引言
完整准确的临床文档是跟踪患者护理的重要工具。它允许护理团队之间共享治疗计划,以帮助实现护理连续性,并确保透明有效的报销流程。
医生负责记录患者护理。传统的临床文档方法导致患者与医生体验不佳,与患者互动时间减少,工作与生活平衡下降。医生花费大量时间在电脑前处理行政任务。结果是,患者对整体体验的满意度降低,而多年学习医学的医生却无法充分发挥其专业能力,并感到倦怠。医生每与患者进行一小时的直接临床面对面交流,就需要在诊所内额外花费近两小时用于 EHR 和案头工作。在非办公时间,医生每晚还要花费 1 到 2 小时个人时间进行额外的电脑及其他文书工作。
- 42% 的医生报告有倦怠感。——Medscape
- 由于疫情,问题变得更加严重,目前有 64% 的美国医生报告有倦怠感。——AAFP
- “过多的官僚任务,例如图表制作和文书工作”是导致倦怠的主要原因,计算机化程度提高排第四位。——Medscape
- 75% 的美国消费者希望他们的医疗体验更个性化,——Business Wire
- 如果沟通体验更个性化,61% 的患者会更频繁地去看医生。——Business Wire
医生倦怠是导致医疗错误增加、医疗事故诉讼、人员流失和就医机会减少的主要原因之一。倦怠导致医疗成本增加和患者总体满意度下降。倦怠每年给美国造成 46 亿美元的损失。
我们能做些什么来让医疗服务重新找回信任、乐趣和人性?很大一部分行政工作包括将患者数据输入电子健康记录 (EHR) 和创建临床文档。临床文档是根据 EHR 中的现有信息以及患者与医生交流对话创建的。
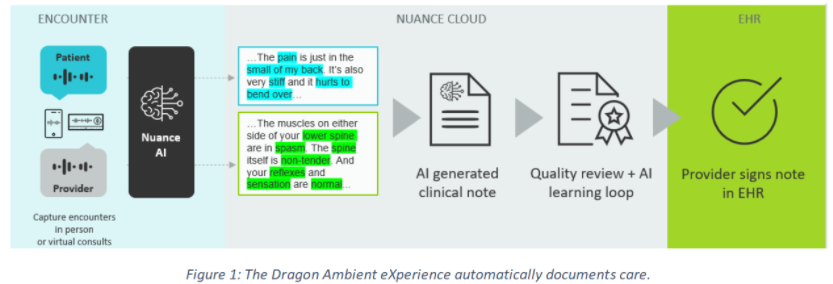
本文将展示 Nuance Dragon Ambient eXperience (DAX) 如何在护理点自动准确高效地记录患者就诊情况,以及实现这一目标的技术。DAX 是一种由人工智能驱动、支持语音的环境临床智能解决方案。
Nuance DAX 提高了护理质量和患者体验,提升了医生的效率和满意度,并改善了财务状况。它可用于办公室和远程医疗环境,适用于所有门诊专科,包括初级保健和紧急护理。
自然语言处理
自然语言处理 (NLP) 是人工智能 (AI) 中最具挑战性的领域之一。它包含一组算法,允许计算机理解或生成人类使用的语言。这些算法可以处理和分析来自不同来源(声音或文本)的大量自然语言数据,以构建能够像人类一样理解、分类甚至生成自然语言的模型。像人工智能其他领域一样,NLP 受益于深度学习 (DL) 的出现,取得了显著进展,导致模型在某些任务中能够获得与人类相当的结果。
这些先进的自然语言处理技术正在医疗保健领域应用。在典型的患者与医生会面中,会进行一次对话,医生通过提问和回答,构建患者当前疾病或症状发展的时间顺序描述。医生检查患者并做出临床决策,以确定诊断和治疗方案。这种对话以及 EHR 中的数据,为医生生成临床文档(称为医疗报告)提供了所需的信息。
两个主要的自然语言处理组件在自动化临床文档创建中发挥作用。第一个组件是自动语音识别 (ASR),用于将语音转换为文本。它接收会面的录音并生成对话转录(参见图 2)。第二个组件是自动文本摘要,有助于从大量文本文档中生成摘要。该组件负责理解和捕捉转录对话中的细微差别和最基本方面,形成叙述形式(参见图 3)、结构化形式或两者结合的最终报告。
我们将重点关注第二个组件,即自动文本摘要,这是一项困难重重且充满挑战的任务
- 其性能与来自多个说话者的 ASR 质量(嘈杂输入)相关联。
- 输入具有对话性质,包含非专业术语。
- 受保护健康信息 (PHI) 法规限制医疗数据访问。
- 一个输出句子的信息可能分散在多个对话轮次中。
- 输入和输出之间没有明确的句子对齐。
- 各种医学专业、就诊类型和 EHR 系统构成了广泛而复杂的输出空间。
- 医生进行就诊的方式各不相同,对医疗报告也有自己的偏好;没有统一的标准。
- 标准摘要指标可能与人类对质量的判断不同。

图 2:患者与医生对话的转录
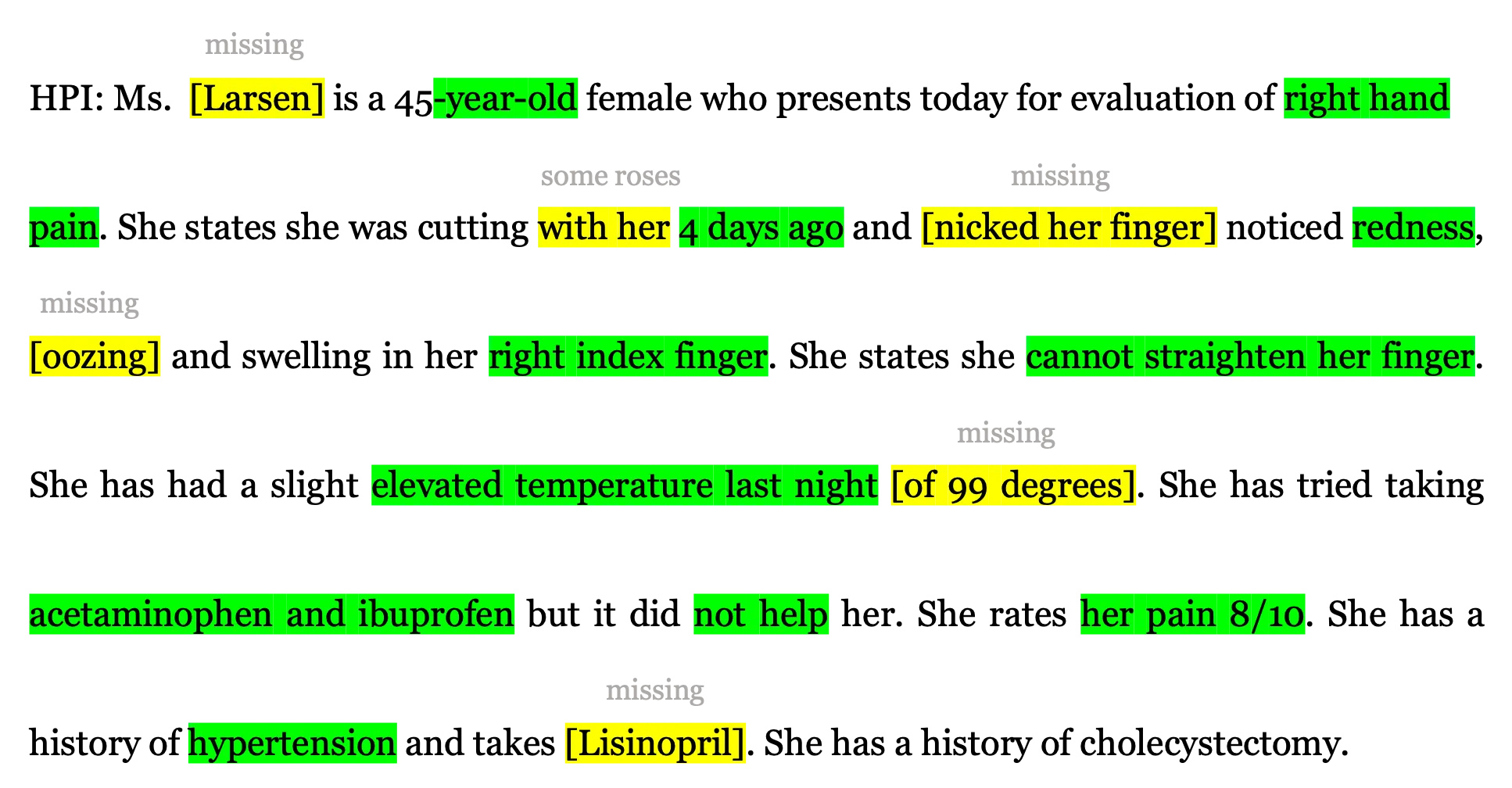
图 3:人工智能生成的医疗报告摘录。HPI 代表现病史。
使用 PyTorch 和 Fairseq 进行文本摘要
PyTorch 是一个由 Facebook 开发的开源机器学习框架,可帮助研究人员对深度学习模型进行原型设计。Fairseq 工具包建立在 PyTorch 之上,专注于序列生成任务,例如神经机器翻译 (NMT) 或文本摘要。Fairseq 拥有一个活跃的社区,不断提供最先进模型的参考实现。它包含许多内置组件(模型架构、模块、损失函数和优化器),并且易于通过插件进行扩展。
文本摘要是自然语言处理领域的一项重大挑战。我们需要能够生成文档简短版本同时保留关键点并避免无信息内容的模型。这些挑战可以通过不同的方法解决。1). 抽象式文本摘要旨在训练能够以叙述形式生成摘要的模型。2). 提取式方法,其中模型被训练以从输入文本中选择最重要的部分。3). 两者的结合,即从输入中选择基本部分,然后以抽象式方式进行摘要。因此,摘要可以通过单个端到端网络或作为提取和抽象组件的管道来完成。为此,Fairseq 提供了所有必要的工具,以使我们的工作取得成功。它具有端到端模型,例如经典的 Transformer,不同类型的语言模型以及预训练版本,使研究人员能够专注于最重要的事情——构建生成有价值报告的最新模型。
然而,我们不仅仅是总结转录的对话;我们生成高质量的医疗报告,这需要考虑许多因素。
- 医疗报告的每个部分在内容、结构、流畅性等方面都不同。
- 对话中提到的所有医学事实都应出现在报告中,例如,特定的治疗或剂量。
- 在医疗保健领域,词汇量庞大,模型需要处理医学术语。
- 患者与医生的对话通常比最终报告长得多。
所有这些挑战都要求我们的研究人员进行一系列广泛的实验。得益于 PyTorch 和 Fairseq 的灵活性,他们的生产力大大提高。此外,该生态系统为从构思、实施、实验到最终投入生产提供了便捷的途径。使用多个 GPU 或 CPU 就像为工具提供额外的参数一样简单,并且由于紧密的 Python 集成,PyTorch 代码可以轻松调试。
在持续为开源社区做出贡献的努力中,Nuance 开发了一些功能并将其推送到了 Fairseq GitHub 存储库。这些功能旨在克服一些上述挑战,例如,促进从输入到摘要复制,尤其是罕见或未见过的单词,通过改进 Tensor Core 利用率来提高训练速度,以及确保不同 Transformer 配置的 TorchScript 兼容性。接下来,我们将展示如何使用 Pointer Generator 机制(Transformer-PG)训练 Transformer 模型的一个示例,该机制可以从输入中复制单词。
如何构建带有指针生成器机制的 Transformer 模型
在此分步指南中,假设用户已安装 PyTorch 和 Fairseq。
1. 创建词汇表并用源位置标记扩展它:
这些标记将允许模型指向输入序列中的任何单词。
vocab_size=<vocab_size>
position_markers=512
export LC_ALL=C
cat train.src train.tgt |
tr -s '[:space:]' '\n' |
sort |
uniq -c |
sort -k1,1bnr -k2 |
head -n "$((vocab_size - 4))" |
awk '{ print $2 " " $1 }' > dict.pg.txt
python3 -c "[print('<unk-{}> 0'.format(n)) for n in range($position_markers)]" >> dict.pg.txt
这将创建一个名为“dict.pg.txt”的文件,其中包含
如果我们的输入是
src = "Hello, I'm The Dogtor"
可能会发生我们的模型在训练时词汇表中没有“Dogtor”这个词。因此,当我们把这个序列输入模型时,它应该被转换为
src = "Hello, I'm The <unk-3>"
现在,“
2. 预处理文本数据,用其位置标记替换未知词:
我们可以使用来自https://github.com/pytorch/fairseq/tree/master/examples/pointer_generator 的脚本。
# Considering we have our data in:
# train_src = /path/to/train.src
# train_tgt = /path/to/train.tgt
# valid_src = /path/to/valid.src
# valid_tgt = /path/to/valid.tgt
./preprocess.py --source /path/to/train.src \
--target /path/to/train.tgt \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/train.pg.src \
--target-out /path/to/train.pg.tgt
./preprocess.py --source /path/to/valid.src \
--target /path/to/valid.tgt \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/valid.pg.src \
--target-out /path/to/valid.pg.tgt
./preprocess.py --source /path/to/test.src \
--vocab <(cut -d' ' -f1 dict.pg.txt) \
--source-out /path/to/test.pg.src
3. 现在让我们将数据二进制化,以便更快地处理:
fairseq-preprocess --task "translation" \
--source-lang "pg.src" \
--target-lang "pg.tgt" \
--trainpref /path/to/train \
--validpref /path/to/valid \
--srcdict dict.pg.txt \
--cpu \
--joined-dictionary \
--destdir <data_dir>
您可能会注意到任务类型是“翻译”。这是因为没有可用的“摘要”任务;我们可以将其理解为一种 NMT 任务,其中输入和输出语言是共享的,并且输出(摘要)比输入短。
4. 现在我们可以训练模型了:
fairseq-train <data_dir> \
--save-dir <model_dir> \
--task "translation" \
--source-lang "src" \
--target-lang "tgt" \
--arch "transformer_pointer_generator" \
--max-source-positions 512 \
--max-target-positions 128 \
--truncate-source \
--max-tokens 2048 \
--required-batch-size-multiple 1 \
--required-seq-len-multiple 8 \
--share-all-embeddings \
--dropout 0.1 \
--criterion "cross_entropy" \
--optimizer adam \
--adam-betas '(0.9, 0.98)' \
--adam-eps 1e-9 \
--update-freq 4 \
--lr 0.004 \
# Pointer Generator
--alignment-layer -1 \
--alignment-heads 1 \
--source-position-markers 512
此配置利用了 Nuance 回馈 Fairseq 的功能
- 带有指针生成器机制的 Transformer,以方便从输入中复制单词。
- 序列长度填充为 8 的倍数,以更好地利用 Tensor Core 并减少训练时间。
5. 现在让我们看看如何使用我们新的医疗报告生成系统生成摘要:
import torch
from examples.pointer_generator.pointer_generator_src.transformer_pg import TransformerPointerGeneratorModel
# Patient-Doctor conversation
input = "[doctor] Lisa Simpson, thirty six year old female, presents to the clinic today because " \
"she has severe right wrist pain"
# Load the model
model = TransformerPointerGeneratorModel.from_pretrained(data_name_or_path=<data_dir>,
model_name_or_path=<model_dir>,
checkpoint_file="checkpoint_best.pt")
result = model.translate([input], beam=2)
print(result[0])
Ms. <unk-2> is a 36-year-old female who presents to the clinic today for evaluation of her right wrist.
6. 另外,我们可以使用 fairseq-interactive 和一个后处理工具,用输入中的单词替换位置未知标记:
fairseq-interactive <data_dir> \
--batch-size <batch_size> \
--task translation \
--source-lang src \
--target-lang tgt \
--path <model_dir>/checkpoint_last.pt \
--input /path/to/test.pg.src \
--buffer-size 20 \
--max-len-a 0 \
--max-len-b 128 \
--beam 2 \
--skip-invalid-size-inputs-valid-test | tee generate.out
grep "^H-" generate.out | cut -f 3- > generate.hyp
./postprocess.py \
--source <(awk 'NF<512' /path/to/test.pg.src) \
--target generate.hyp \
--target-out generate.hyp.processed
现在我们有了“generate.hyp.processed”中的最终报告集,其中“
模型部署
PyTorch 在建模方面提供了极大的灵活性和丰富的周边生态系统。然而,尽管最近有几篇文章表明 PyTorch 在研究和学术领域的使用可能接近超越 TensorFlow,但总体而言,TensorFlow 似乎仍然是生产部署的首选平台。在 2021 年,情况仍然如此吗?希望在生产环境中部署 PyTorch 模型的团队有几种选择。
在描述我们的旅程之前,让我们先简要绕道,定义一下“模型”一词。
模型即计算图
几年前,机器学习工具包通常只支持具有相当固定和僵硬结构的特定模型类别,只有少数自由度(如支持向量机的核或神经网络的隐藏层数)。受 Theano 基础工作的启发,微软的 CNTK 或谷歌的 TensorFlow 等工具包率先推广了更灵活的模型视图,即模型是具有相关参数的计算图,这些参数可以从数据中估计。这种视图模糊了流行模型类型(如 DNN 或 SVM)之间的界限,因为很容易将每种模型的特征融入到您自己的图类型中。然而,这样的图在估计其参数之前必须预先定义,而且它是相当静态的。这使得将模型保存到自包含的包中变得容易,例如 TensorFlow SavedModel(这样的包只包含图的结构以及估计参数的具体值)。然而,调试这样的模型可能很困难,因为构建图的 Python 代码中的语句与执行图的代码行在逻辑上是分离的。研究人员也渴望更简单的方法来表达动态行为,例如模型正向传播的计算步骤有条件地依赖于其输入数据(或其先前的输出)。
最近,上述限制导致了由 PyTorch 和 TensorFlow 2 率先发起的第二次革命。计算图不再显式定义。相反,它将在 Python 代码对张量参数执行操作时隐式填充。推动这一发展的一项重要技术是自动微分。随着计算图在执行正向传播步骤时隐式构建,所有必要的数据将被跟踪,以便稍后计算关于模型参数的梯度。这为训练模型提供了极大的灵活性,但也提出了一个重要问题。如果模型内部发生的计算仅通过我们的 Python 代码在执行具体数据时的步骤隐式定义,那么我们想要保存的模型是什么?答案——至少最初是——Python 代码及其所有依赖项,以及估计的参数。这出于实际原因是不理想的。例如,模型部署团队可能无法精确复制训练期间使用的 Python 代码依赖项,从而导致细微的行为差异。解决方案通常包括结合两种技术:脚本化和跟踪,即在 Python 代码中进行额外注释,并根据示例输入数据执行代码,允许 PyTorch 定义和保存应在后续对新的、未见过的数据进行推断时执行的图。这要求创建模型代码的人具备一定的纪律(可以说这抵消了即时执行的一些原始灵活性),但它会生成 TorchScript 格式的自包含模型包。TensorFlow 2 中的解决方案也惊人地相似。
服务我们的报告生成模型
我们部署报告生成模型的旅程反映了上述讨论。我们最初通过将模型代码及其依赖项以及参数检查点部署到公开 gRPC 服务接口的自定义 Docker 镜像中来提供我们的模型。然而,我们很快发现,在估计参数时复制建模团队使用的确切代码和环境变得容易出错。此外,这种方法阻碍了我们利用 NVIDIA Triton 等高性能模型服务框架,该框架是用 C++ 编写的,需要无需 Python 解释器即可使用的自包含模型。在此阶段,我们面临着将 PyTorch 模型导出为 ONNX 或 TorchScript 格式的选择。ONNX 是一种表示机器学习模型的开放规范,其采用率日益增长。它由微软开发的高性能运行时 (ONNX Runtime) 提供支持。虽然我们能够使用 ONNX Runtime 加速我们的基于 TensorFlow BERT 的模型,但当时我们的一个 PyTorch 模型需要一些 ONNX 尚未支持的操作符。我们没有使用自定义操作符来实现这些操作符,而是决定暂时研究 TorchScript。
一个不断成熟的生态系统
一切都顺利吗?不,这是一段比我们预期更艰难的旅程。我们在直接提供 PyTorch 代码时,遇到了 PyTorch 使用的 MKL 库似乎存在内存泄漏的问题。在尝试从多个线程加载多个模型时,我们遇到了死锁。我们在将模型导出到 ONNX 和 TorchScript 格式时遇到了困难。模型无法在具有多个 GPU 的硬件上开箱即用,它们总是访问导出它们的特定 GPU 设备。在提供 TorchScript 模型时,我们在 Triton 推理服务器中遇到了过多的内存使用,我们发现这是由于在正向传播期间意外启用了自动微分。然而,生态系统不断改进,并且有一个乐于助人、充满活力的开源社区渴望与我们合作解决这些问题。
何去何从?对于那些需要直接提供 PyTorch 代码的灵活性,而无需额外导出自包含模型的人来说,值得指出的是,TorchServe 项目现在提供了一种将代码与参数检查点捆绑到一个可提供服务的存档中的方法,大大降低了代码和参数分离的风险。然而,对我们来说,将模型导出到 TorchScript 已经证明是有益的。它为建模和部署团队提供了清晰的接口,并且 TorchScript 通过其即时编译引擎进一步减少了在 GPU 上提供模型时的延迟。
大规模扩展与未来
最后,高效地部署到云端不仅仅是高效地计算单个模型实例的响应。在管理、版本控制和更新模型方面需要灵活性。必须通过负载均衡、水平扩展和垂直扩展等技术实现高层次的可扩展性。如果涉及许多模型,快速缩放至零很快成为一个话题,因为为不响应任何请求的模型付费是不可接受的。在 Triton 等底层推理服务器之上提供这种额外功能是编排框架的工作。在获得一些 KubeFlow 的初步经验后,为此,我们决定将注意力转向 Azure ML,它提供类似的功能,但与 Azure 平台集成更深,而我们已经严重依赖该平台的大部分技术栈。我们旅程的这一部分才刚刚开始。
结论
学术界早就认识到我们“站在巨人的肩膀上”。随着人工智能从一门科学学科走向技术成熟,最初推动其科学基础的合作精神也延续到了软件工程领域。世界各地的开源爱好者加入科技公司,共同构建开放的软件生态系统,为解决现代社会一些最紧迫的挑战提供了新的视角。在本文中,我们探讨了 Nuance 的Dragon Ambient eXperience,这是一个由人工智能驱动、支持语音的解决方案,可自动记录患者护理,从而减轻医疗服务提供者的行政负担。Nuance DAX 改善了患者与医生之间的体验,减少了医生的倦怠,并改善了财务状况。它将信任、乐趣和人性带回了医疗服务。Fairseq 和 PyTorch 已被证明是支持这项人工智能技术的出色平台,反过来,Nuance 也回馈了该领域的一些创新。如需进一步阅读,我们邀请您查看我们最近的ACL 出版物和 Nuance 的“What’s Next”博客。