多模型端点 (MME) 是 Amazon SageMaker 的强大功能,旨在简化机器学习 (ML) 模型的部署和操作。通过 MME,您可以在单个服务容器上托管多个模型,并将所有模型托管在单个端点之后。SageMaker 平台自动管理模型的加载和卸载,并根据流量模式扩展资源,从而减少管理大量模型的运营负担。此功能特别适用于需要加速计算的深度学习和生成式 AI 模型。通过资源共享和简化的模型管理实现的成本节约,使 SageMaker MME 成为您在 AWS 上大规模托管模型的绝佳选择。
最近,生成式 AI 应用引起了广泛关注和想象。客户希望在 GPU 上部署生成式 AI 模型,但同时又关注成本。SageMaker MME 支持 GPU 实例,是此类应用的绝佳选择。今天,我们很高兴地宣布 SageMaker MME 支持 TorchServe。这种新的模型服务器支持让您在享受 MME 所有优势的同时,仍然可以使用 TorchServe 客户最熟悉的服务堆栈。在这篇文章中,我们将演示如何使用 TorchServe 在 SageMaker MME 上托管生成式 AI 模型(例如 Stable Diffusion 和 Segment Anything Model),并构建一个语言引导的编辑解决方案,以帮助艺术家和内容创作者更快地开发和迭代他们的作品。
解决方案概述
语言引导编辑是一个常见的跨行业生成式 AI 用例。它可以通过自动化重复任务、优化活动和为最终客户提供超个性化体验来帮助艺术家和内容创作者更高效地工作,以满足内容需求。企业可以从增加内容输出、节省成本、改进个性化和增强客户体验中获益。在这篇文章中,我们将演示如何使用 MME TorchServe 构建语言辅助编辑功能,让您可以通过提供文本指令来从图像中擦除任何不需要的对象,以及修改或替换图像中的任何对象。
每个用例的用户体验流程如下
- 要删除不需要的对象,请从图像中选择该对象以突出显示它。此操作会将像素坐标和原始图像发送到生成式 AI 模型,该模型会为该对象生成一个分割掩码。确认对象选择正确后,您可以将原始图像和掩码图像发送到第二个模型进行删除。下面详细说明了此用户流程。
 |  |  |
| 步骤 1:从图像中选择一个对象(“狗”) | 步骤 2:确认已突出显示正确的对象 | 步骤 3:从图像中擦除该对象 |
- 要修改或替换对象,请选择并突出显示所需对象,遵循与上述相同的过程。确认对象选择正确后,您可以通过提供原始图像、掩码和文本提示来修改对象。然后模型将根据提供的指令更改突出显示的对象。此第二个用户流程的详细说明如下。
 |  |  |
| 步骤 1:从图像中选择一个对象(“花瓶”) | 步骤 2:确认已突出显示正确的对象 | 步骤 3:提供文本提示(“未来派花瓶”)以修改对象 |
为了支持此解决方案,我们使用了三个生成式 AI 模型:Segment Anything Model (SAM)、Large Mask Inpainting Model (LaMa) 和 Stable Diffusion Inpaint (SD)。以下是这些模型在用户体验工作流中的应用方式:
| 删除不需要的对象 | 修改或替换对象 |
 |  |
- Segment Anything Model (SAM) 用于生成感兴趣对象的分割掩码。SAM 由 Meta Research 开发,是一个开源模型,可以分割图像中的任何对象。该模型已在名为 SA-1B 的大型数据集上进行了训练,该数据集包含超过 1100 万张图像和 11 亿个分割掩码。有关 SAM 的更多信息,请参阅其网站和研究论文。
- LaMa 用于从图像中删除任何不需要的对象。LaMa 是一种生成对抗网络 (GAN) 模型,专门用于使用不规则掩码填充图像中缺失的部分。该模型架构结合了图像范围的全局上下文和使用傅里叶卷积的单步架构,使其能够以更快的速度实现最先进的结果。有关 LaMa 的更多详细信息,请访问其网站和研究论文。
- Stability AI 的 SD 2 图像修复模型用于修改或替换图像中的对象。该模型允许我们通过提供文本提示来编辑掩码区域中的对象。图像修复模型基于文本到图像的 SD 模型,该模型可以使用简单的文本提示创建高质量图像。它提供额外的参数,例如原始图像和掩码图像,从而可以快速修改和恢复现有内容。要了解有关 AWS 上 Stable Diffusion 模型的更多信息,请参阅使用 Stable Diffusion 模型创建高质量图像并利用 Amazon SageMaker 以经济高效的方式部署它们。
所有三个模型都托管在 SageMaker MME 上,这减少了管理多个端点的操作负担。此外,使用 MME 消除了对某些模型未充分利用的担忧,因为资源是共享的。您可以从改进的实例饱和度中获益,最终实现成本节约。以下架构图说明了如何使用带有 TorchServe 的 SageMaker MME 提供所有三个模型。
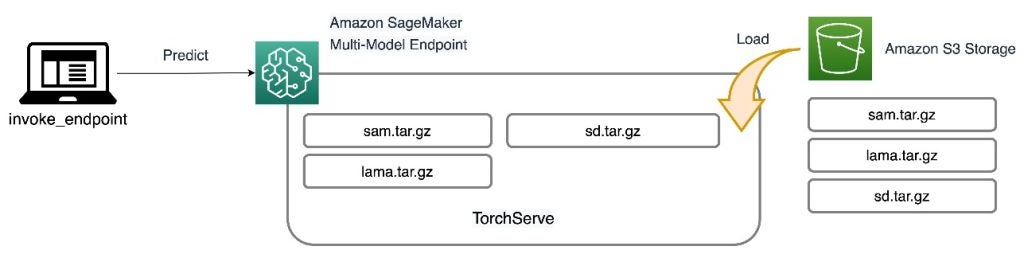
我们已将实现此解决方案架构的代码发布在我们的 GitHub 存储库中。要继续阅读本文的其余部分,请使用笔记本文件。建议在 SageMaker 笔记本实例上使用 conda_python3 (Python 3.10.10) 内核运行此示例。
扩展 TorchServe 容器
第一步是准备模型托管容器。SageMaker 提供了一个托管的 PyTorch 深度学习容器 (DLC),您可以使用以下代码片段进行检索
# Use SageMaker PyTorch DLC as base image
baseimage = sagemaker.image_uris.retrieve(
framework="pytorch",
region=region,
py_version="py310",
image_scope="inference",
version="2.0.0",
instance_type="ml.g5.2xlarge",
)
print(baseimage)
由于模型需要基础 PyTorch DLC 上没有的资源和额外包,因此您需要构建一个 Docker 镜像。然后将此镜像上传到 Amazon Elastic Container Registry (Amazon ECR),以便我们可以直接从 SageMaker 访问。自定义安装的库列在 Docker 文件中
ARG BASE_IMAGE
FROM $BASE_IMAGE
#Install any additional libraries
RUN pip install segment-anything-py==1.0
RUN pip install opencv-python-headless==4.7.0.68
RUN pip install matplotlib==3.6.3
RUN pip install diffusers
RUN pip install tqdm
RUN pip install easydict
RUN pip install scikit-image
RUN pip install xformers
RUN pip install tensorflow
RUN pip install joblib
RUN pip install matplotlib
RUN pip install albumentations==0.5.2
RUN pip install hydra-core==1.1.0
RUN pip install pytorch-lightning
RUN pip install tabulate
RUN pip install kornia==0.5.0
RUN pip install webdataset
RUN pip install omegaconf==2.1.2
RUN pip install transformers==4.28.1
RUN pip install accelerate
RUN pip install ftfy
运行 shell 命令文件以在本地构建自定义镜像并将其推送到 Amazon ECR
%%capture build_output
reponame = "torchserve-mme-demo"
versiontag = "genai-0.1"
# Build our own docker image
!cd workspace/docker && ./build_and_push.sh {reponame} {versiontag} {baseimage} {region} {account}
准备模型工件
支持 TorchServe 的新 MME 的主要区别在于您如何准备模型工件。代码存储库为每个模型(模型文件夹)提供一个骨架文件夹,用于存放 TorchServe 所需的文件。我们遵循相同的四步流程来准备每个模型 .tar 文件。以下代码是 SD 模型骨架文件夹的示例
workspace
|--sd
|-- custom_handler.py
|-- model-config.yaml
第一步是将预训练的模型检查点下载到模型文件夹中
import diffusers
import torch
import transformers
pipeline = diffusers.StableDiffusionInpaintPipeline.from_pretrained(
"stabilityai/stable-diffusion-2-inpainting", torch_dtype=torch.float16
)
sd_dir = "workspace/sd/model"
pipeline.save_pretrained(sd_dir)
下一步是定义 `custom_handler.py` 文件。这需要定义模型在收到请求时的行为,例如加载模型、预处理输入和后处理输出。`handle` 方法是请求的主要入口点,它接受一个请求对象并返回一个响应对象。它加载预训练的模型检查点并将 `preprocess` 和 `postprocess` 方法应用于输入和输出数据。以下代码片段说明了 `custom_handler.py` 文件的简单结构。有关更多详细信息,请参阅 TorchServe 处理程序 API。
def initialize(self, ctx: Context):
def preprocess(self, data):
def inference(self, data):
def handle(self, data, context):
requests = self.preprocess(data)
responses = self.inference(requests)
return responses
TorchServe 所需的最后一个文件是 `model-config.yaml`。该文件定义了模型服务器的配置,例如 worker 数量和批处理大小。配置是按模型级别进行的,以下代码显示了一个示例配置文件。有关参数的完整列表,请参阅 GitHub 存储库。
minWorkers: 1
maxWorkers: 1
batchSize: 1
maxBatchDelay: 200
responseTimeout: 300
最后一步是使用 `torch-model-archiver` 模块将所有模型工件打包成一个 .tar.gz 文件
!torch-model-archiver --model-name sd --version 1.0 --handler workspace/sd/custom_handler.py --extra-files workspace/sd/model --config-file workspace/sam/model-config.yaml --archive-format no-archive!cd sd && tar cvzf sd.tar.gz .
创建多模型端点
创建 SageMaker MME 的步骤与以前相同。在这个特定的示例中,您使用 SageMaker SDK 启动一个端点。首先定义一个 Amazon Simple Storage Service (Amazon S3) 位置和托管容器。SageMaker 将根据调用模式在此 S3 位置动态加载模型。托管容器是您在前面步骤中构建并推送到 Amazon ECR 的自定义容器。请参阅以下代码
# This is where our MME will read models from on S3.
multi_model_s3uri = output_path
然后,您需要定义一个 `MulitDataModel` 来捕获所有属性,例如模型位置、托管容器和权限访问
print(multi_model_s3uri)
model = Model(
model_data=f"{multi_model_s3uri}/sam.tar.gz",
image_uri=container,
role=role,
sagemaker_session=smsess,
env={"TF_ENABLE_ONEDNN_OPTS": "0"},
)
mme = MultiDataModel(
name="torchserve-mme-genai-" + datetime.now().strftime("%Y-%m-%d-%H-%M-%S"),
model_data_prefix=multi_model_s3uri,
model=model,
sagemaker_session=smsess,
)
print(mme)
`deploy()` 函数创建端点配置并托管端点
mme.deploy(
initial_instance_count=1,
instance_type="ml.g5.2xlarge",
serializer=sagemaker.serializers.JSONSerializer(),
deserializer=sagemaker.deserializers.JSONDeserializer(),
)
在我们提供的示例中,我们还展示了如何使用 SDK 列出模型并动态添加新模型。`add_model()` 函数将您的本地模型 `.tar` 文件复制到 MME S3 位置
# Only sam.tar.gz visible!
list(mme.list_models())
models = ["sd/sd.tar.gz", "lama/lama.tar.gz"]
for model in models:
mme.add_model(model_data_source=model)
调用模型
现在我们所有三个模型都托管在 MME 上,我们可以按顺序调用每个模型来构建我们的语言辅助编辑功能。要调用每个模型,请在 `predictor.predict()` 函数中提供 `target_model` 参数。模型名称只是我们上传的模型 `.tar` 文件的名称。以下是 SAM 模型的一个示例代码片段,它接受像素坐标、点标签和膨胀核大小,并生成像素位置处对象的分割掩码
img_file = "workspace/test_data/sample1.png"
img_bytes = None
with Image.open(img_file) as f:
img_bytes = encode_image(f)
gen_args = json.dumps(dict(point_coords=[750, 500], point_labels=1, dilate_kernel_size=15))
payload = json.dumps({"image": img_bytes, "gen_args": gen_args}).encode("utf-8")
response = predictor.predict(data=payload, target_model="/sam.tar.gz")
encoded_masks_string = json.loads(response.decode("utf-8"))["generated_image"]
base64_bytes_masks = base64.b64decode(encoded_masks_string)
with Image.open(io.BytesIO(base64_bytes_masks)) as f:
generated_image_rgb = f.convert("RGB")
generated_image_rgb.show()
要从图像中删除不需要的对象,请将 SAM 生成的分割掩码与原始图像一起输入到 LaMa 模型中。以下图片显示了一个示例。
 |  | |
| 示例图像 | SAM 的分割掩码 | 使用 LaMa 擦除狗 |
要通过文本提示修改或替换图像中的任何对象,请将 SAM 的分割掩码与原始图像和文本提示一起输入到 SD 模型中,如以下示例所示。
| |  |
| 示例图像 | SAM 的分割掩码 | 使用带有文本提示的 SD 模型替换 “长凳上的仓鼠” |
成本节约
SageMaker MME 的优势随着模型整合规模的增加而增加。下表显示了本文中三个模型的 GPU 内存使用情况。它们通过一个 SageMaker MME 部署在一个 `g5.2xlarge` 实例上。
| 模型 | GPU 内存 (MiB) |
| Segment Anything Model | 3,362 |
| Stable Diffusion Inpaint | 3,910 |
| Lama | 852 |
您可以看到,当使用一个端点托管这三个模型时,可以节省成本,对于包含数百或数千个模型的用例,节省的成本会更大。
例如,考虑 100 个 Stable Diffusion 模型。每个模型本身都可以由一个 `ml.g5.2xlarge` 端点(4 GiB 内存)提供服务,在美国东部(弗吉尼亚北部)区域的成本为每实例小时 1.52 美元。如果使用自己的端点提供所有 100 个模型,每月将花费 218,880 美元。使用 SageMaker MME,一个使用 `ml.g5.2xlarge` 实例的单一端点可以同时托管四个模型。这使得生产推理成本降低 75%,每月仅为 54,720 美元。下表总结了此示例中单模型和多模型端点之间的差异。在端点配置具有足够内存以满足您的目标模型需求的情况下,所有模型加载后的稳态调用延迟将与单模型端点相似。
| 单模型端点 | 多模型端点 | |
| 每月总端点价格 | $218,880 | $54,720 |
| 端点实例类型 | ml.g5.2xlarge | ml.g5.2xlarge |
| CPU 内存容量 (GiB) | 32 | 32 |
| GPU 内存容量 (GiB) | 24 | 24 |
| 每小时端点价格 | $1.52 | $1.52 |
| 每个端点的实例数 | 2 | 2 |
| 100 个模型所需的端点 | 100 | 25 |
清理
完成后,请按照笔记本清理部分的说明删除本文中配置的资源,以避免不必要的费用。有关推理实例成本的详细信息,请参阅Amazon SageMaker 定价。
结论
本文展示了通过使用托管在 SageMaker MME 上并带有 TorchServe 的生成式 AI 模型实现的语言辅助编辑功能。我们分享的示例说明了如何在 SageMaker MME 上利用资源共享和简化的模型管理,同时仍使用 TorchServe 作为我们的模型服务堆栈。我们使用了三个深度学习基础模型:SAM、SD 2 Inpainting 和 LaMa。这些模型使我们能够构建强大的功能,例如从图像中擦除任何不需要的对象,并通过提供文本指令修改或替换图像中的任何对象。这些功能可以通过自动化重复任务、优化活动和提供超个性化体验来帮助艺术家和内容创作者更高效地工作并满足其内容需求。我们邀请您探索本文中提供的示例,并使用 SageMaker MME 上的 TorchServe 构建您自己的 UI 体验。
要开始使用,请参阅使用 GPU 支持实例的多模型端点支持的算法、框架和实例。
关于作者

James Wu 是 AWS 的高级 AI/ML 专家解决方案架构师,帮助客户设计和构建 AI/ML 解决方案。James 的工作涵盖广泛的 ML 用例,主要关注计算机视觉、深度学习以及在企业范围内扩展 ML。在加入 AWS 之前,James 担任了 10 多年的架构师、开发人员和技术领导者,其中包括 6 年在工程领域和 4 年在市场营销和广告行业。

李宁是 AWS 的高级软件工程师,专注于构建大规模 AI 解决方案。作为 TorchServe(一个由 AWS 和 Meta 联合开发的项目)的技术负责人,她的热情在于利用 PyTorch 和 AWS SageMaker 帮助客户将 AI 用于更广泛的利益。在专业领域之外,李宁喜欢游泳、旅行、关注最新的技术进展,并与家人共度美好时光。

Ankith Gunapal 是 Meta (PyTorch) 的 AI 合作伙伴工程师。他热衷于模型优化和模型服务,拥有从 RTL 验证、嵌入式软件、计算机视觉到 PyTorch 的丰富经验。他拥有数据科学硕士学位和电信硕士学位。在工作之余,Ankith 还是一名电子舞曲制作人。

Saurabh Trikande 是 Amazon SageMaker Inference 的高级产品经理。他热衷于与客户合作,并以机器学习民主化为目标而受到激励。他专注于部署复杂 ML 应用程序、多租户 ML 模型、成本优化以及使深度学习模型的部署更易于访问等核心挑战。在业余时间,Saurabh 喜欢徒步旅行、了解创新技术、关注 TechCrunch 并与家人共度时光。

Subhash Talluri 是亚马逊网络服务电信行业业务部门的首席 AI/ML 解决方案架构师。他一直致力于为全球电信客户和合作伙伴开发创新的 AI/ML 解决方案。他将工程和计算机科学的跨学科专业知识结合起来,通过 AWS 上云优化架构帮助构建可扩展、安全且合规的 AI/ML 解决方案。