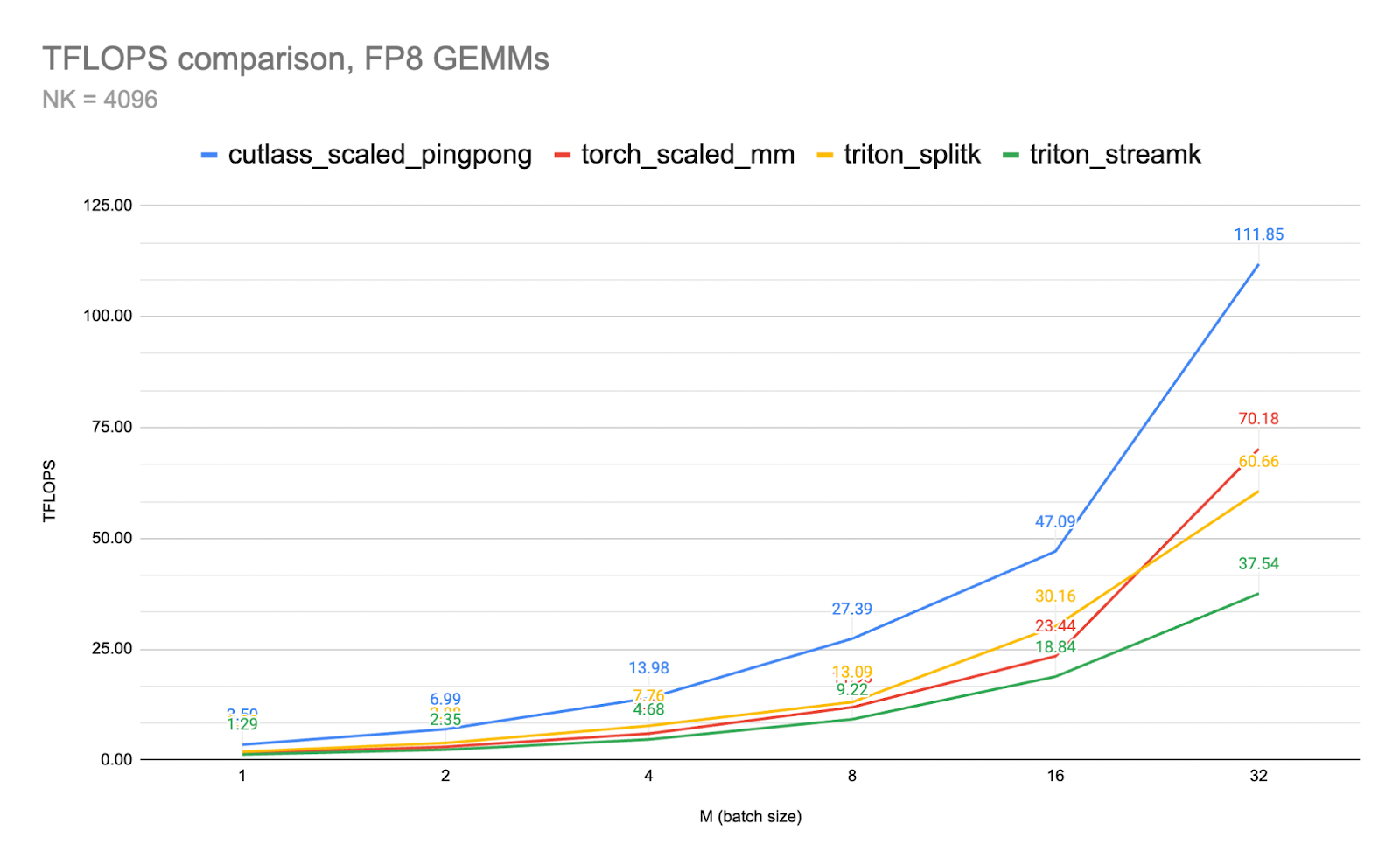
图 1. FP8 GEMM 吞吐量对比 CUTLASS vs Triton
总结
在这篇文章中,我们将概述 CUTLASS Ping-Pong GEMM 内核,并提供相关的 FP8 推理内核基准测试。
Ping-Pong 是 Hopper GPU 架构上最快的矩阵乘法 (GEMM) 内核架构之一。Ping-Pong 属于 Warp Group Specialized Persistent Kernels(翘曲组专用持久性内核)家族,该家族包括 Cooperative 和 Ping-Pong 变体。相对于以前的 GPU,Hopper 强大的张量核心计算能力需要深入的异步软件流水线才能实现峰值性能。
Ping-Pong 和 Cooperative 内核是这一范式的典范,其关键设计模式是:持久性内核,以分摊启动和前言开销;以及“一切皆异步”,通过具有两个消费者和一个生产者的专用翘曲组,创建高度重叠的处理流水线,从而能够持续为张量核心提供数据。
当 H100 (Hopper) GPU 发布时,Nvidia 称其为第一个真正意义上的异步 GPU。这一声明强调了 H100 专用内核架构也需要异步才能充分最大化计算/GEMM 吞吐量。
CUTLASS 3.x 中引入的 Ping-Pong GEMM 通过将内核的所有方面都转移到“完全异步”的处理范式中,从而体现了这一点。在此博客中,我们将展示 Ping-Pong 内核设计的核心功能,并展示其在推理工作负载上相对于 cublas 和 triton split-k 内核的性能。
Ping-Pong 内核设计
Ping-Pong(或技术上称为“sm90_gemm_tma_warpspecialized_pingpong”)采用异步流水线运行,利用翘曲专业化。与更经典的同构内核不同,“翘曲组”承担专业角色。请注意,一个翘曲组由 4 个各 32 个线程的翘曲组成,总共 128 个线程。
在早期架构上,通常通过每个 SM 运行多个线程块来隐藏延迟。然而,对于 Hopper,张量核心的吞吐量非常高,因此需要转向更深的流水线。这些更深的流水线会阻碍每个 SM 运行多个线程块。因此,持久性线程块现在跨多个瓦片和多个翘曲组发出集体主循环。线程块集群根据总 SM 数量进行分配。
对于 Ping-Pong,每个翘曲组都扮演数据生产者或数据消费者的专业角色。
生产者翘曲组专注于数据移动,以填充共享内存缓冲区(通过 TMA)。另外两个翘曲组是专用的消费者,它们使用张量核心处理数学(MMA)部分,然后进行任何后续工作并将结果写回全局内存(后处理)。
生产者翘曲组与 TMA(张量内存加速器)协同工作,并被刻意设计得尽可能轻量级。事实上,在 Ping-Pong 中,它们刻意减少其寄存器资源以提高占用率。生产者将将其最大寄存器计数减少 40,而消费者将将其最大寄存器计数增加 232,这种效果我们可以在 CUTLASS 源代码和相应的 SASS 中看到。

Ping-Pong 的独特之处在于,每个消费者都处理不同的 C 输出瓦片。(作为参考,协同内核在很大程度上等同于 Ping-Pong,但两个消费者组处理相同的 C 输出瓦片)。此外,两个消费者翘曲组随后将它们的工作分配给主循环 MMA 和后处理。
如下图所示
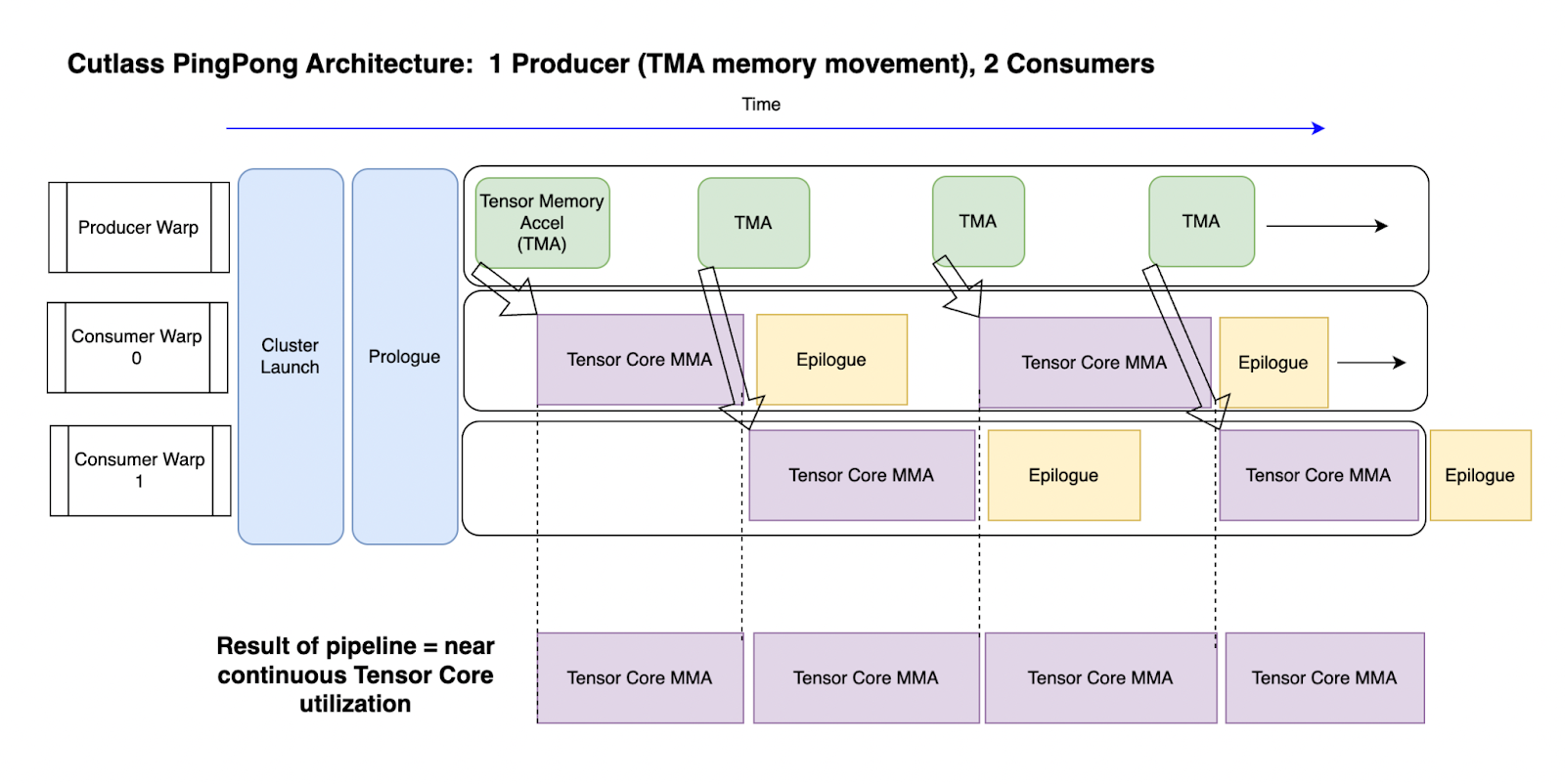
图 2:Ping-Pong 内核流水线概述。时间从左到右移动。
拥有两个消费者意味着一个可以使用张量核心进行 MMA,而另一个执行后处理,然后反之。这最大限度地提高了每个 SM 上张量核心的“连续使用”,并且是实现最大吞吐量的关键原因之一。张量核心可以持续获得数据,以实现其(接近)最大计算能力。(请参阅上面图 2 插图的底部部分)。
类似于生产者线程只专注于数据移动,MMA 线程只发出 MMA 指令以实现峰值发出速率。MMA 线程必须发出多个 MMA 指令并使它们在 TMA 等待屏障前保持飞行状态。
下面是内核代码的摘录,以巩固专业化方面。
// Two types of warp group 'roles'
enum class WarpGroupRole {
Producer = 0,
Consumer0 = 1,
Consumer1 = 2
};
//warp group role assignment
auto warp_group_role = WarpGroupRole(canonical_warp_group_idx());
生产者和张量内存加速器的数据移动
生产者翘曲专门专注于数据移动——具体来说,它们被设计得尽可能轻量级,事实上,它们将一些寄存器空间让给消费者翘曲(只保留 40 个寄存器,而消费者将获得 232 个)。它们的主要任务是发出 TMA(张量内存加速器)命令,一旦共享内存缓冲区被标记为空,就将数据从全局内存移动到共享内存。
扩展到 TMA,或称张量内存加速器,TMA 是 H100 引入的硬件组件,可异步处理从 HBM(全局内存)到共享内存的内存传输。通过拥有专门用于内存移动的硬件单元,工作线程可以自由地从事其他工作,而不是计算和管理数据移动。TMA 不仅处理数据本身的移动,还计算所需的目的地内存地址,可以对数据应用任何转换(缩减等),并且可以处理布局转换,以“交错”模式将数据传输到共享内存,以便无需任何银行冲突即可使用。最后,如果需要,它还可以将相同的数据多播到属于同一线程集群的其他 SM。一旦数据传输完成,TMA 将向感兴趣的消费者发出信号,表明数据已准备就绪。
CUTLASS 异步流水线类
生产者和消费者之间的这种信号通过新的异步流水线类进行协调,CUTLASS 对其描述如下:
“实现持久性 GEMM 算法需要管理数十种不同类型的异步执行操作,这些操作使用以循环列表形式组织的多个屏障进行同步。”
“这种复杂性对于人类程序员来说过于繁琐,无法手动管理。”
“因此,我们开发了 [CUTLASS Pipeline Async Class]……”
Ping-Pong 异步流水线中的屏障和同步
生产者必须通过“producer_acquire”来“获取”给定的 smem 缓冲区。一开始,流水线是空的,这意味着生产者线程可以立即获取屏障并开始移动数据。
PipelineState mainloop_pipe_producer_state = cutlass::make_producer_start_state<MainloopPipeline>();
数据移动完成后,生产者发出“producer_commit”方法,向消费者线程发出数据已准备就绪的信号。
然而,对于 Ping-Pong,这实际上是一个空操作指令,因为当写入完成时,基于 TMA 的生产者屏障会自动由 TMA 更新。
consumer_wait – 等待生产者线程的数据(阻塞)。
consumer_release – 向等待的生产者线程发出信号,表明它们已完成从给定 smem 缓冲区的数据消费。换句话说,允许生产者重新填充此缓冲区以获取新数据。
从那时起,同步将正式开始,生产者将通过阻塞式生产者获取(producer acquire)进行等待,直到它们可以获取锁,此时它们的数据移动工作将重复。这会一直持续到工作完成。
提供伪代码概述
//producer
While (work_tile_info.is_valid_tile) {
collective_mainloop.dma() // fetch data with TMA
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
// Consumer 1, Consumer 2
While (work_tile_info.is_valid_tile()) {
collective_mainloop.mma()
scheduler.advance_to_next_work()
Work_tile_info = scheduler.get_current_work()
}
并提供一个视觉上的鸟瞰图,将所有内容与底层硬件结合起来。
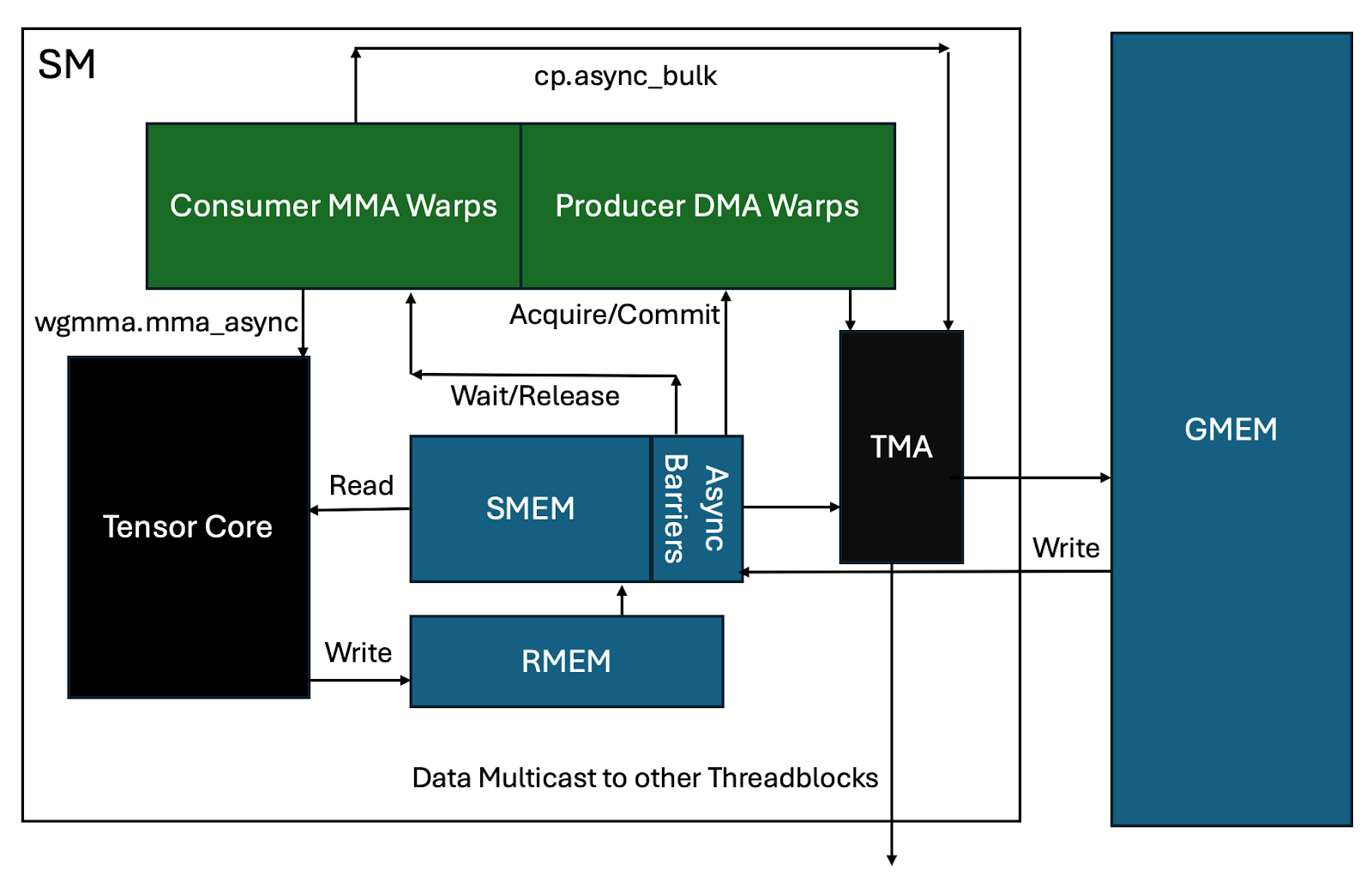
图 3:Ping-Pong 完整异步流水线概述
Ping-Pong 计算循环的分步分解
最后,对 Ping-Pong 处理循环进行更详细的逻辑分解
A – 生产者 (DMA) 翘曲组获取共享内存缓冲区的锁。
B – 这允许它启动一个 tma cp_async.bulk 请求到 tma 芯片(通过单个线程)。
C – TMA 计算所需的实际共享内存地址,并将数据移动到共享内存。作为此过程的一部分,会执行交错以将数据布局在 smem 中,以实现最快的(无银行冲突)访问。
C1 – 潜在地,数据也可以多播到其他 SM,并且/或者它可能需要等待来自其他 tma 多播的数据完成加载。(线程块集群现在跨多个 SM 共享共享内存!)
D – 此时,屏障已更新,以指示数据已到达 smem。
E – 相关消费者翘曲组现在通过发出多个 wgmma.mma_async 命令来开始工作,这些命令随后将数据从 smem 读取到张量核心,作为其 wgmma.mma_async 矩阵乘法操作的一部分。
F – 当瓦片完成时,MMA 累加器值被写入寄存器内存。
G – 消费者翘曲组释放共享内存上的屏障。
H – 生产者翘曲组开始发出下一个 tma 指令,以重新填充现在空闲的 smem 缓冲区。
I – 消费者翘曲组同时对累加器应用任何后处理操作,然后将数据从寄存器移动到不同的 smem 缓冲区。
J – 消费者翘曲发出 cp_async 命令,将数据从 smem 移动到全局内存。
循环重复,直到工作完成。希望这能让您对驱动 Ping-Pong 卓越性能的核心概念有一个实际的理解。
微基准测试
为了展示 Ping-Pong 的一些性能,下面是我们关于设计快速推理内核的工作的一些比较图表。
首先是目前三个最快内核的通用基准测试(越低越好):\
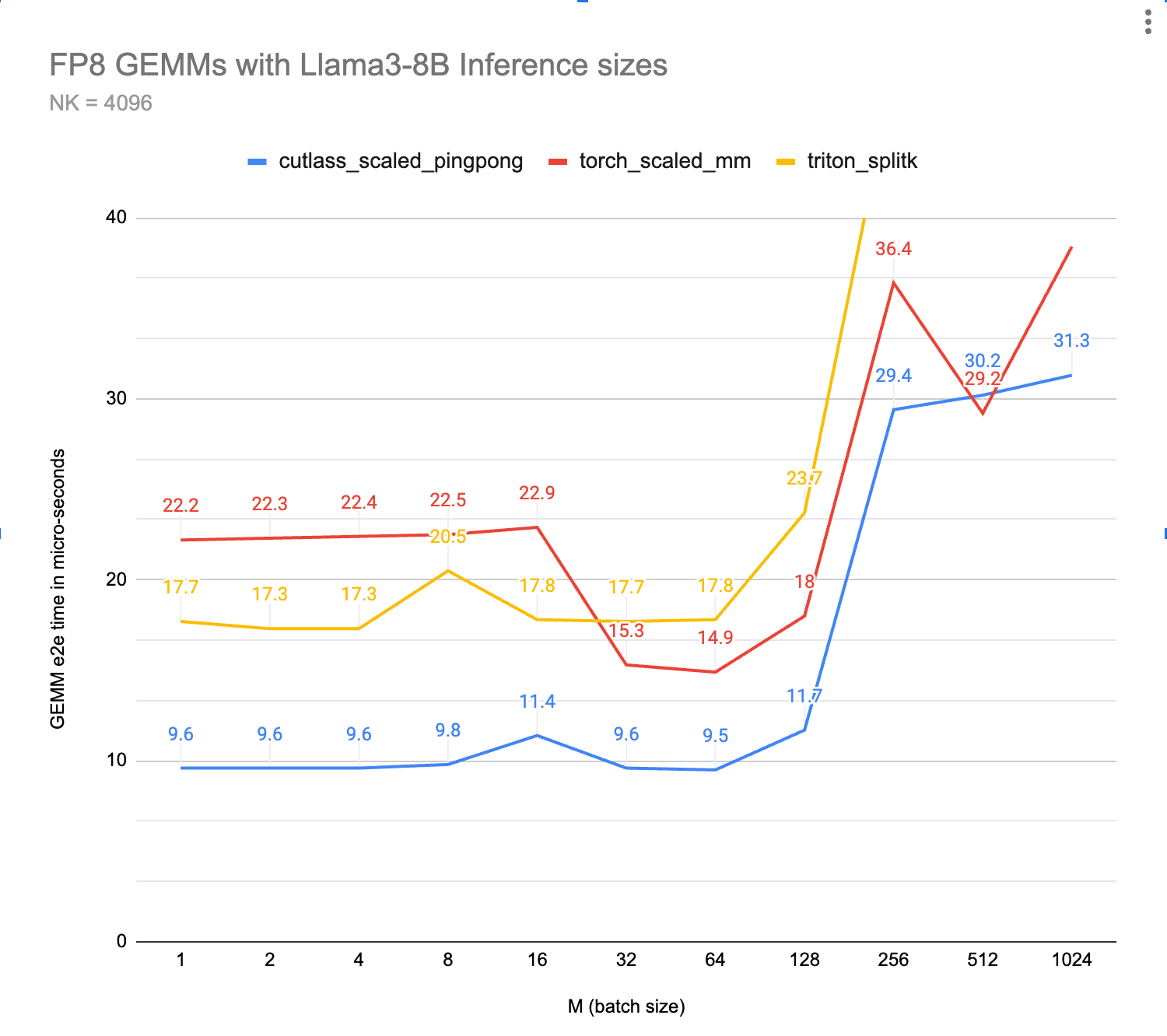
图 4,上方:FP8 GEMM 的基准测试时间,越低越好(越快)
并将其转换为 Ping-Pong 相对于 cuBLAS 和 Triton 的相对加速图表
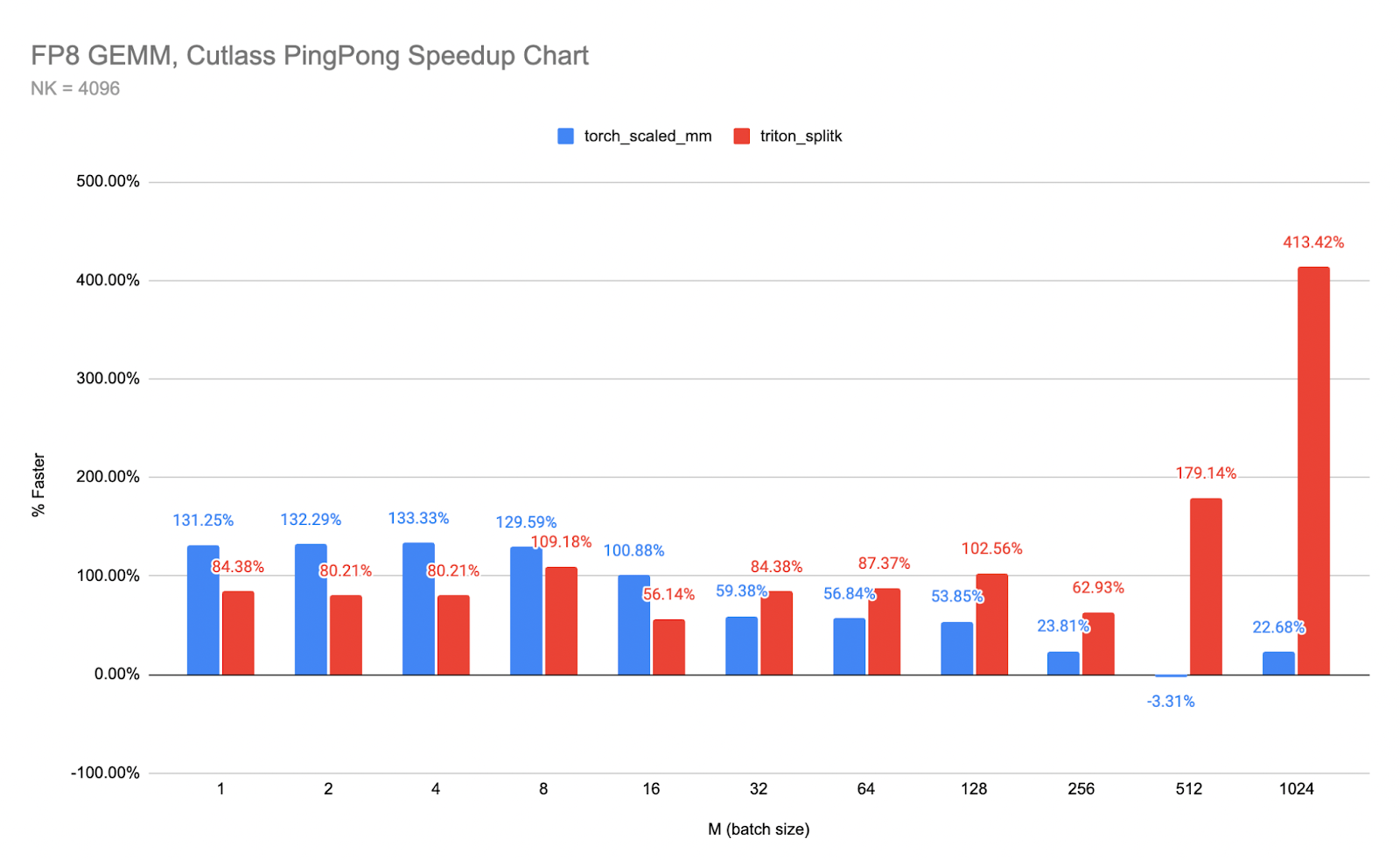
图 5,上方:Ping-Pong 相对于两个最接近内核的相对加速。
Ping-Pong 内核的完整源代码在这里(619 行深度模板化的 CUTLASS 代码,或者引用著名的乌龟梗——“都是模板……一直往下!”)。
此外,我们已将 PingPong 实现为 CPP 扩展,以便于集成到 PyTorch 中使用(并附带一个简单的测试脚本,展示其用法)。
最后,为了持续学习,Nvidia 有两个 GTC 视频深入探讨 CUTLASS 的内核设计。
- 在 Hopper 张量核心上开发最优 CUDA 内核 | GTC 数字春季 2023 | NVIDIA 点播
- CUTLASS:针对 Hopper 张量核心的高性能、灵活和可移植方式 | GTC 24 2024 | NVIDIA 点播
未来工作
数据移动通常是任何内核实现最佳性能的最大障碍,因此,对 Hopper 上的 TMA(张量内存加速器)有一个最佳策略理解至关重要。我们之前发表过关于 Triton 中 TMA 使用 的工作。一旦 Triton 中启用了诸如翘曲专业化等功能,我们计划再次深入探讨 Triton 内核(如 FP8 GEMM 和 FlashAttention)如何利用 Ping-Pong 等内核设计来加速 Hopper GPU。