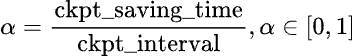随着训练作业规模的扩大,抢占、崩溃或基础设施不稳定等故障的可能性也随之增加。这可能导致训练效率低下,并延迟上市时间。在如此大的规模下,高效的分布式检查点至关重要,它能减轻故障的负面影响,并优化整体训练效率(训练吞吐量)。
训练不良吞吐量 (Training badput) 是指作业总持续时间中训练未取得进展的百分比。我们可以使用中断平均时间 (MTBI) 而不是总持续时间来计算训练不良吞吐量,这样推导适用于任何训练持续时间。要计算检查点不良吞吐量的百分比,我们将在 MTBI 间隔内因检查点而损失的训练时间除以 MTBI,以确定检查点不良吞吐量的百分比。下面我们将正式定义检查点不良吞吐量及其影响因素:

图1:检查点不良吞吐量的正式定义
上述公式分解为三个组成部分
- 加载:从中断中恢复时从存储加载检查点所需的时间
- 保存开销:保存检查点对训练造成的开销
- 计算损失:从最近的检查点恢复时损失的计算时间
最近由 PyTorch DistributedCheckpoint (DCP) 添加的功能,包括基于进程的异步检查点、保存计划缓存和局部检查点等,改善了检查点保存开销,进而缩短了检查点保存时间。检查点不良吞吐量的进一步最小化取决于检查点间隔。不频繁的检查点会导致检查点之间存在更大的间隔,从而在必须恢复到上一个检查点时增加可能丢失的训练进度量。然而,由于检查点会引入保存开销,因此过于频繁地保存检查点会显著扰乱训练性能。最佳频率可以通过数值计算确定,具体公式请参阅附录。以下是对检查点频率及其对训练不良吞吐量影响的直观理解。
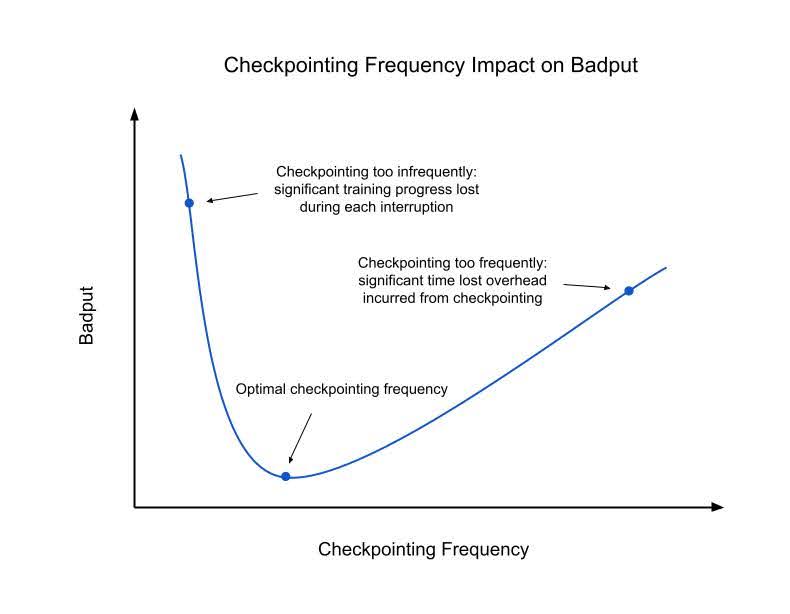
图2:检查点频率对不良吞吐量的影响
过去,训练工作负载依赖持久性存储(例如:NFS、Lustre GCS)进行检查点的写入和读取。在大规模场景下,处理持久性存储会引入额外的延迟,这不幸地限制了检查点保存的速率。Google 和 PyTorch 最近合作开发了一种使用 DCP 的本地检查点解决方案,可以频繁地将检查点保存到本地存储。正如我们稍后将展示的,本地检查点克服了传统设置的限制,并提高了训练吞吐量。
最小化保存开销
在典型的检查点工作流程中,当检查点数据从 GPU 传输到 CPU 再传输到存储时,GPU 会处于空闲状态,只有在数据保存后训练才会恢复。异步检查点通过将数据保存过程卸载到 CPU 线程,显著减少了 GPU 阻塞时间。只有 GPU 卸载步骤仍然是同步的。这允许基于 GPU 的训练同时进行,而检查点数据则上传到存储。它主要用于中间检查点或容错检查点,因为它比同步方法更快地释放 GPU。训练立即恢复,极大地提高了同步检查点上的训练吞吐量。欲了解更多详细信息,请参阅这篇 文章。
GIL 竞争导致 GPU 利用率下降
Python 中的全局解释器锁 (GIL) 是一种机制,它阻止多个原生线程同时执行 Python 字节码。这种锁主要是因为 CPython 的内存管理不是线程安全的,因此是必需的。
DCP 当前使用后台线程进行元数据收集和上传到存储,尽管是异步的,但它与训练器线程争夺 GIL。这显著影响了 GPU 利用率并增加了端到端上传延迟。对于大规模检查点,CPU 并行处理的开销对 GPU 训练速度产生了抑制作用,因为 CPU 也通过 GPU 内核启动来驱动训练过程。
请参阅我们实验中的下图,它展示了基于线程的异步检查点对 GPU 利用率和训练 QPS 的影响。
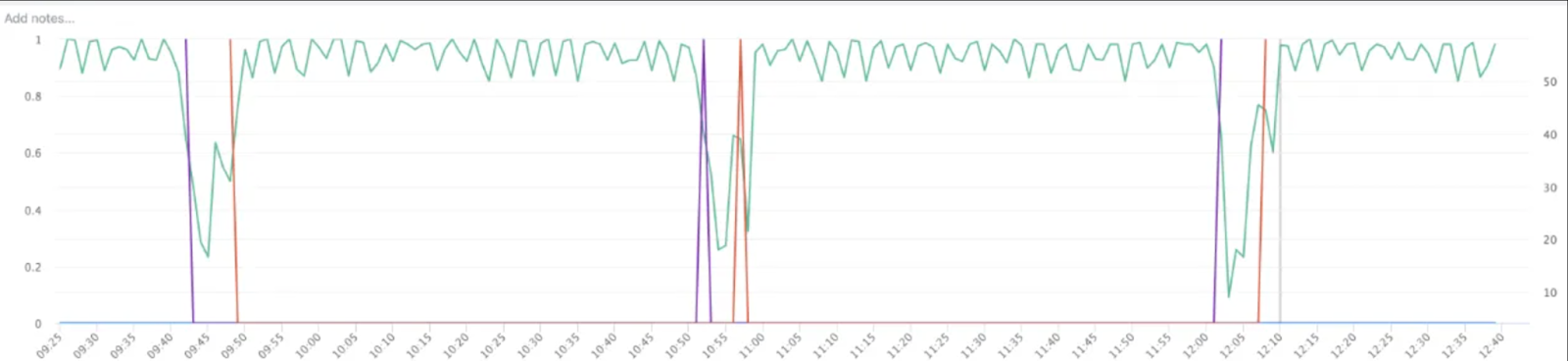
以下是 GIL 竞争导致检查点保存缓慢和训练 QPS 降低的更详细视图
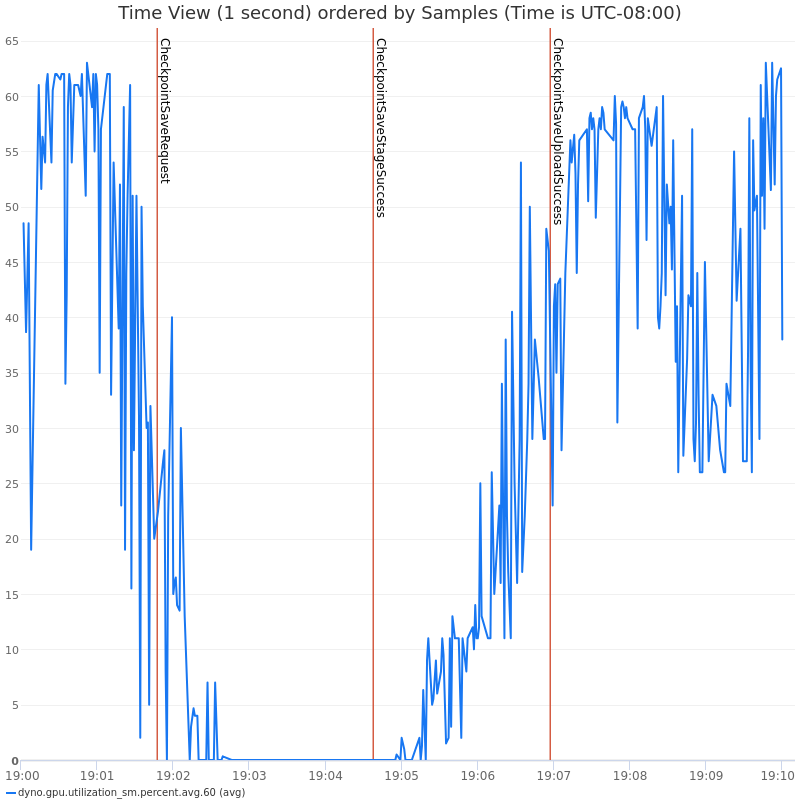
图3和图4:使用线程的异步检查点对 GPU 利用率和训练 QPS 的影响
检查点暂存成本
在异步检查点过程中,GPU 内存会卸载到 CPU 内存,这一步称为暂存。这会引入与内存分配和解除分配相关的开销,包括内存碎片、页面错误和内存同步。通过解决这些开销,可以减少检查点上花费的总阻塞时间,从而提高整体训练吞吐量。

图5:暂存步骤概述
集体通信成本
DCP 出于各种原因(数据去重、检查点的全局元数据、重新分片和分布式异常处理)执行了多个集合操作。集合操作成本高昂,因为它们需要网络 I/O 和大型 Python 对象的序列化/反序列化,这些对象通过 GPU 网络发送。随着作业规模的增加,这些集合操作变得极其昂贵,导致显著更高的端到端延迟和集合操作超时的可能性。
缓存计划
为了容错,作业期间会进行多次检查点。DCP 明确分离了规划和存储 I/O 阶段。在大多数情况下,只有状态字典在检查点保存尝试之间发生变化,而计划保持一致。这允许计划缓存,仅在第一次保存时产生成本,并在后续尝试中分摊。这显著减少了总体开销,因为在同步期间只有更新的计划通过集合操作发送。
缓存元数据
由于集合开销,生成检查点的全局元数据成本很高。为了缓解这个问题,只要计划保持不变,检查点元数据就可以与保存计划一起缓存,并在多次保存尝试中重复使用。
基于进程的检查点
DCP 目前使用后台线程进行元数据收集和上传到存储。尽管这些昂贵的步骤是异步完成的,但它导致与训练器线程争夺 GIL。这导致 GPU 利用率 (QPS) 显著下降,并且也大大增加了端到端上传延迟。图6 如下所示,基于进程的异步检查点如何有效减少与训练器的 GIL 竞争。这与图3和图4 形成对比,其中基于线程的异步检查点由于 GIL 竞争而导致训练速度变慢。
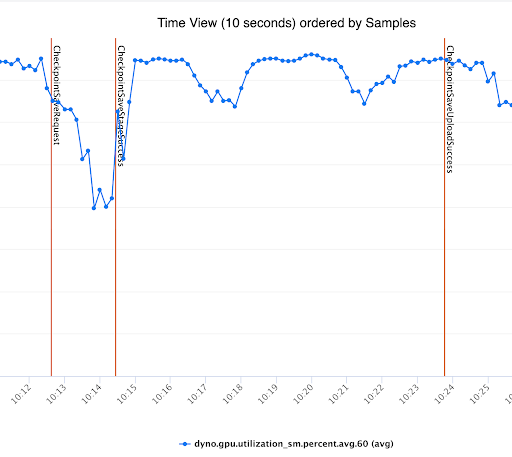
图6:使用基于进程的异步检查点解决 GIL 竞争问题
固定内存暂存
我们的内部实验表明,通过利用固定共享内存张量,可以加快将张量暂存到 CPU 或共享内存的速度,这有可能显著改善异步检查点的阻塞时间。您可以此处和此处阅读更多关于此策略的信息。
基本思想是,由于 GPU 的某些机制,数据默认通过固定(不可分页)内存传输到可分页内存,这可以通过将某些字节地址范围指定为固定来优化,从而允许直接从 GPU 复制到共享内存。通过这种方法,我们看到暂存时间(GPU 阻塞时间)提高了 2 倍,显著有助于提高训练吞吐量,并允许更积极的检查点间隔。
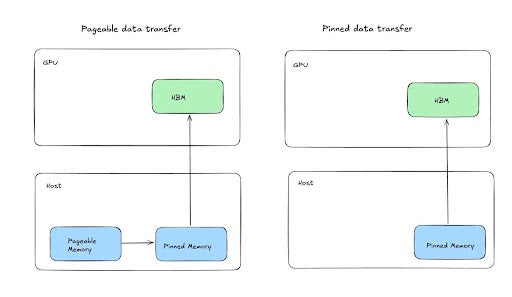
图7:演示固定内存暂存
集群本地检查点
本地检查点是指使用本地存储(SSD、RAMDisk 等)保存和加载检查点,这意味着每个节点都将从其本地存储而不是全局持久化存储中保存和加载。本地检查点的优点显而易见,但由于大规模训练作业中补救措施的复杂性,最佳利用它们可能很困难。
在训练作业中,中断通常发生在单个节点级别。节点可能因各种原因而失败,这可能导致其本地状态对工作负载的其余部分不可访问。为了快速恢复,训练作业通常会预留备用容量,可用作替代。因此,主动训练的节点集是动态的。此主动集的变化需要调整优化的网络拓扑,这可能进一步影响每个节点需要训练的状态。与训练状态始终可用的持久化存储不同,当依赖本地存储时,活动节点集的变化会导致一部分节点缺少所需的训练状态。
为了防止这些情况,工作负载通常会依赖某种形式的状态复制和备份到持久化存储。虽然始终保持一定频率的备份到持久化存储很重要,但本地检查点引入的优势促使人们寻求能够处理状态复制的复杂解决方案。
状态可以通过启用数据并行或在检查点保存期间复制,其中每个节点的状态作为备份与另一个节点共享。在保存时复制状态会引入额外的延迟,因为每个节点都需要保存自己的状态和另一个节点的状态。在检查点加载时,两种方法都需要在节点之间传输状态的功能以及理解需要进行哪些传输的逻辑。
Google 与 PyTorch 合作,最近发布了一个基于 DCP 的本地检查点解决方案。当前的解决方案利用了数据并行性,并在加载期间处理复制逻辑。未来的工作还将实现在保存期间的复制。此本地检查点解决方案可在 Google Cloud 的容错库中找到,并已集成到多个经过吞吐量优化的训练方案中。
检查点优化对吞吐量的影响
让我们利用检查点不良吞吐量的公式,将所有这些优化重新置于训练吞吐量的视角。为了计算不良吞吐量,我们测量了检查点造成的开销、保存检查点的总时间以及加载检查点的时间。以下结果是在 54 台Google Cloud A3Ultra VM(432 块 NVIDIA H200 SXM GPU)上使用 Llama 3 405B 获得的。
| 使用 GCS 作为持久存储的基线异步检查点 | 上一栏 + DCP 计划 + 元数据缓存 | 上一栏 + 基于专用进程的检查点 + 固定内存 | 上一栏 + 本地检查点 | |
| 检查点开销(不包括第一个检查点) | 18.5秒 | 5.5秒 | 1.5秒 | 2.3秒 |
| 保存检查点的总时间(不包括第一个检查点) | 约126秒 | 约135秒 | 约135秒 | 约47秒 |
| 加载检查点的时间 | 94秒 | 94秒 | 94秒 | 80秒 |
结果表明,DCP 优化显著将检查点开销降至接近零。正如预期,本地检查点显著缩短了保存和加载检查点的时间。由于决定排除检查点去重逻辑,本地检查点时的检查点开销略高。这导致每个节点向存储写入更大的文件。未来的工作旨在在使用本地检查点时减少检查点文件大小。
根据上表中的测量结果,我们可以通过附录中的推导来确定最佳检查点频率,并计算检查点造成的总不良吞吐量。
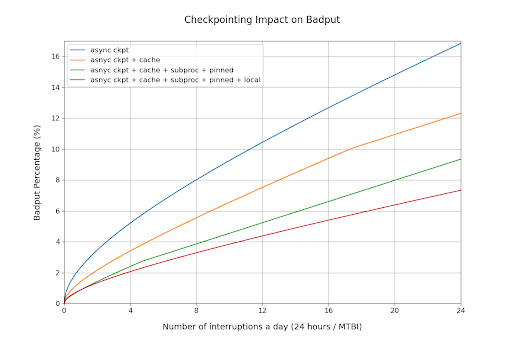
图8:检查点对不良吞吐量的影响
该图显示,随着中断变得更频繁,每次检查点优化对训练吞吐量的影响也变得更显著。在故障每小时发生一次的最极端情况下,这些检查点优化可以将不良吞吐量降低9个百分点。
这些结果强调,优化的检查点解决方案对于处理频繁中断的大规模训练作业至关重要。
如何在 DCP 中启用这些优化?
这些功能已作为 PyTorch 每夜构建的一部分提供,您可以直接在TorchTitan中测试 PyTorch 的异步 DCP 检查点。以下是启用这些功能的说明:
- 基于进程的异步检查点:
- 在async_save API 中将async_checkpointer_type 设置为 AsyncCheckpointerType.PROCESS。(文件:pytorch/torch/distributed/checkpoint/state_dict_saver.py)
- 保存计划缓存:
- 在DefaultSavePlanner中将enable_plan_caching 标志设置为 true。(文件:pytorch/torch/distributed/checkpoint/default_planner.py)
- 启用基于固定内存的暂存
- 在StagingOptions中创建暂存器,并将use_pinned_memory 标志设置为 true。(文件:https://github.com/pytorch/pytorch/blob/main/torch/distributed/checkpoint/staging.py)
- 在集群本地检查点中: https://github.com/AI-Hypercomputer/resiliency
附录
采用检查点不良吞吐量的公式,最佳检查点间隔可以推导如下:

其中 定义为