去年,Meta 宣布 PyTorch 加入 Linux 基金会,成为发展机器学习项目和社区的“中立之家”,而 AMD 作为创始成员和理事会成员之一。
PyTorch Foundation 的使命是通过与 AMD 开放软件生态系统的核心原则相符的开源原则,普及其软件生态系统,从而推动人工智能的普及。AMD 致力于通过支持最新一代的硬件、工具、库和其他组件来促进创新,以简化和加速人工智能在广泛科学发现中的应用。
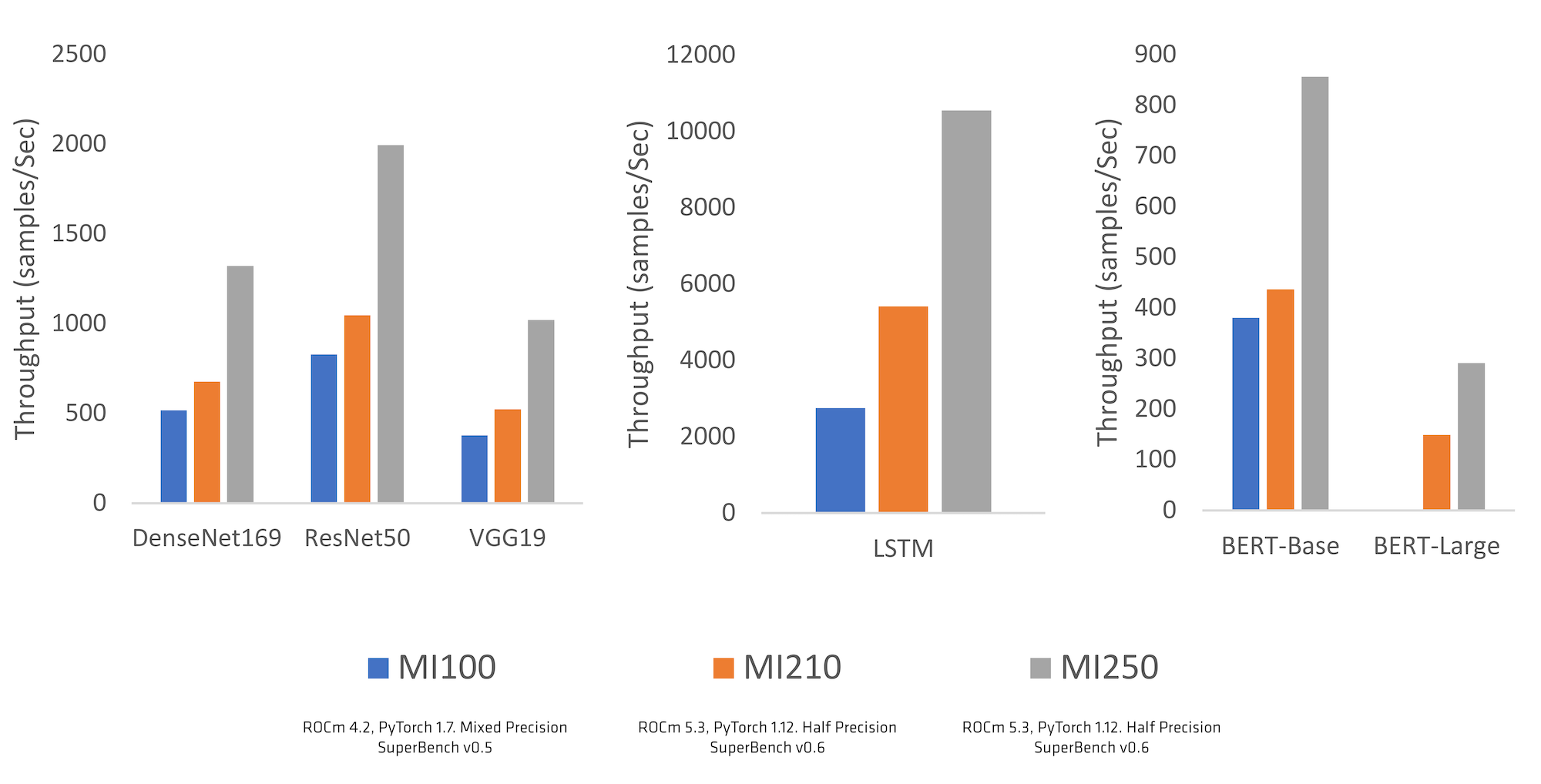
AMD 与主要的 PyTorch 代码库开发者(包括 Meta AI 的开发者)一起,为 ROCm™ 开放软件生态系统提供了一系列更新,为 AMD Instinct™ 加速器以及许多 Radeon™ GPU 带来了稳定支持。现在,PyTorch 开发者能够利用 AMD GPU 加速器和 ROCm 构建他们下一个伟大的人工智能解决方案。PyTorch 社区在识别差距、优先安排关键更新、提供性能优化反馈以及支持我们从“Beta”到“稳定”的旅程方面提供了巨大的帮助,我们深切感谢 AMD 和 PyTorch 两个团队之间的紧密合作。ROCm 支持从“Beta”到“稳定”的转变发生在 PyTorch 1.12 版本(2022 年 6 月),带来了在原生环境中轻松运行 PyTorch 的额外支持,而无需配置自定义 Docker。这标志着对 PyTorch 使用 AMD Instinct 和 ROCm 的支持质量和性能的信心。这些合作努力的成果在 Microsoft SuperBench 等关键行业基准测试中得到了体现,如下面的图 1 所示。
“我们很高兴看到 AMD 开发者在 PyTorch 中贡献和扩展功能,从而使 AI 模型以更高性能、更高效和更可扩展的方式运行,产生了显著影响。其中一个很好的例子是关于框架和未来硬件系统之间统一内存方法的思想领导力,我们期待看到该功能的进展。”
– Soumith Chintala,PyTorch 首席维护者和 Meta AI 工程总监