vLLM 引擎是目前执行大型语言模型 (LLM) 的最佳方式之一。它提供了 vllm serve 命令,作为在单机上部署模型的简便选项。虽然这很方便,但要在生产环境中大规模地服务这些 LLM,还需要一些高级功能。
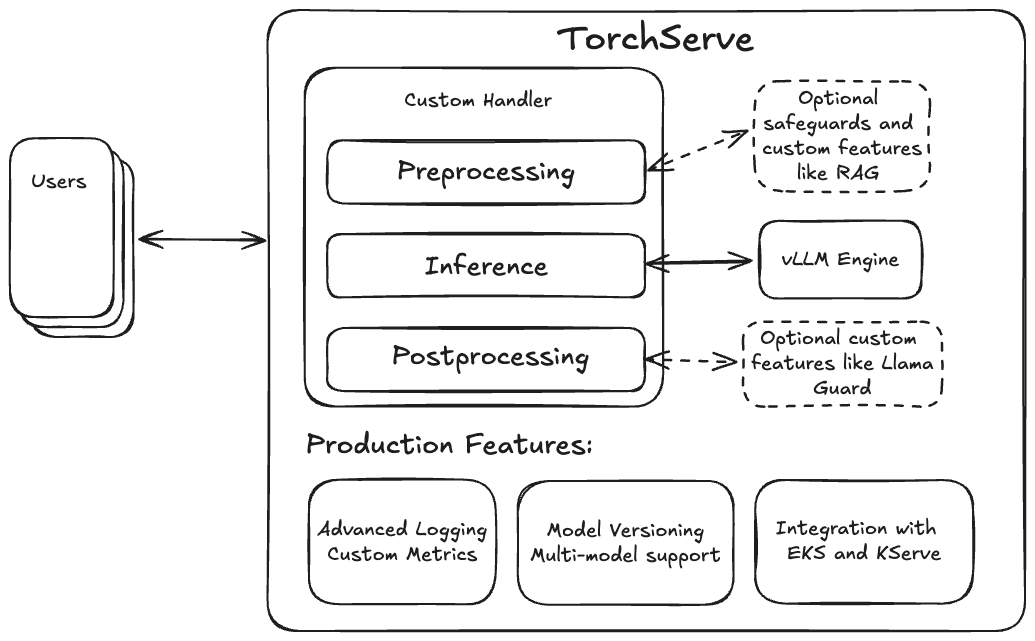
TorchServe 提供了这些基本的生产功能(如自定义指标和模型版本控制),并通过其灵活的自定义处理程序设计,使得集成检索增强生成 (RAG) 或像 Llama Guard 这样的安全防护功能变得非常容易。因此,将 vLLM 引擎与 TorchServe 结合起来,创建一套完整的生产级 LLM 服务解决方案是很自然的。
在深入探讨集成细节之前,我们将演示如何使用 TorchServe 的 vLLM Docker 镜像部署 Llama-3.1-70B-Instruct 模型。
在 TorchServe + vLLM 上快速开始使用 Llama 3.1
首先,我们需要通过检出 TorchServe 仓库并在主文件夹中执行以下命令来构建 新的 TS LLM Docker 容器镜像
docker build --pull . -f docker/Dockerfile.vllm -t ts/vllm
该容器使用我们新的 LLM 启动脚本 ts.llm_launcher,该脚本接受一个 Hugging Face 模型 URI 或本地文件夹,并启动一个本地 TorchServe 实例,后台运行 vLLM 引擎。要在本地服务模型,您可以使用以下命令创建容器实例
#export token=<HUGGINGFACE_HUB_TOKEN>
docker run --rm -ti --shm-size 10g --gpus all -e HUGGING_FACE_HUB_TOKEN=$token -p
8080:8080 -v data:/data ts/vllm --model_id meta-llama/Meta-Llama-3.1-70B-Instruct --disable_token_auth
您可以使用此 curl 命令在本地测试端点
curl -X POST -d '{"model":"meta-llama/Meta-Llama-3.1-70B-Instruct", "prompt":"Hello, my name is", "max_tokens": 200}' --header "Content-Type: application/json" "https://:8080/predictions/model/1.0/v1/completions"
docker 将模型权重存储在本地文件夹“data”中,该文件夹在容器内部挂载为 /data。要服务您的自定义本地权重,只需将其复制到 data 中,并将 model_id 指向 /data/<您的权重>。
在内部,容器使用我们新的 ts.llm_launcher 脚本来启动 TorchServe 并部署模型。该启动器将 LLM 与 TorchServe 的部署简化为一个命令行,也可以在容器外部用作实验和测试的有效工具。要在 Docker 外部使用启动器,请遵循 TorchServe 安装步骤,然后执行以下命令启动一个 8B Llama 模型
# after installing TorchServe and vLLM run
python -m ts.llm_launcher --model_id meta-llama/Meta-Llama-3.1-8B-Instruct --disable_token_auth
如果有多张 GPU 可用,启动器将自动占用所有可见设备并应用张量并行(请参阅 CUDA_VISIBLE_DEVICES 以指定要使用的 GPU)。
虽然这非常方便,但重要的是要注意它不包含 TorchServe 提供的所有功能。对于那些希望利用更高级功能的人来说,需要创建一个模型存档。虽然这个过程比发出单个命令稍微复杂一些,但它具有自定义处理程序和版本控制的优势。前者允许在预处理步骤中实现 RAG,而后者允许您在更大规模部署之前测试不同版本的处理程序和模型。
在我们提供创建和部署模型存档的详细步骤之前,让我们深入了解 vLLM 引擎集成的细节。
TorchServe 的 vLLM 引擎集成
作为最先进的服务框架,vLLM 提供了大量高级功能,包括 PagedAttention、连续批处理、通过 CUDA 图快速执行模型,以及支持各种量化方法,如 GPTQ、AWQ、INT4、INT8 和 FP8。它还提供了对 LoRA 等重要的参数高效适配器方法的集成,并支持包括 Llama 和 Mistral 在内的多种模型架构。vLLM 由 vLLM 团队和活跃的开源社区维护。
为了方便快速部署,它提供了一个基于 FastAPI 的服务模式,通过 HTTP 提供 LLM 服务。为了更紧密、更灵活的集成,该项目还提供了 vllm.LLMEngine,它提供了持续处理请求的接口。我们利用其 异步变体 集成到 TorchServe 中。
TorchServe 是一个易于使用的开源解决方案,用于在生产环境中服务 PyTorch 模型。作为经过生产验证的服务解决方案,TorchServe 提供了许多有益的功能,用于大规模部署 PyTorch 模型。通过将其与 vLLM 引擎的推理性能相结合,现在这些优势也可以用于大规模部署 LLM。
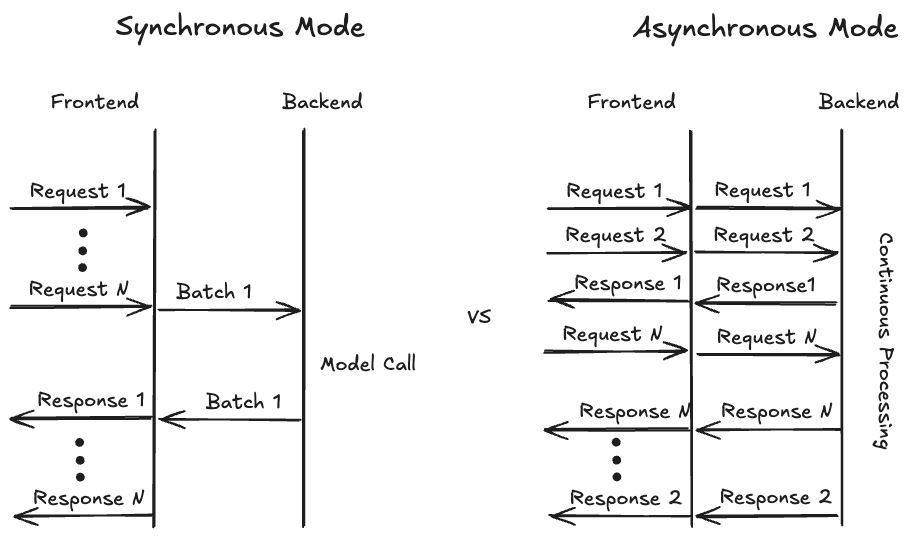
为了最大化硬件利用率,通常将来自多个用户的请求进行批处理是一个好习惯。历史上,TorchServe 只提供了同步模式来收集来自不同用户的请求。在此模式下,TorchServe 会等待预定义的时间(例如,batch_delay=200ms)或直到足够的请求(例如,batch_size=8)到达。当这些事件之一被触发时,批处理数据会被转发到后端,模型会应用于该批次,然后模型输出通过前端返回给用户。这对于传统视觉模型特别有效,因为每个请求的输出通常同时完成。
对于生成式用例,特别是文本生成,请求同时准备好的假设不再成立,因为响应的长度会有所不同。尽管 TorchServe 支持连续批处理(动态添加和删除请求的能力),但此模式只能容纳静态的最大批处理大小。随着 PagedAttention 的引入,即使是最大批处理大小的假设也变得更加灵活,因为 vLLM 可以高度适应地组合不同长度的请求,以优化内存利用率。
为了实现最佳内存利用率,即填补内存中未使用的空白(想象一下俄罗斯方块),vLLM 需要完全控制在任何给定时间处理哪些请求的决定。为了提供这种灵活性,我们必须重新评估 TorchServe 处理用户请求的方式。我们没有采用以前的同步处理模式,而是引入了一种异步模式(见下图),其中传入的请求直接转发到后端,使其可供 vLLM 使用。后端将请求馈送给 vllm.AsyncEngine,后者现在可以从所有可用请求中进行选择。如果启用了流式传输模式并且请求的第一个 token 可用,后端将立即发送结果并继续发送 token,直到生成最后一个 token。
我们对 VLLMHandler 的实现 使您能够使用配置文件快速部署任何与 vLLM 兼容的模型,同时仍通过自定义处理程序提供相同级别的灵活性和可定制性。您可以自由地添加例如自定义的 预处理 或 后处理 步骤,方法是继承 VLLMHandler 并重写相应的类方法。
我们还支持单节点、多 GPU 分布式推理,其中我们将 vLLM 配置为使用模型的张量并行分片,以增加小型模型的容量或启用不适合单个 GPU 的大型模型,例如 70B Llama 变体。以前,TorchServe 只支持使用 torchrun 进行分布式推理,其中会启动多个后端工作进程来分片模型。vLLM 在内部管理这些进程的创建,因此我们 向 TorchServe 引入了新的“custom”并行类型,它启动一个后端工作进程并提供分配的 GPU 列表。然后,后端进程可以在必要时启动自己的子进程。
为了方便将 TorchServe + vLLM 集成到基于 Docker 的部署中,我们提供了一个单独的 Dockerfile,该文件基于 TorchServe 的 GPU docker 镜像,并将 vLLM 添加为依赖项。我们选择将两者分开,以避免增加非 LLM 部署的 docker 镜像大小。
接下来,我们将演示在具有四个 GPU 的机器上使用 TorchServe + vLLM 部署 Llama 3.1 70B 模型所需的步骤。
分步指南
对于本分步指南,我们假设 TorchServe 的安装 已成功完成。目前,vLLM 不是 TorchServe 的硬依赖项,因此我们使用 pip 安装该软件包
$ pip install -U vllm==0.6.1.post2
在接下来的步骤中,我们将(可选地)下载模型权重,解释配置,创建模型存档,然后部署和测试它
1. (可选) 下载模型权重
此步骤是可选的,因为 vLLM 也可以在模型服务器启动时处理权重的下载。然而,预先下载模型权重并在 TorchServe 实例之间共享缓存文件,可以在存储使用和模型 worker 启动时间方面受益。如果您选择下载权重,请使用 huggingface-cli 并执行
# make sure you have logged into huggingface with huggingface-cli login before
# and have your access request for the Llama 3.1 model weights approved
huggingface-cli download meta-llama/Meta-Llama-3.1-70B-Instruct --exclude original/*
这会将文件下载到 $HF_HOME 下,如果您想将文件放在其他位置,可以更改此变量。请确保您在运行 TorchServe 的任何地方更新该变量,并确保它有权访问该文件夹。
2. 配置模型
接下来,我们创建一个 YAML 配置文件,其中包含模型部署所需的所有参数。配置文件的第一部分指定前端如何启动后端 worker,该 worker 最终将在处理程序中运行模型。第二部分包含后端处理程序的参数,例如要加载的模型,然后是 vLLM 本身的各种参数。有关 vLLM 引擎可能配置的更多信息,请参阅此 链接。
echo '
# TorchServe frontend parameters
minWorkers: 1
maxWorkers: 1 # Set the number of worker to create a single model instance
startupTimeout: 1200 # (in seconds) Give the worker time to load the model weights
deviceType: "gpu"
asyncCommunication: true # This ensures we can cummunicate asynchronously with the worker
parallelType: "custom" # This lets TS create a single backend prosses assigning 4 GPUs
parallelLevel: 4
# Handler parameters
handler:
# model_path can be a model identifier for Hugging Face hub or a local path
model_path: "meta-llama/Meta-Llama-3.1-70B-Instruct"
vllm_engine_config: # vLLM configuration which gets fed into AsyncVLLMEngine
max_num_seqs: 16
max_model_len: 512
tensor_parallel_size: 4
served_model_name:
- "meta-llama/Meta-Llama-3.1-70B-Instruct"
- "llama3"
'> model_config.yaml
3. 创建模型文件夹
创建模型配置文件 (model_config.yaml) 后,我们现在将创建一个模型存档,其中包含配置和附加元数据,例如版本信息。由于模型权重较大,我们不会将其包含在存档中。相反,处理程序将通过 model_path 访问权重,该路径在模型配置中指定。请注意,在此示例中,我们选择了“无存档”格式,它创建了一个包含所有必要文件的模型文件夹。这使我们能够轻松修改配置文件以进行实验,而不会遇到任何摩擦。稍后,我们还可以选择 mar 或 tgz 格式来创建更易于传输的工件。
mkdir model_store
torch-model-archiver --model-name vllm --version 1.0 --handler vllm_handler --config-file model_config.yaml --archive-format no-archive --export-path model_store/
4. 部署模型
下一步是启动 TorchServe 实例并加载模型。请注意,为了本地测试,我们已禁用令牌身份验证。强烈建议在公开部署任何模型时实施某种形式的身份验证。
要启动 TorchServe 实例并加载模型,请运行以下命令
torchserve --start --ncs --model-store model_store --models vllm --disable-token-auth
您可以通过日志语句监控模型加载的进度。模型加载完成后,您可以继续测试部署。
5. 测试部署
vLLM 集成使用 OpenAI API 兼容格式,因此我们可以使用专门的工具或 curl。我们在此处使用的 JSON 数据包括模型标识符和提示文本。其他选项及其默认值可以在 vLLMEngine 文档中找到。
echo '{
"model": "llama3",
"prompt": "A robot may not injure a human being",
"stream": 0
}' | curl --header "Content-Type: application/json" --request POST --data-binary @- https://:8080/predictions/vllm/1.0/v1/completions
请求的输出如下所示
{
"id": "cmpl-cd29f1d8aa0b48aebcbff4b559a0c783",
"object": "text_completion",
"created": 1727211972,
"model": "meta-llama/Meta-Llama-3.1-70B-Instruct",
"choices": [
{
"index": 0,
"text": " or, through inaction, allow a human being to come to harm.\nA",
"logprobs": null,
"finish_reason": "length",
"stop_reason": null,
"prompt_logprobs": null
}
],
"usage": {
"prompt_tokens": 10,
"total_tokens": 26,
"completion_tokens": 16
}
当流式传输为 False 时,TorchServe 将在生成最后一个 token 后收集完整的答案并一次性发送。如果我们切换流式参数,我们将收到包含单个 token 的分段数据。
结论
在这篇博客文章中,我们探讨了 vLLM 推理引擎与 TorchServe 的全新原生集成。我们演示了如何使用 ts.llm_launcher 脚本在本地部署 Llama 3.1 70B 模型,以及如何创建模型存档以在任何 TorchServe 实例上进行部署。此外,我们讨论了如何构建和在 Docker 容器中运行解决方案,以便在 Kubernetes 或 EKS 上进行部署。在未来的工作中,我们计划启用 vLLM 和 TorchServe 的多节点推理,并提供预构建的 Docker 镜像以简化部署过程。
我们衷心感谢 Mark Saroufim 和 vLLM 团队在撰写本博客文章之前提供的宝贵支持。