度的批次进行操作,从而避免在这些额外的填充标记上浪费计算。
密集与不规则
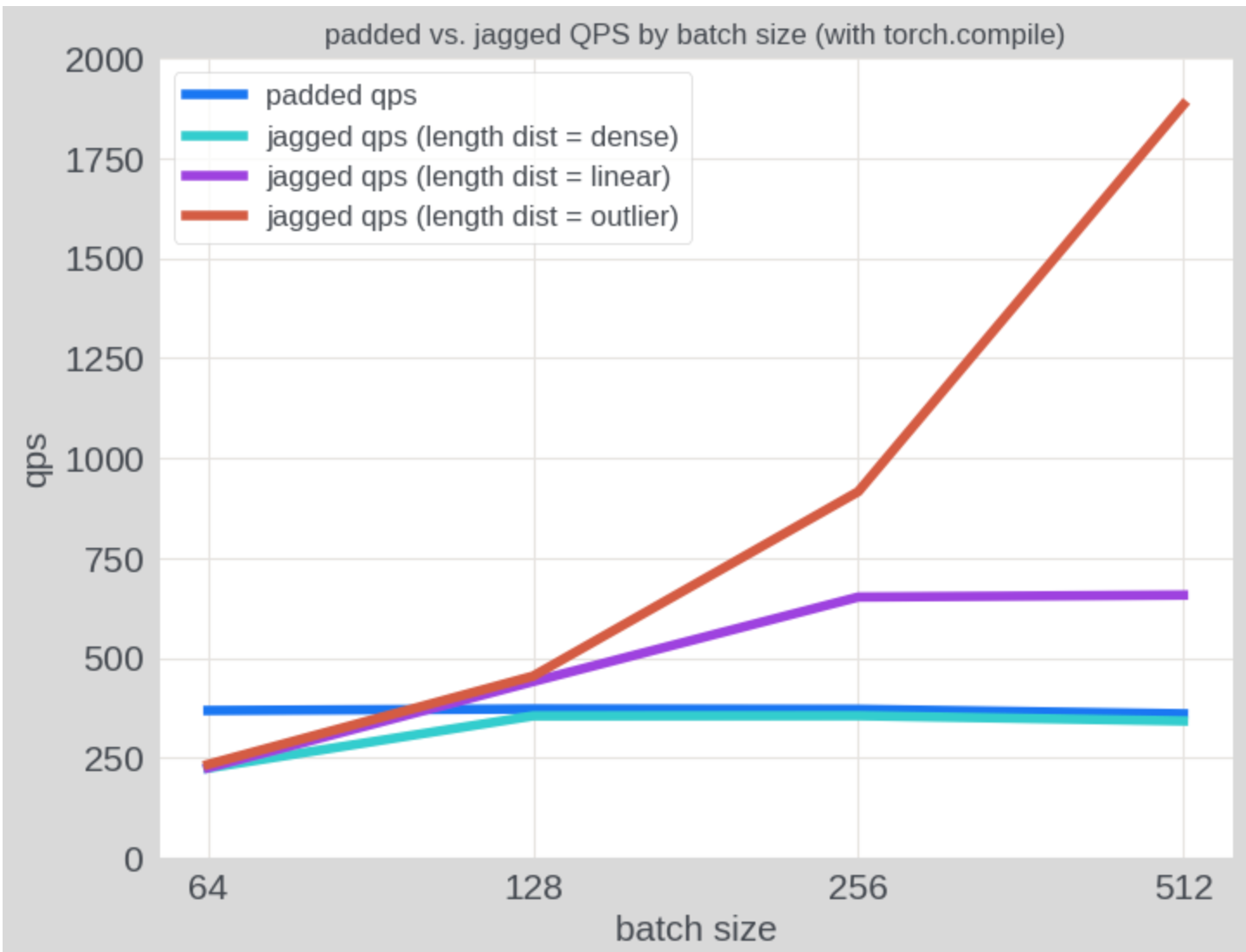
正如预期的那样,与填充张量相比,NJT 在具有不均匀序列长度的输入上表现出显着更高的吞吐量。在下图中,我们使用各种序列长度模式的合成数据评估了 QPS:(1) “密集”批次,其中每个序列的长度为 256;(2) “线性”批次,其中批次中的序列长度从 1 线性增加到 256;以及 (3) “异常值”批次,其中一个序列的长度为 256,其余序列的长度为 1。在使用填充张量时,所有三种情况的推理成本保持不变,而使用 NJT 时,推理成本随着批次稀疏性的增加而降低。在“线性”分布上,NJT 的性能优于填充张量约 1.85 倍。
实现
为了将 NJT 应用于 LLaMa 模型,需要进行以下代码修改。主要集中在两个关键组件:转换和注意力。
转换
将 token id 转换为不规则 token id,并将 attention mask 设置为 none,因为不需要 mask,因为没有填充。
jagged_input_ids = torch.nested.nested_tensor( tokenizer_output.input_ids, layout=torch.jagged ) attention_mask = None
LlamaSdpaAttention
- Llama 3 引入了分组查询注意力 (GQA),其特点是注意力头多于键值头(
num_attention_heads > num_key_value_heads)。为了确保注意力过程中的兼容性,repeat_kv函数发挥了关键作用——其主要任务是有效地在查询头之间复制键值头。此操作将张量从(batch, num_key_value_heads, seqlen, head_dim) 重塑为 (batch, num_attention_heads, seqlen, head_dim)。
为了更好地处理不规则和密集张量格式,原始的repeat_kv函数已分为两个专门的函数:
-
-
-
- repeat_dense_kv:用于密集张量,此函数与原始 repeat_kv 相同。
- repeat_jagged_kv:专为不规则张量设计,带有
ragged_idx索引,增加了复杂性。此方法利用一系列转置和展平操作。通过在展平之前临时更改维度顺序,然后转置回来,它有效地解决了不规则张量带来的独特挑战。
-
-
def repeat_jagged_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """
batch, num_key_value_heads, slen, head_dim = hidden_states.shape expand_shape = (batch, num_key_value_heads, -1, n_rep, head_dim) if n_rep == 1: return hidden_states hidden_states = ( hidden_states.unsqueeze(3) .expand(expand_shape) .transpose(1, 2) .flatten(2, 3) .transpose(1, 2) ) return hidden_states
def repeat_dense_kv(hidden_states: torch.Tensor, n_rep: int) -> torch.Tensor: """ This is the equivalent of torch.repeat_interleave(x, dim=1, repeats=n_rep). The hidden states go from (batch, num_key_value_heads, seqlen, head_dim) to (batch, num_attention_heads, seqlen, head_dim) """ batch, num_key_value_heads, slen, head_dim = hidden_states.shape if n_rep == 1: return hidden_states hidden_states = hidden_states[:, :, None, :, :].expand( batch, num_key_value_heads, n_rep, slen, head_dim ) return hidden_states.reshape(batch, num_key_value_heads * n_rep, slen, head_dim)
2. 当将旋转位置嵌入 (RoPE) 应用于查询和键张量时,我们需要处理两种不同的张量格式:不规则和密集。为了适应这一点,我们实现了两个独立的函数,每个函数都针对特定的张量类型量身定制。主函数apply_rotary_pos_emb()充当路由器,根据张量是否嵌套将输入定向到_jagged_tensor_forward或
_dense_tensor_forward
对于不规则张量,该过程涉及三个关键步骤:首先,使用q.to_padded_tensor(0.0)将不规则张量转换为密集张量;其次,在此密集表示上应用旋转位置嵌入;最后,使用
_dense_to_jagged
def apply_rotary_pos_emb( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, unsqueeze_dim: int = 1, ) -> Tuple[torch.Tensor, torch.Tensor]: cos = cos.unsqueeze(unsqueeze_dim) sin = sin.unsqueeze(unsqueeze_dim) if q.is_nested and k.is_nested: if q.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {q.layout}") if k.layout != torch.jagged: raise NotImplementedError(f"Unsupported layout: {k.layout}") return _jagged_tensor_forward(q, k, cos, sin) else: return _dense_tensor_forward(q, k, cos, sin)
def _jagged_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_dense = q.to_padded_tensor(0.0) k_dense = k.to_padded_tensor(0.0) q_dense_embed = (q_dense * cos) + (rotate_half(q_dense) * sin) k_dense_embed = (k_dense * cos) + (rotate_half(k_dense) * sin) q_jagged_embed = convert_dense_to_jagged(q, q_dense_embed) k_jagged_embed = convert_dense_to_jagged(k, k_dense_embed) return q_jagged_embed, k_jagged_embed def _dense_tensor_forward( q: torch.Tensor, k: torch.Tensor, cos: torch.Tensor, sin: torch.Tensor, ) -> Tuple[torch.Tensor, torch.Tensor]: q_embed = (q * cos) + (rotate_half(q) * sin) k_embed = (k * cos) + (rotate_half(k) * sin) return q_embed, k_embed def convert_dense_to_jagged(nested_q: torch.Tensor, q: torch.Tensor) -> torch.Tensor: padded_max_S = nested_q._get_max_seqlen()
total_L = nested_q._values.shape[nested_q._ragged_idx - 1] if padded_max_S is None: # use upper bound on max seqlen if it's not present padded_max_S = total_L # convert dense tensor -> jagged q = q.expand( [ x if i != nested_q._ragged_idx else padded_max_S for i, x in enumerate(q.shape) ] ) nested_result = nested_from_padded( q, offsets=nested_q._offsets, ragged_idx=nested_q._ragged_idx, sum_S=total_L, min_seqlen=nested_q._get_min_seqlen(), max_seqlen=padded_max_S, ) return nested_result
增加了带有 NJT 的 Drama 模型实现:modeling_drama_nested.py
致谢
我们感谢 Xilun Chen 在代码审查中提供的有益反馈。并感谢 Don Husa、Jeffrey Wan、Joel Schlosser 和 Fernando Hernandez 对博客的有益反馈。
结论
使用 NJT 的这项优化显著提高了 DRAMA(基于 LLaMa 的编码器)的效率,使其在实际部署中更具实用性。通过减少计算开销,尤其是对于可变长度序列,这种方法为高性能基于 LLM 的编码器在生产环境中的广泛采用铺平了道路。然而,NJT 在 PyTorch 中已是功能完备,目前没有积极添加新功能,但欢迎社区贡献。