在这篇博客中,我们讨论了我们用于实现流行 LLM 模型(如 Meta 的 Llama3-8B 和 IBM 的 Granite-8B Code)的 FP16 推理方法,其中 100% 的计算使用 OpenAI 的 Triton 语言 执行。
对于使用我们基于 Triton 内核的模型进行单 token 生成时间,在 Nvidia H100 GPU 上,Llama 和 Granite 的性能分别接近 CUDA 内核主导工作流的 0.76-0.78 倍;在 Nvidia A100 GPU 上,性能接近 0.62-0.82 倍。
为什么要探索使用 100% Triton?Triton 为 LLM 在不同类型的 GPU 上运行提供了途径——NVIDIA、AMD,以及未来的 Intel 和其他基于 GPU 的加速器。它还提供了一个更高层的 Python 抽象,用于 GPU 编程,并使我们能够比使用供应商特定的 API 更快地编写高性能内核。在这篇博客的其余部分,我们将分享我们如何实现 CUDA-free 计算,对单个内核进行微基准测试以进行比较,并讨论我们如何进一步改进未来的 Triton 内核以缩小差距。
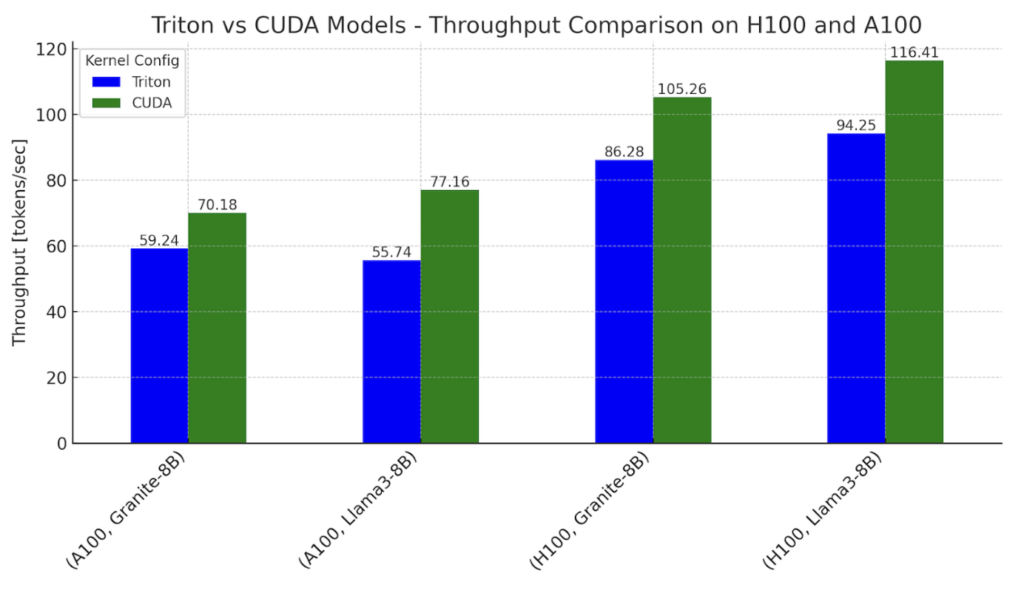
图 1. Llama3-8B 和 Granite-8B 的 Triton 和 CUDA 变体的推理吞吐量基准测试,在 NVIDIA H100 和 A100 上
设置:批处理大小 = 2,输入序列长度 = 512,输出序列长度 = 256
2.0 Transformer 块的组成
我们首先分解 Transformer 模型中发生的计算。下图显示了典型 Transformer 块的“内核”。
![]() 图 2. 按核心内核划分的 Transformer 块
图 2. 按核心内核划分的 Transformer 块
Llama3 架构的核心操作总结如下:
- RMSNorm
- 矩阵乘法:融合 QKV
- RoPE
- Attention
- 矩阵乘法:输出投影
- RMSNorm
- 矩阵乘法:融合门控 + 向上投影
- 激活函数:SiLU
- 元素级乘法
- 矩阵乘法:向下投影
这些操作中的每一个都通过执行一个(或多个)内核在 GPU 上计算。虽然这些内核的细节在不同的 Transformer 模型中可能有所不同,但核心操作保持不变。例如,IBM 的 Granite 8B Code 模型在 MLP 层中使用偏差,这与 Llama3 不同。这些更改确实需要修改内核。典型模型是这些 Transformer 块与嵌入层连接在一起的堆栈。
3.0 模型推理
典型的模型架构代码与由 PyTorch 启动的 python model.py 文件共享。在默认的 PyTorch eager execution 模式下,这些内核都使用 CUDA 执行。为了实现 Llama3-8B 和 Granite-8B 端到端推理的 100% Triton,我们需要编写和集成手写 Triton 内核,并利用 torch.compile(生成 Triton ops)。首先,我们用编译器生成的 Triton 内核替换较小的操作,其次,我们用手写 Triton 内核替换更昂贵和复杂的计算(例如矩阵乘法和 Flash Attention)。
Torch.compile 自动为 RMSNorm、RoPE、SiLU 和元素级乘法生成 Triton 内核。使用 Nsight Systems 等工具,我们可以观察到这些生成的内核;它们以微小的深绿色内核形式出现在矩阵乘法和 Attention 之间。
 图 3. 使用 torch.compile 的 Llama3-8B 跟踪,显示矩阵乘法和 Flash Attention 使用 CUDA 内核
图 3. 使用 torch.compile 的 Llama3-8B 跟踪,显示矩阵乘法和 Flash Attention 使用 CUDA 内核
对于上述跟踪,我们注意到在 Llama3-8B 风格模型中,构成端到端延迟 80% 的两个主要操作是矩阵乘法和 Attention 内核,并且两者仍然是 CUDA 内核。因此,为了弥补剩余的差距,我们用手写 Triton 内核替换了矩阵乘法和 Attention 内核。
4.0 Triton SplitK GEMM 内核
对于线性层中的矩阵乘法,我们编写了一个自定义的 FP16 Triton GEMM(通用矩阵乘法)内核,该内核利用了 SplitK 工作分解。我们之前在其他博客中讨论过这种并行化,作为加速 LLM 推理解码部分的一种方法。
5.0 GEMM 内核调优
为了实现最佳性能,我们使用穷举搜索方法来调优我们的 SplitK GEMM 内核。Granite-8B 和 Llama3-8B 的线性层具有以下形状:
| 线性层 | 形状 (in_features, out_features) |
|---|---|
| 融合 QKV 投影 | (4096, 6144) |
| 输出投影 | (4096, 4096) |
| 融合门控 + 向上投影 | (4096, 28672) |
| 向下投影 | (14336, 4096) |
图 4. Granite-8B 和 Llama3-8B 线性层权重矩阵形状
这些线性层中的每一个都具有不同的权重矩阵形状。因此,为了获得最佳性能,必须针对每个形状配置文件调优 Triton 内核。在对每个线性层进行调优后,我们在 Llama3-8B 和 Granite-8B 上实现了相对于未调优 Triton 内核 1.20 倍 的端到端加速。
6.0 Flash Attention 内核
我们评估了一套现有的 Triton Flash Attention 内核,具有不同的配置,即:
我们评估了每个内核的文本生成质量,首先在 eager 模式下,然后(如果我们能够使用标准方法 torch.compile 内核)在编译模式下。对于内核 2-5,我们注意到以下几点:
| 内核 | 文本生成质量 | Torch.compile | 支持任意序列长度 |
|---|---|---|---|
| AMD Flash | 连贯 | 是 | 是 |
| OpenAI Flash | 不连贯 | 未评估。正在调试 eager 模式下的精度问题 | 否 |
| Dao AI Lab Flash | 不连贯 | 未评估。正在调试 eager 模式下的精度问题 | 是 |
| Xformers FlashDecoding | 在评估文本质量之前遇到编译错误 | 进行中 | 否 (此内核针对解码进行了优化) |
| PyTorch FlexAttention | 连贯 | 进行中 | 进行中 |
图 5. 我们尝试的不同 Flash Attention 内核组合表
上表总结了我们开箱即用的观察结果。经过一些努力,我们预计内核 2-5 可以修改以满足上述标准。然而,这也表明,拥有一个可用于基准测试的内核通常只是将其作为端到端生产内核的开始。
我们选择在后续测试中使用 AMD Flash Attention 内核,因为它可以通过 torch.compile 编译,并在 eager 和编译模式下都能产生清晰的输出。
为了满足 AMD Flash Attention 内核与 torch.compile 的兼容性,我们必须将其定义为 PyTorch 自定义操作符。此过程在此 处 详细解释。该教程链接讨论了如何封装一个简单的图像裁剪操作。然而,我们注意到封装一个更复杂的 Flash Attention 内核遵循类似的过程。两步方法如下:
- 将函数封装为 PyTorch 自定义操作符

- 为操作符添加一个 FakeTensor 内核,该内核在给定 Flash 输入张量(q、k 和 v)的形状的情况下,提供了一种计算 Flash 内核输出形状的方法

将 Triton Flash 内核定义为自定义操作后,我们能够成功地为我们的端到端运行编译它。

图 6. 使用 torch.compile 的 Llama3-8B 跟踪,在替换 Triton 矩阵乘法和 Triton Flash Attention 内核后
从图 5 中,我们注意到,在集成 SplitK 矩阵乘法内核、torch op 封装的 Flash Attention 内核,然后运行 torch.compile 之后,我们现在能够实现一个使用 100% Triton 计算内核的前向传播。
7.0 端到端基准测试
我们使用 Granite-8B 和 Llama3-8B 模型在 NVIDIA H100 和 A100(单 GPU)上进行了端到端测量。我们使用两种不同的配置进行基准测试。
Triton 内核配置使用:
- Triton SplitK GEMM
- AMD Triton Flash Attention
CUDA 内核配置使用:
- cuBLAS GEMM
- cuDNN Flash Attention – 缩放点积注意力(SDPA)
我们在 eager 和 torch 编译模式下,使用典型的推理设置,发现了以下吞吐量和 token 间延迟:
| GPU | 模型 | 内核配置 | 中位数延迟(Eager)[ms/tok] | 中位数延迟(编译)[ms/tok] |
|---|---|---|---|---|
| H100 | Granite-8B | Triton | 27.42 | 11.59 |
| CUDA | 18.84 | 9.50 | ||
| Llama3-8B | Triton | 20.36 | 10.61 | |
| CUDA | 16.59 | 8.59 | ||
| A100 | Granite-8B | Triton | 53.44 | 16.88 |
| CUDA | 37.13 | 14.25 | ||
| Llama3-8B | Triton | 44.44 | 17.94 | |
| CUDA | 32.45 | 12.96 |
图 7. Granite-8B 和 Llama3-8B 在 H100 和 A100 上的单 token 生成延迟,
(批处理大小 = 2,输入序列长度 = 512,输出序列长度 = 256)
总而言之,Triton 模型在 H100 上可以达到 CUDA 模型性能的 78%,在 A100 上可以达到 82%。
性能差距可以通过我们在下一节中讨论的矩阵乘法和 Flash Attention 的内核延迟来解释。
8.0 微基准测试
| 内核 | Triton [微秒] | CUDA [微秒] |
|---|---|---|
| QKV 投影矩阵乘法 | 25 | 21 |
| Flash Attention | 13 | 8 |
| 输出投影矩阵乘法 | 21 | 17 |
| 门控 + 向上投影矩阵乘法 | 84 | 83 |
| 向下投影矩阵乘法 | 58 | 42 |
图 8. Triton 和 CUDA 内核延迟比较(NVIDIA H100 上的 Llama3-8B)
输入为任意提示(bs=1,提示 = 44 序列长度),解码延迟时间
从以上内容,我们注意到以下几点:
- Triton 矩阵乘法内核比 CUDA 慢 1.2-1.4 倍
- AMD 的 Triton Flash Attention 内核比 CUDA SDPA 慢 1.6 倍
这些结果凸显了需要进一步改进 GEMM 和 Flash Attention 等核心原语内核的性能。我们将此作为未来的研究,因为最近的工作(例如 FlashAttention-3、FlexAttention)提供了更好地利用底层硬件以及我们希望能够在此基础上构建以实现更大加速的 Triton 路径。为了说明这一点,我们将 FlexAttention 与 SDPA 和 AMD 的 Triton Flash 内核进行了比较。
我们正在努力验证 FlexAttention 的端到端性能。目前,Flex 的初步微基准测试显示,在较长的上下文长度和解码问题形状(其中查询向量较小)方面有很大的潜力。
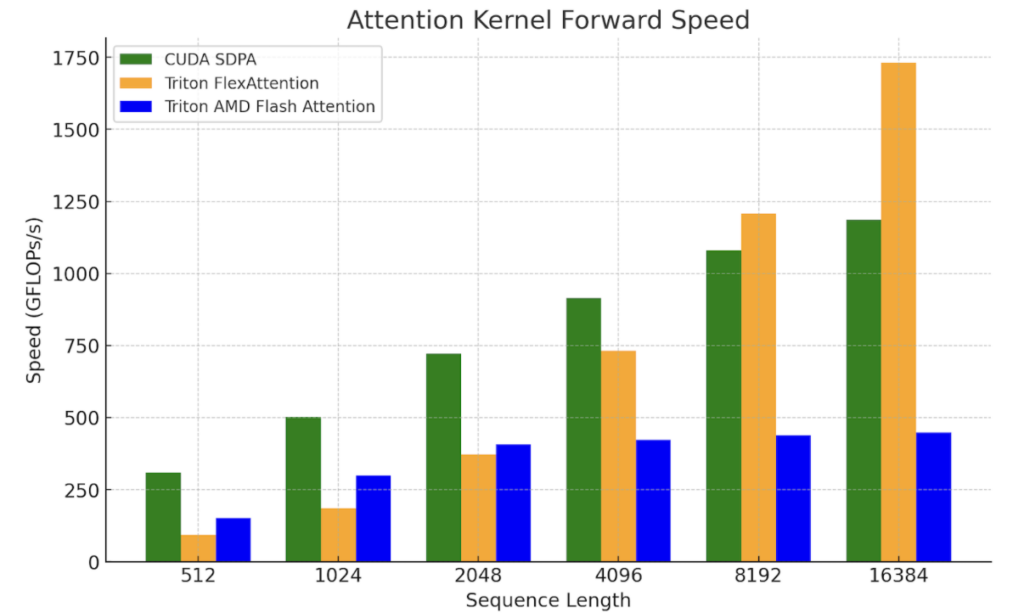
图 9. NVIDIA H100 SXM5 80GB 上的 FlexAttention 内核基准测试
(批处理=1,头数=32,序列长度=序列长度,头维度=128)
9.0 未来工作
对于未来的工作,我们计划探索进一步优化我们的矩阵乘法的方法,以更好地利用硬件,例如我们发布的关于 利用 TMA for H100 的这篇博客,以及不同的工作分解(如 StreamK 等持久内核技术),以在我们基于 Triton 的方法中获得更大的加速。对于 Flash Attention,我们计划探索 FlexAttention 和 FlashAttention-3,因为这些内核中使用的技术可以用来进一步缩小 Triton 和 CUDA 之间的差距。
我们还注意到,我们之前的工作已经显示了 FP8 Triton GEMM 内核性能与 cuBLAS FP8 GEMM 相比的良好结果,因此在未来的帖子中,我们将探索端到端 FP8 LLM 推理。