训练大型深度学习模型需要大型数据集。Amazon Simple Storage Service (Amazon S3) 是一种可扩展的云对象存储服务,用于存储大型训练数据集。机器学习 (ML) 从业者需要一种高效的数据管道,能够从 Amazon S3 下载数据,转换数据,并将数据馈送到 GPU 以高吞吐量和低延迟地训练模型。
在本文中,我们介绍了 PyTorch 的新 S3 IO DataPipes,即 S3FileLister 和 S3FileLoader。为了提高内存效率和运行速度,新的 DataPipes 使用 C++ 扩展来访问 Amazon S3。基准测试显示,与 FSSpecFileOpener 相比,S3FileLoader 从 Amazon S3 下载自然语言处理 (NLP) 数据集的速度快 59.8%。您可以使用新的 DataPipes 构建 IterDataPipe 训练管道。我们还证明了新的 DataPipe 可以将 Bert 和 ResNet50 的总训练时间减少 7%。新的 DataPipes 已作为开源 TorchData 0.4.0 的一部分随 PyTorch 1.12.0 发布。
概述
Amazon S3 是一种可扩展的云存储服务,对数据量没有限制。从 Amazon S3 加载数据并将其馈送到 NVIDIA A100 等高性能 GPU 可能具有挑战性。它需要一个高效的数据管道,能够满足 GPU 的数据处理速度。为了解决这个问题,我们为 PyTorch 发布了一个新的高性能工具:S3 IO DataPipes。DataPipes 是从 torchdata.datapipes.iter.IterDataPipe 继承的子类,因此它们可以与 IterableDataPipe 接口交互。开发人员可以快速构建他们的 DataPipe DAG,以使用 shuffle、sharding 和 batch 功能访问、转换和操作数据。
新的 DataPipes 被设计为文件格式无关的,Amazon S3 数据以二进制大对象 (BLOB) 的形式下载。它可以用作可组合的构建块,以组装一个 DataPipe 图,将表格、NLP 和计算机视觉 (CV) 数据加载到您的训练管道中。
在底层,新的 S3 IO DataPipes 采用 C++ S3 处理程序和 AWS C++ SDK。通常,与 Python 相比,C++ 实现的内存效率更高,并且在线程中具有更好的 CPU 核心利用率(没有全局解释器锁)。建议将新的 C++ S3 IO DataPipes 用于在训练大型深度学习模型时实现高吞吐量、低延迟的数据加载。
新的 S3 IO DataPipes 提供两个一流的 API
- S3FileLister – 可迭代对象,列出给定 S3 前缀内的 S3 文件 URL。此 API 的功能名称为
list_files_by_s3。 - S3FileLoader – 可迭代对象,从给定 S3 前缀加载 S3 文件。此 API 的功能名称为
load_files_by_s3。
用法
在本节中,我们提供了使用新的 S3 IO DataPipes 的说明。我们还提供了 load_files_by_s3() 的代码片段。
从源代码构建
新的 S3 IO DataPipes 使用 C++ 扩展。它默认内置于 torchdata 包中。但是,如果新的 DataPipes 在环境中不可用,例如 Conda 上的 Windows,则需要从源代码构建。有关更多信息,请参阅 Iterable Datapipes。
配置
Amazon S3 支持全球存储桶。但是,存储桶是在区域内创建的。您可以通过使用 __init__() 将区域传递给 DataPipes。或者,您可以在 shell 中 export AWS_REGION=us-west-2,或者在代码中通过 os.environ['AWS_REGION'] = 'us-east-1' 设置环境变量。
要读取不可公开访问的存储桶中的对象,您必须通过以下方法之一提供 AWS 凭据
- 安装并配置 AWS Command Line Interface (AWS CLI) 并使用
AWS configure - 在本地系统上的 AWS 凭据配置文件中设置凭据,该文件位于 Linux、macOS 或 Unix 上的
~/.aws/credentials - 设置
AWS_ACCESS_KEY_ID和AWS_SECRET_ACCESS_KEY环境变量 - 如果您在 Amazon Elastic Compute Cloud (Amazon EC2) 实例上使用此库,请指定一个 AWS Identity and Access Management (IAM) 角色,然后授予 EC2 实例访问该角色的权限
示例代码
以下代码片段提供了 load_files_by_s3() 的典型用法
from torch.utils.data import DataLoader
from torchdata.datapipes.iter import IterableWrapper
s3_shard_urls = IterableWrapper(["s3://bucket/prefix/",])
.list_files_by_s3()
s3_shards = s3_shard_urls.load_files_by_s3()
# text data
training_data = s3_shards.readlines(return_path=False)
data_loader = DataLoader(
training_data,
batch_size=batch_size,
num_workers=num_workers,
)
# training loop
for epoch in range(epochs):
# training step
for bach_data in data_loader:
# forward pass, backward pass, model update
基准测试
在本节中,我们将演示新的 DataPipe 如何减少 Bert 和 ResNet50 的总训练时间。
独立 DataLoader 性能评估与 FSSpec 的比较
FSSpecFileOpener 是另一个 PyTorch S3 DataPipe。它使用 botocore 和 aiohttp/asyncio 来访问 S3 数据。以下是性能测试设置和结果(引自 基于原生 AWSSDK 和 FSSpec (boto3) 的 DataPipes 的性能比较)。
测试中的 S3 数据是一个分片的文本数据集。每个分片大约有 100,000 行,每行大约 1.6 KB,使每个分片大约 156 MB。此基准测试中的测量结果是 1,000 个批次上的平均值。没有执行 shuffling、sampling 或 transforms。
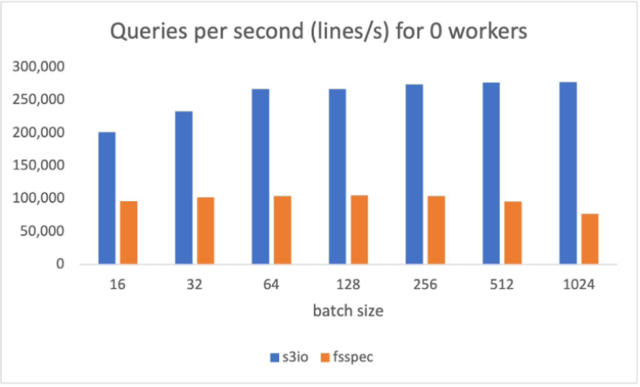
下图报告了 num_workers=0(数据加载器在主进程中运行)在各种批大小下的吞吐量比较。S3FileLoader 具有更高的每秒查询数 (QPS)。在批大小为 512 时,它比 fsspec 高 90%。
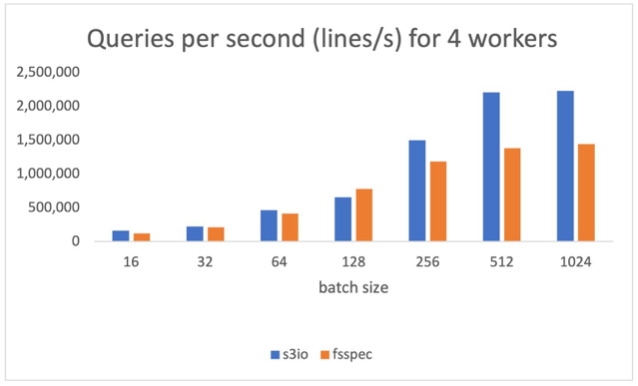
下图报告了 num_workers=4(数据加载器在主进程中运行)的结果。在批大小为 512 时,S3FileLoader 比 fsspec 高 59.8%。
训练 ResNet50 模型与 Boto3 的比较
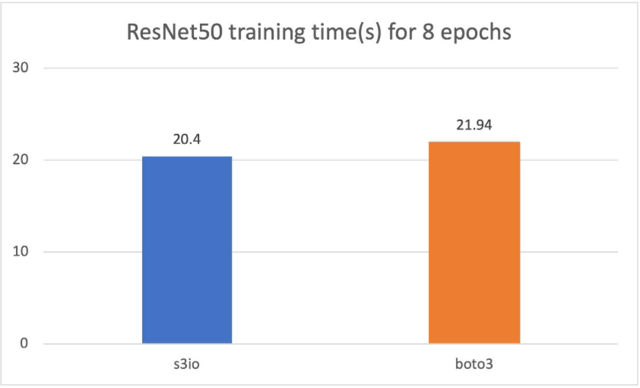
对于下图,我们在一个由 4 个 p3.16xlarge 实例组成的集群上训练了一个 ResNet50 模型,总共有 32 个 GPU。训练数据集是 ImageNet,包含 120 万张图像,组织成 1,000 张图像的分片。训练批大小为 64。训练时间以秒为单位测量。对于八个 epoch,S3FileLoader 比 Boto3 快 7.5%。
训练 Bert 模型与 Boto3 的比较
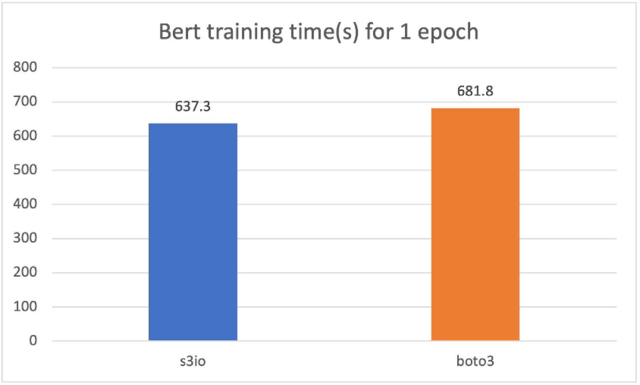
对于下图,我们在一个由 4 个 p3.16xlarge 实例组成的集群上训练了一个 Bert 模型,总共有 32 个 GPU。训练语料库有 1474 个文件。每个文件大约有 150,000 个样本。为了运行更短的 epoch,我们每个文件使用 0.05%(大约 75 个样本)。批大小为 2,048。训练时间以秒为单位测量。对于一个 epoch,S3FileLoader 比 Boto3 快 7%。
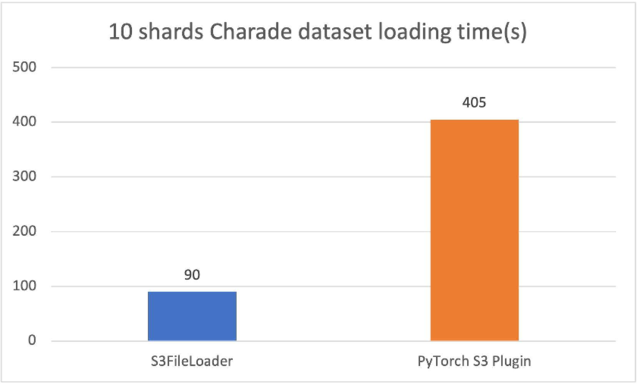
与原始 PyTorch S3 插件的比较
新的 PyTorch S3 DataPipes 的性能大大优于原始 PyTorch S3 插件。我们已为 S3FileLoader 调整了内部缓冲区大小。加载时间以秒为单位测量。
对于 10 个分片的 Charades 文件(每个文件大约 1.5 GiB),S3FileLoader 在我们的实验中快了 3.5 倍。
最佳实践
训练大型深度学习模型可能需要一个由数十甚至数百个节点组成的庞大计算集群。集群中的每个节点可能会生成大量数据加载请求,这些请求会命中特定的 S3 分片。为了避免节流,我们建议在 S3 存储桶和 S3 文件夹之间分片训练数据。
为了获得良好的性能,文件大小要足够大,以便在给定文件上并行化,但又不能太大,以免根据训练任务达到 Amazon S3 上该对象的吞吐量限制。最佳大小可以在 50-200 MB 之间。
结论和后续步骤
在本文中,我们向您介绍了新的 PyTorch IO DataPipes。新的 DataPipes 使用 aws-sdk-cpp,并显示出比基于 Boto3 的数据加载器更好的性能。
对于后续步骤,我们计划通过关注以下功能来改进可用性、性能和功能
- 使用 IAM 角色进行 S3 授权 – 目前,S3 DataPipes 支持显式访问凭据、实例配置文件和 S3 存储桶策略。但是,在某些用例中,IAM 角色是首选。
- 双重缓冲 – 我们计划提供双重缓冲以支持多 worker 下载。
- 本地缓存 – 我们计划使模型训练能够对训练数据集进行多次遍历。第一个 epoch 后的本地缓存可以消除 Amazon S3 的传输延迟,这可以显著加快后续 epoch 的数据检索时间。
- 可自定义配置 – 我们计划公开更多参数,例如内部缓冲区大小、多部分块大小和执行器计数,并允许用户进一步调整数据加载效率。
- Amazon S3 上传 – 我们计划扩展 S3 DataPipes 以支持检查点上传。
- 与 fsspec 合并 –
fsspec用于torch.save()等其他系统。我们可以将新的 S3 DataPipes 与fsspec集成,以便它们可以有更多的用例。
致谢
我们要感谢 Amazon 的 Vijay Rajakumar 和 Kiuk Chung 为 S3 Common RunTime 和 PyTorch DataLoader 提供了指导。我们还要感谢 Meta AI/ML 的 Erjia Guan、Kevin Tse、Vitaly Fedyunin、Mark Saroufim、Hamid Shojanazeri、Matthias Reso 和 Geeta Chauhan,以及 AWS 的 Joe Evans 对博客和 GitHub PRs 的审阅。