TorchAO 为 Arm CPU 带来了高性能低位线性算子和嵌入算子。在此次更新中,我们很高兴分享三项重大改进:动态内核选择、与 Arm 的 KleidiAI 库集成,以及对量化共享嵌入的支持——所有这些都旨在提升 PyTorch 中低位推理的性能和覆盖范围,包括ExecuTorch,PyTorch 用于高效设备端执行的解决方案。
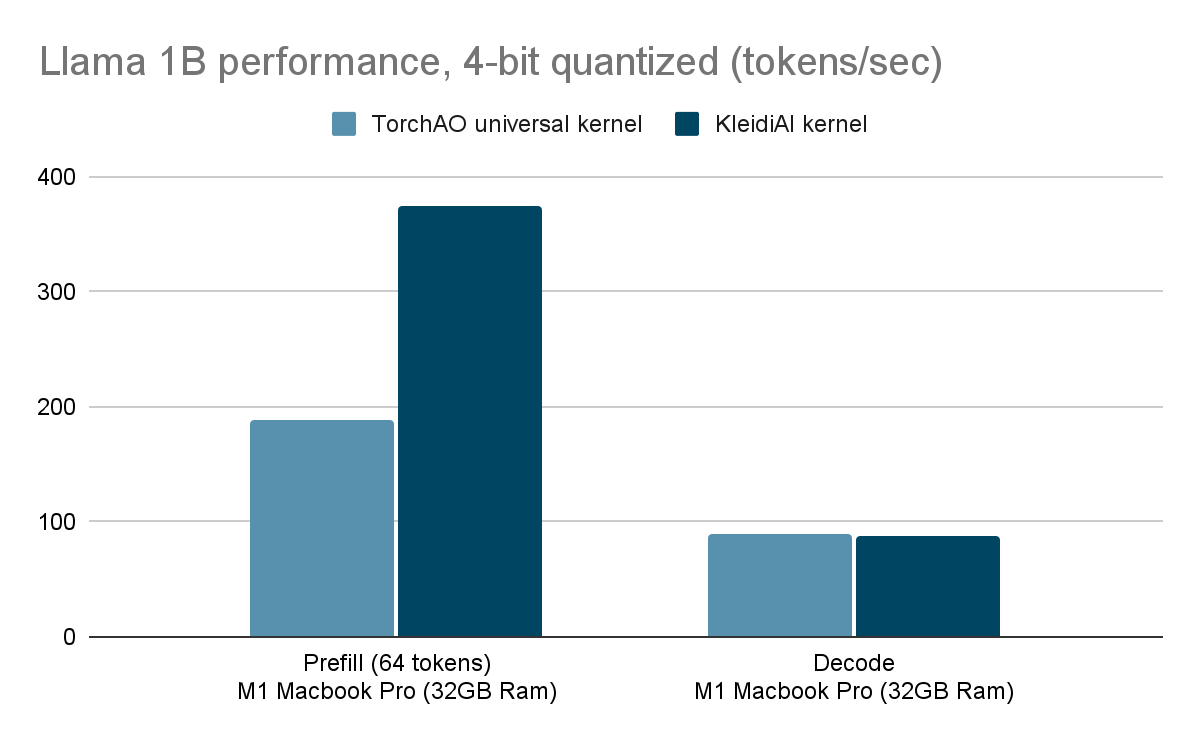
确实,通过 KleidiAI 内核,我们在 M1 Mac 上对 4 位量化的 Llama1B 模型进行预填充时,性能提升了 2 倍以上(373 token/秒)!
动态内核选择
TorchAO 低位算子现在根据以下条件自动选择最佳可用内核:
- 打包权重的格式,
- CPU 功能,例如
has_arm_neon_dot和has_arm_i8mm,以及 - 激活张量的形状。
这种动态调度允许我们根据硬件和工作负载特性来定制执行。
工作原理?
量化模型权重可以打包成针对特定线性内核优化的格式。这些打包的权重包含描述其格式的头部信息。当调用带有打包权重的线性算子时,我们首先检查权重格式和当前 CPU 功能。根据这些信息,我们确定一组可以在权重上操作的兼容内核,并将这些内核的函数指针缓存到注册表中。
例如,以format1打包的权重可能同时支持 GEMV 和 GEMM 内核(例如 gemv_kernel1 和 gemm_kernel1),而以 format2 打包的权重可能只支持 GEMV 内核(例如 gemv_kernel2)。在这种情况下,内核注册表可能如下所示:

下次遇到带有format1的打包权重时,我们可以从表中快速检索兼容的内核,并根据激活的形状调度到适当的内核。如果激活形成一个向量,我们将使用gemv_kernel1;如果它们形成一个矩阵,我们将使用gemm_kernel1。
想看看哪些内核处于活动状态?设置 TORCH_CPP_LOG_LEVEL=INFO 以获取详细视图。
KleidiAI 集成
KleidiAI 是 Arm 提供的一个开源库,它为 Arm CPU 提供高度优化的微内核。我们现在将 KleidiAI 集成到我们的动态内核选择系统中。在支持的情况下(例如,8 位动态激活与 4 位权重),KleidiAI 内核会自动注册和使用。当出现覆盖空白时(例如,非 4 位权重或共享嵌入层),我们会回退到我们内部的 GEMV neondot 内核——无需配置。所有这些都使用前面讨论的打包权重格式完成。
这种混合方法为我们提供了两全其美:KleidiAI 提供顶级性能,而 torchao 的内核提供广泛的算子支持。
借助 KleidiAI,我们观察到解码性能与现有 torchao 内核相当。然而,由于我们没有内部 GEMM 内核,使用 KleidiAI 可显著提升预填充性能——速度提升超过 2 倍,在 M1 Mac 上使用 ExecuTorch 时,速率超过 373 token/秒!
量化共享嵌入和 lm_head 内核
共享嵌入广泛应用于 LLaMA 3.2 和 Phi-4 Mini 等紧凑型 LLM 中。在共享嵌入中,嵌入层的权重与计算 logits 的最终线性层(lm_head)的权重共享:
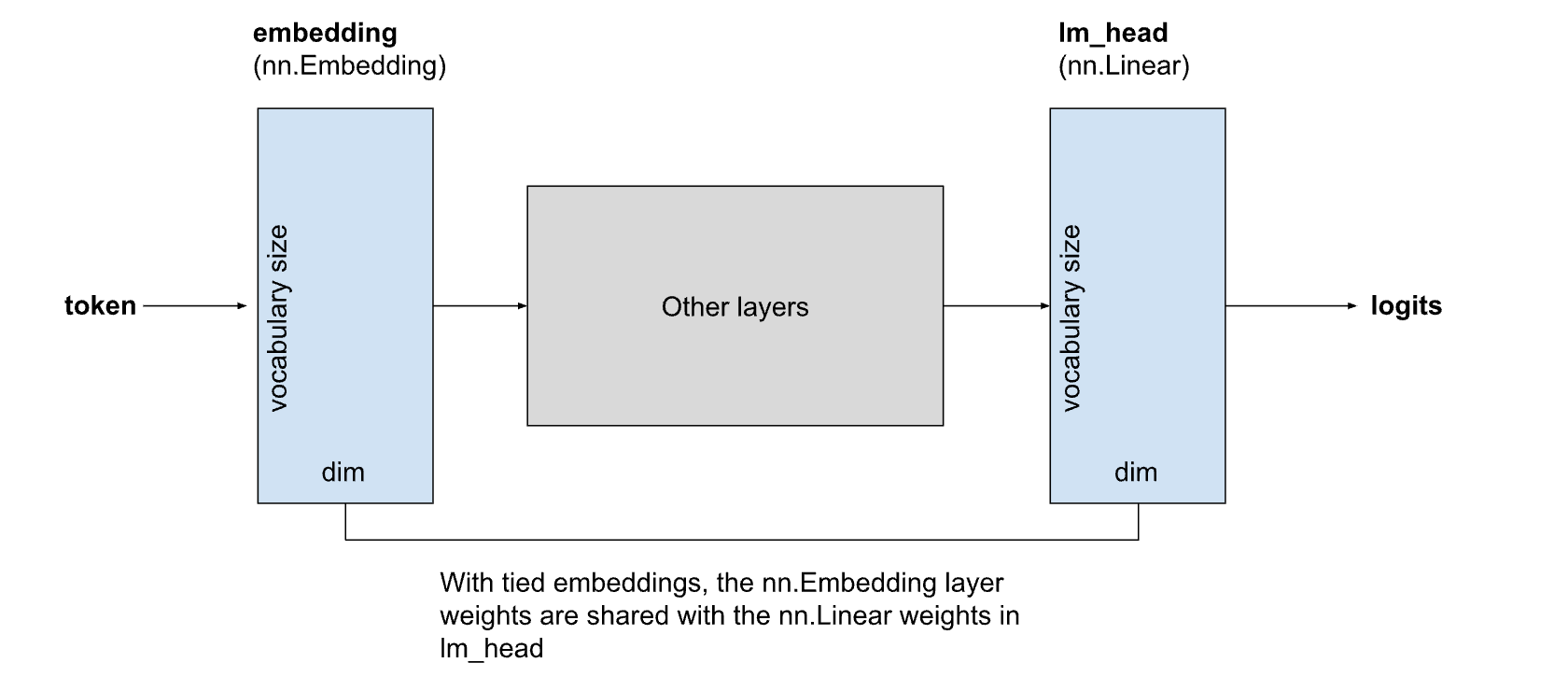
最近的模型通常使用超过 100,000 个 token 的词汇量,在较小的模型中,嵌入层和lm_head层可以占模型总大小的很大一部分。
然而,在移动设备上,这些权重有时仍会重复。这是因为高效的线性内核和嵌入内核需要以不同的格式打包权重,这使得在不牺牲性能的情况下共享权重变得不切实际。
为了解决这个问题,我们开发了用于嵌入和线性操作的高效量化内核,它们使用统一的权重格式。我们通过新的SharedEmbeddingQuantizer公开了这一点,它允许相同的量化权重用于输入嵌入和输出lm_head。这在不影响性能的情况下减小了模型大小。量化器支持各种配置,包括:
- 8 位动态激活
- x 位权重,其中 x 范围从 1 到 8
试用并贡献!
所有这些增强功能现在都可通过 torchao 的量化 API 获得——并且它们已集成到ExecuTorch中,用于将量化模型高效部署到移动和边缘设备。
我们希望您能试用、分享反馈并做出贡献!