引言
我们于 2024 年夏季推出了 DeepNVMe,作为一套旨在解决深度学习 (DL) 中 I/O 瓶颈的优化方案。DeepNVMe 利用本地 NVMe SSD、NVIDIA Magnum IOTM GPUDirect® Storage (GDS) 和 Linux 异步 I/O (AIO) 等存储创新,显著提升了 I/O 密集型 DL 工作负载的速度。在此次更新中,我们很高兴地宣布 DeepNVMe 在多个方面进行了改进:(i) 将应用范围扩展到 FastPersist 模型检查点和 SGLang 推理,(ii) 通过从 PCIe Gen4 升级到 Gen5 NVMe SSD 来扩展 I/O 性能,以及 (iii) 将可用性扩展到纯 CPU 环境、基于偏移的 I/O 操作和张量数据类型转换。本博客中报告的结果可在 DeepSpeed 版本 >= 0.17.1 中获取。
评估环境
| 软件 | 版本 |
|---|---|
| Ubuntu | 24.04.2 |
| PyTorch | 2.6.0 |
| CUDA | 12.6 |
| SGLang | 0.4.4.post4 |
解决深度学习的 I/O 瓶颈
我们使用 DeepNVMe 开发了 FastPersist 和 ZeRO-Inference,分别用于解决 DL 训练和推理中的 I/O 瓶颈。我们的实验在单个虚拟机上进行,其中我们将可用的 NVMe SSD 组合成一个 RAID-0(即磁盘条带化)卷,以利用聚合读写带宽。由于 DeepNVMe 可以使用 CPU 弹跳缓冲区(又称 AIO)或 NVIDIA GPUDirect Storage(又称 GDS)卸载张量,因此我们报告了两种模式的结果。
FastPersist:更快的模型检查点创建
尽管将模型检查点保存到持久存储对于模型训练至关重要,但由于现有方法的低效率,它也是一个主要瓶颈。我们开发了 FastPersist 来解决检查点创建的性能挑战。FastPersist 通过三种关键技术使训练期间的检查点开销可忽略不计:(i) DeepNVMe,(ii) 数据并行,以及 (iii) I/O 和计算重叠。
我们的目标是使用单进程微基准测试(可在此处获取)来演示 DeepNVMe 在 FastPersist 中的影响,该基准测试将模型检查点状态从 HBM 序列化到本地 NVMe。在我们的实验中,我们使用流行的 PyTorch torch.save() 作为基线,并将 FastPersist 集成到 torch.save() 中,以简化采用和性能比较。
更快地将 PyTorch 模型保存到本地 NVMe 存储
我们测量了将 Phi-3-Mini 检查点状态从 HBM 序列化到本地 NVMe 存储的吞吐量。结果总结在下图中。我们观察到 FastPersist 的检查点创建速度比基线快得多。在 8xGen5 NVMe 设置中,我们看到了超过 20 倍的速度提升。我们还观察到 FastPersist 随着 8xGen5 NVMe 带宽的增加而扩展,与 4xGen5 相比。
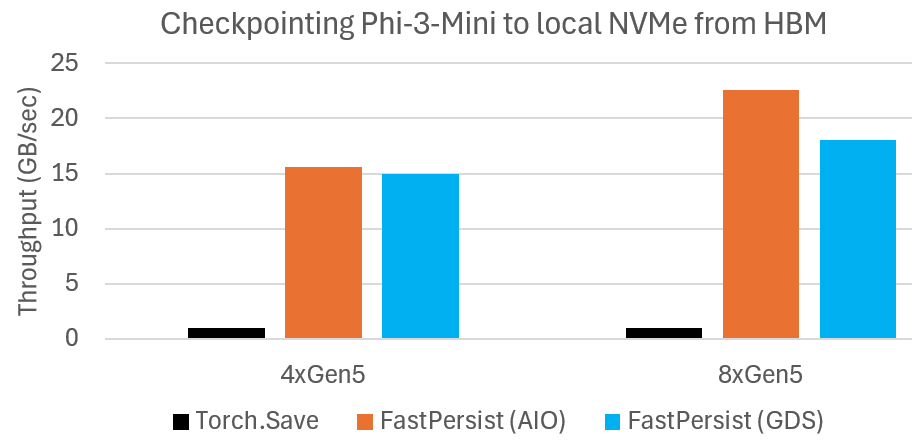
FastPersist 提供显著更快的模型检查点保存到本地 NVMe。
ZeRO-Inference:普及生成式 AI
ZeRO-Inference 是一种通过降低模型推理的 GPU 成本来普及最先进模型的技术。ZeRO-Inference 通过将模型权重卸载到 DRAM 和 NVMe 存储,可以在最少一个 GPU 上实现大规模模型(数千亿参数)的推理计算。ZeRO-Inference 专为离线或吞吐量导向的推理场景而设计。在本博客中,我们分享了 ZeRO-Inference 的两个更新。首先,我们已将 ZeRO-Inference 集成到最先进的模型服务框架 SGLang 中。其次,我们观察到 ZeRO-Inference 性能随着最新 Azure SKU 中更快的 NVMe SSD 而扩展。
通过 ZeRO-Inference 集成普及 SGLang
SGLang 是一个用于大型语言模型 (LLM) 和视觉语言模型 (VLM) 的最先进服务框架。我们将 ZeRO-Inference 集成到 SGLang 中,使预算有限的用户也能使用 SGLang,并为现有 SGLang 用户提供了一种成本降低选项。我们使用 SGLang 的 离线基准测试工具 来测量 LLAMA3-70B 在单个 H200 上使用 NVMe 卸载时的生成吞吐量(LLAMA3-70B 在没有卸载的情况下无法适应 141GB 显存)。实验配置为提示长度 512,生成长度 32,批次大小 128。我们总结了下图中 AIO 和 GDS 卸载的结果。
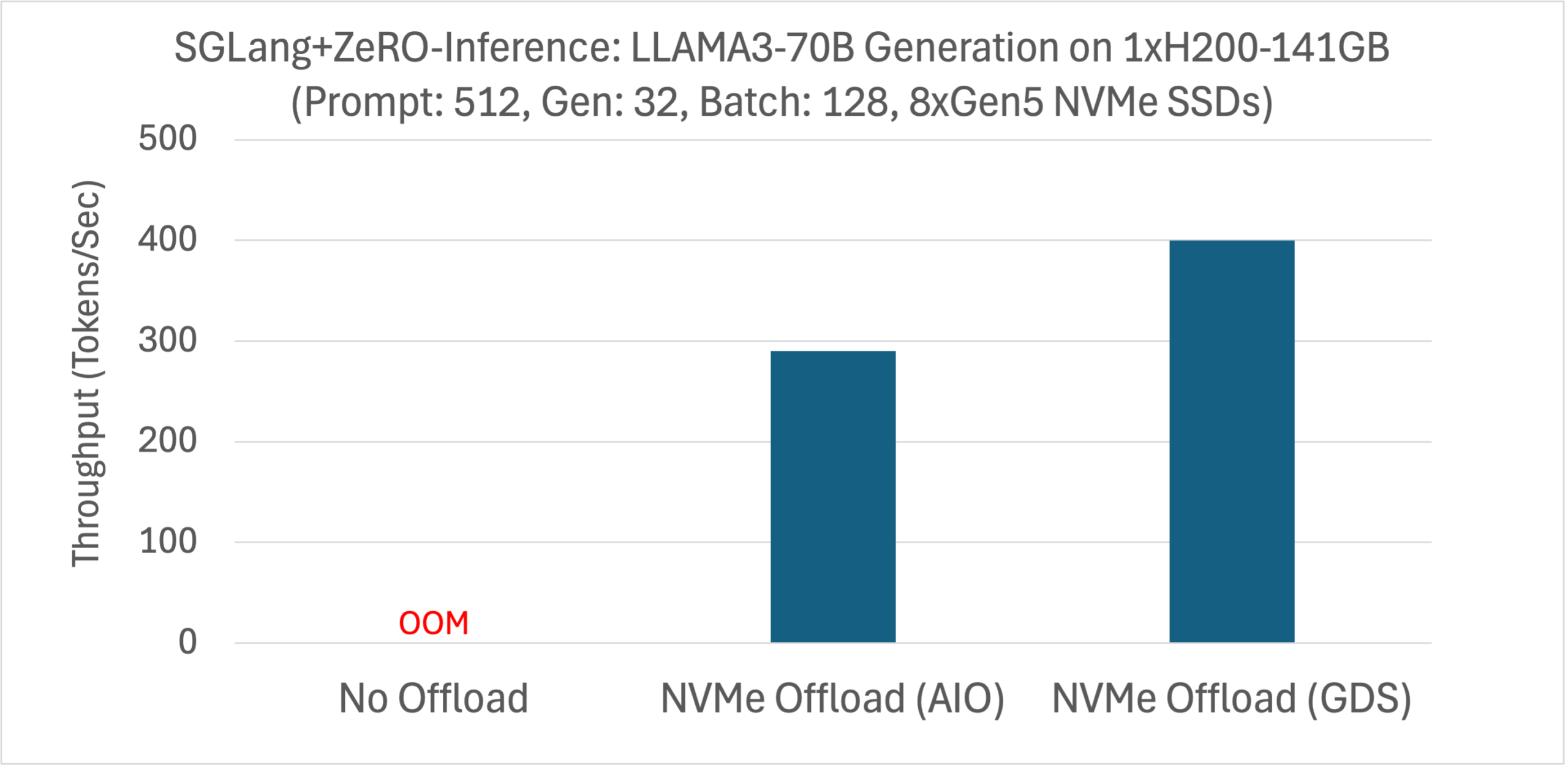
ZeRO-Inference 通过 NVMe 卸载改进了 SGLang 推理,从而降低了硬件成本。
使用更快的 NVMe SSD 扩展 HF Transformer 生成
ZeRO-Inference 通过高效的模型卸载到 DRAM 或 NVMe 来增强 HF Transformer 推理。我们之前在 Azure NC_A100_v4 虚拟机上使用单个 GPU 和四个 Gen4 NVMe 评估了 LLAMA-3-70B 使用 NVMe 卸载的生成性能。我们测量了提示长度为 512 标记、输出为 32 标记、批次大小为 96 的生成速度。由于 NVMe 带宽是主要瓶颈,我们在提供 Gen5 NVMe 的 Azure ND-H200-v5 上重复了实验。下图总结的结果表明,ZeRO-Inference 利用增加的 NVMe 带宽来提高生成速度。例如,使用 GDS,生成速度从四个 Gen4 NVMe 的 7 标记/秒提高到四个 Gen5 NVMe 的 17 标记/秒,并进一步提高到八个 Gen5 NVMe 的 26 标记/秒。我们观察到没有 GDS 也有类似的改进。这些结果表明,通过增加 NVMe 带宽,可以以经济高效的方式提高 ZeRO-Inference 性能。
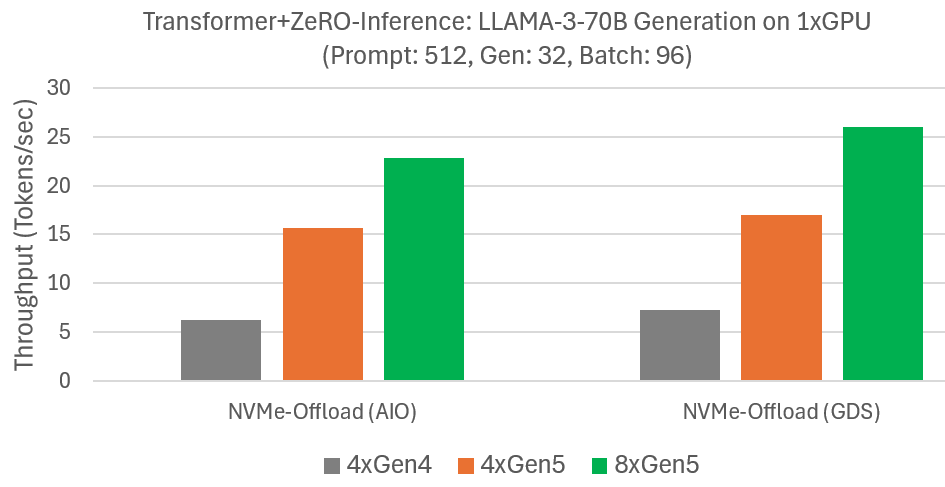
I/O 性能扩展
我们使用 ds_io 基准测试工具演示了 DeepNVMe 与可用 NVMe 带宽成比例地扩展 I/O 性能。这使用户能够以适度的成本,通过更多或更快的 NVMe SSD 加速 I/O 密集型 DL 应用。在我们的实验中,我们测量了 HBM 和 NVMe 之间 1GB 数据传输的已实现读写带宽。我们评估了 NVMe 从 PCIe Gen4 扩展到 Gen5,以及从 4 个 SSD 扩展到 8 个 SSD。SSD 组合成一个 RAID-0(磁盘条带化)卷。结果总结在下图中,显示 DeepNVMe 在两个维度上都扩展了 I/O 性能。从 4xGen4 SSD 扩展到 4xGen5 SSD,读取从 10GB/秒提高到 27GB/秒,写入从 5GB/秒提高到 11GB/秒。从 4xGen5 扩展到 8xGen5,读取进一步提高到 48GB/秒,写入提高到 26GB/秒。
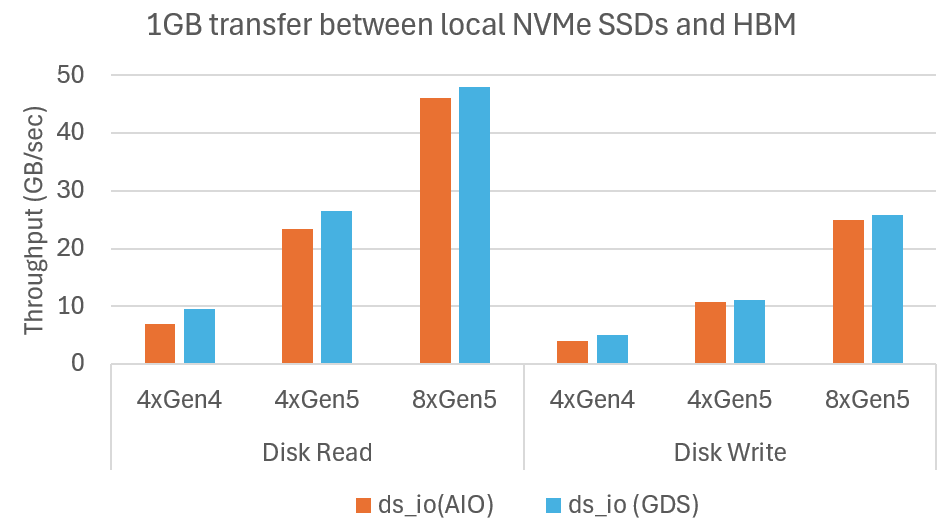 微基准测试显示 DeepNVMe 随着可用 NVMe 带宽扩展 I/O 性能
微基准测试显示 DeepNVMe 随着可用 NVMe 带宽扩展 I/O 性能扩大可用性
我们通过消除硬件环境和 I/O 操作方面的限制,增加了 DeepNVMe 的使用场景,如下所述。
纯 CPU 环境
尽管 GPU(和类似的加速器)在 DL 中占据主导地位,但 CPU 仍然用于重要的机器学习 (ML) 工作负载,例如推荐系统。然而,DeepNVMe 以前无法在纯 CPU 环境中使用。这是因为 DeepNVMe 依赖于 torch.pin_memory() 进行页锁定 CPU 张量,而 torch.pin_memory() 在 torch 的 CPU 版本中不起作用,如下所示。
>>> import torch >>> torch.__version__ '2.6.0+cpu' >>> x = torch.empty(1024).pin_memory() Traceback (most recent call last): File "<stdin>", line 1, in <module> RuntimeError: Cannot access accelerator device when none is available. >>>
我们通过添加分配 (new_cpu_locked_tensor()) 和释放 (free_cpu_locked_tensor()) 页锁定 CPU 张量的机制,使 DeepNVMe 可以在 CPU 环境中使用。下面的代码片段演示了分配一个固定 CPU 张量 (x)。
>> import torch >>> torch.__version__ '2.6.0+cpu' >>> from deepspeed.ops.op_builder import AsyncIOBuilder >>> h = AsyncIOBuilder().load().aio_handle() >>> x = h.new_cpu_locked_tensor(1024, torch.Tensor()) >>> x.shape torch.Size([1024]) >>> x.dtype torch.float32
基于偏移的 I/O 操作
以前,DeepNVMe 的功能仅限于读取或写入文件的全部内容。我们现在改进了 DeepNVMe,使其能够从给定偏移量读取或写入文件内容的指定部分。特别是,我们已将现有的读/写 API 扩展为接受用户指定的 file offset 参数(默认值为 0),如下所示:
>> from deepspeed.ops.op_builder import AsyncIOBuilder >>> help(AsyncIOBuilder().load().aio_handle().pread) Help on method pread in module async_io: pread(...) method of async_io.aio_handle instance pread(self: async_io.aio_handle, buffer: torch.Tensor, filename: str, validate: bool, async: bool, file_offset: int = 0) -> int
张量数据类型转换
在开发 FastPersist 时,我们需要以字节格式操作模型张量(通常是浮点数据类型),以实现性能和 I/O 操作的便利性。然而,我们找不到一种零拷贝机制来将张量从任意数据类型转换为字节数据类型(即 torch.uint8),所以我们决定创建一个。此功能可通过 UtilsBuilder 操作获取,如下例所示。在该示例中,我们将 torch.bfloat16 张量转换为 torch.uint8。请注意,由于该功能的零拷贝性质,bf16_tensor 和 byte_tensor 是别名。
>>> import torch >>> from deepspeed.ops.op_builder import UtilsBuilder >>> util_ops = UtilsBuilder().load() >>> bf16_tensor = torch.zeros(1024, dtype=torch.bfloat16, device='cuda') >>> bf16_tensor tensor([0., 0., 0., ..., 0., 0., 0.], device='cuda:0', dtype=torch.bfloat16) >>> byte_tensor = util_ops.cast_to_byte_tensor(bf16_tensor) >>> byte_tensor tensor([0, 0, 0, ..., 0, 0, 0], device='cuda:0', dtype=torch.uint8) >>> bf16_tensor += 1.0 >>> bf16_tensor tensor([1., 1., 1., ..., 1., 1., 1.], device='cuda:0', dtype=torch.bfloat16) >>> byte_tensor tensor([128, 63, 128, ..., 63, 128, 63], device='cuda:0', dtype=torch.uint8)
总结
本博客文章提供了我们持续开发 DeepNVMe(一种用于加速 DL 应用的 I/O 优化技术)的最新进展。我们宣布了 DeepNVMe 在多个方面的改进,包括应用覆盖范围、I/O 性能扩展和可用性。
致谢
本博客描述了微软 DeepSpeed 团队的 Joe Mayer、Logan Adams 和 Olatunji Ruwase 所做的工作。