随着模型在深度、批次大小和序列长度等方面进行扩展,激活内存对整体内存使用量的贡献越来越大。为了解决这个问题,PyTorch 提供了激活检查点(activation checkpointing)实用工具,通过在需要时重新计算张量来减少保存的张量数量,从而在内存使用量和额外计算量之间进行权衡。
在这篇文章中,我们将介绍激活内存的基础知识、现有激活检查点技术的高级概念,并引入一些旨在提高灵活性并提供更多开箱即用优化/自动化的新型技术。
在研究这些技术时,我们将比较这些方法如何适应速度与内存的权衡图,并希望为您选择适合您用例的策略提供一些见解。
(如果您想直接了解新的 API,请跳到下面的“选择性激活检查点”和“内存预算 API”部分。)
激活内存基础知识
默认情况下,在 eager 模式下(而不是使用 torch.compile),PyTorch 的 autograd 会保留中间激活以进行反向计算。例如,如果在前向传递期间对张量 x 调用 sin,autograd 必须记住 x 以在反向传递期间计算 cos(x)。
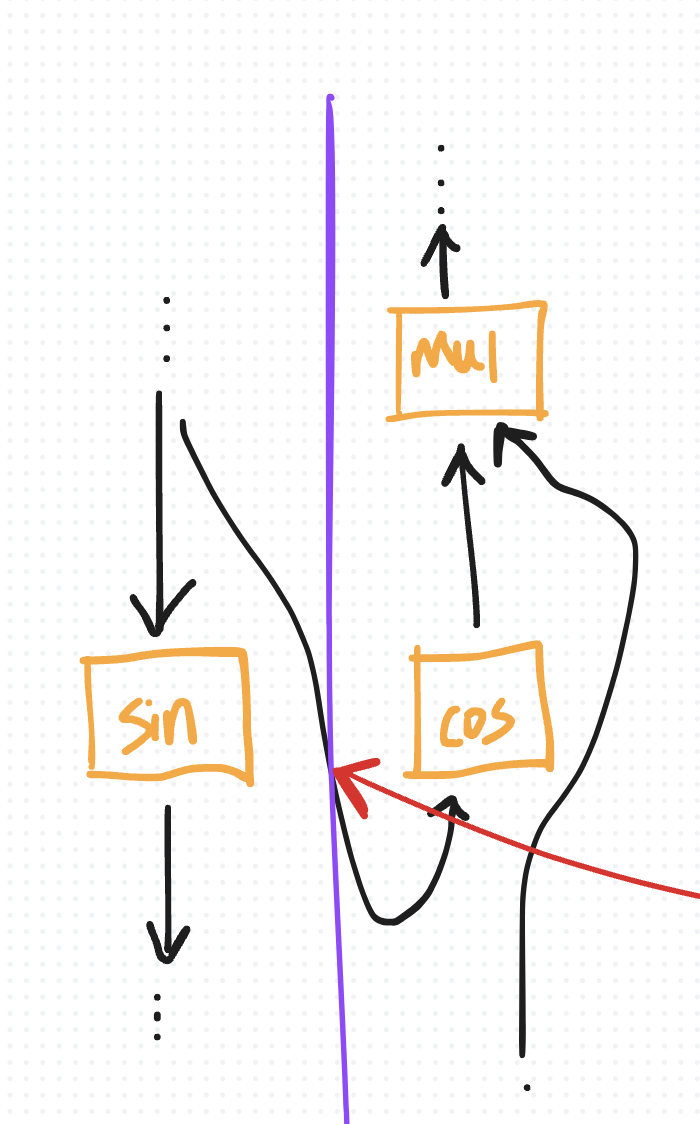
如果这个张量 x 在前向传递开始时保存,它将在前向和反向阶段都保留在内存中。它只能在用于计算梯度之后才能清除,这发生在反向传递结束时(由于执行顺序相反)。
因此,随着您在前向传递中进行越来越多的操作,您会累积越来越多的激活,从而导致越来越多的激活内存,直到它(通常)在反向传递开始时达到峰值(此时激活可以开始清除)。
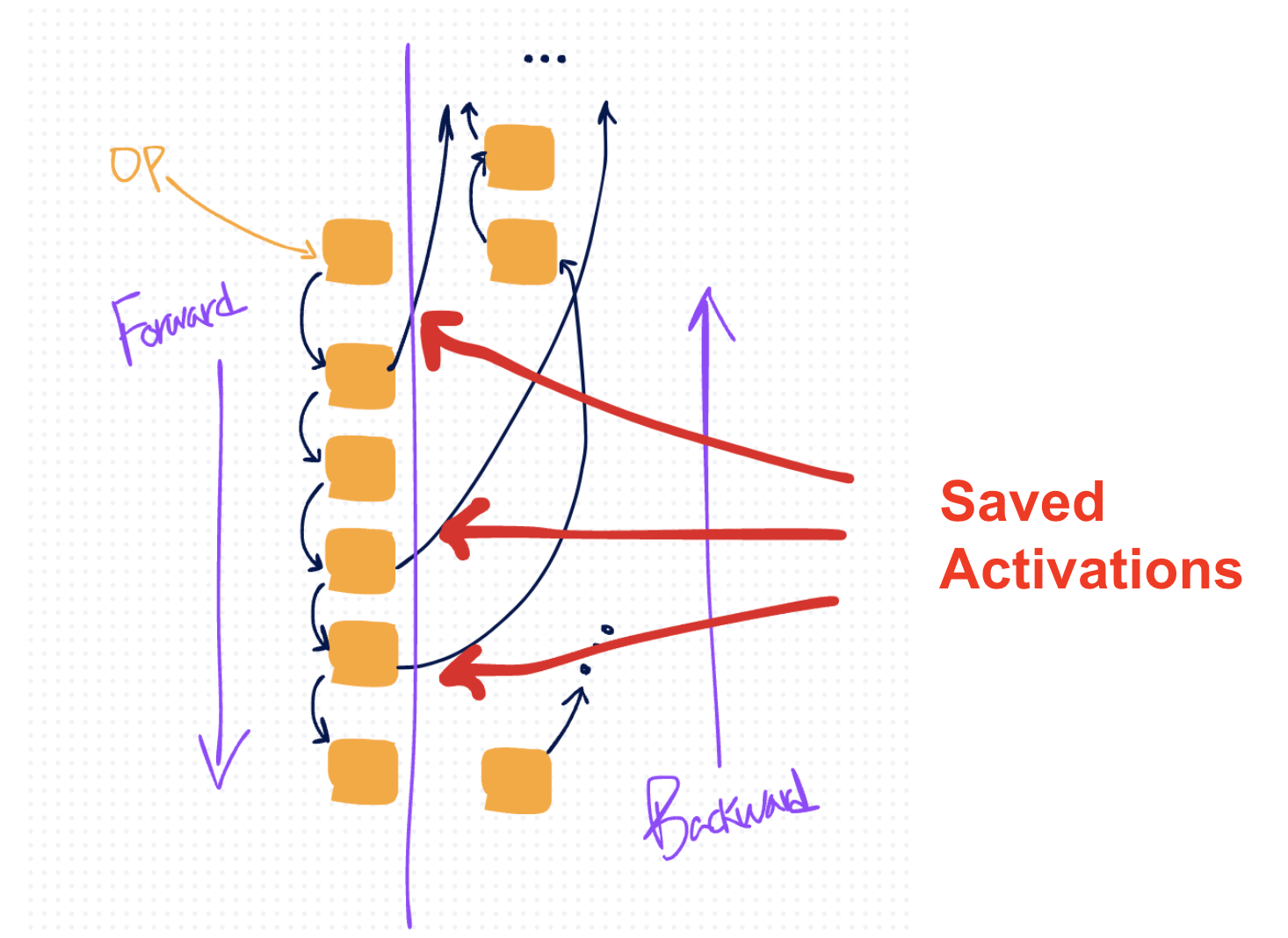
在上面的图中,橙色框表示操作,黑色箭头表示它们的张量输入和输出。越过右侧的黑色箭头表示 autograd 为反向保存的张量。
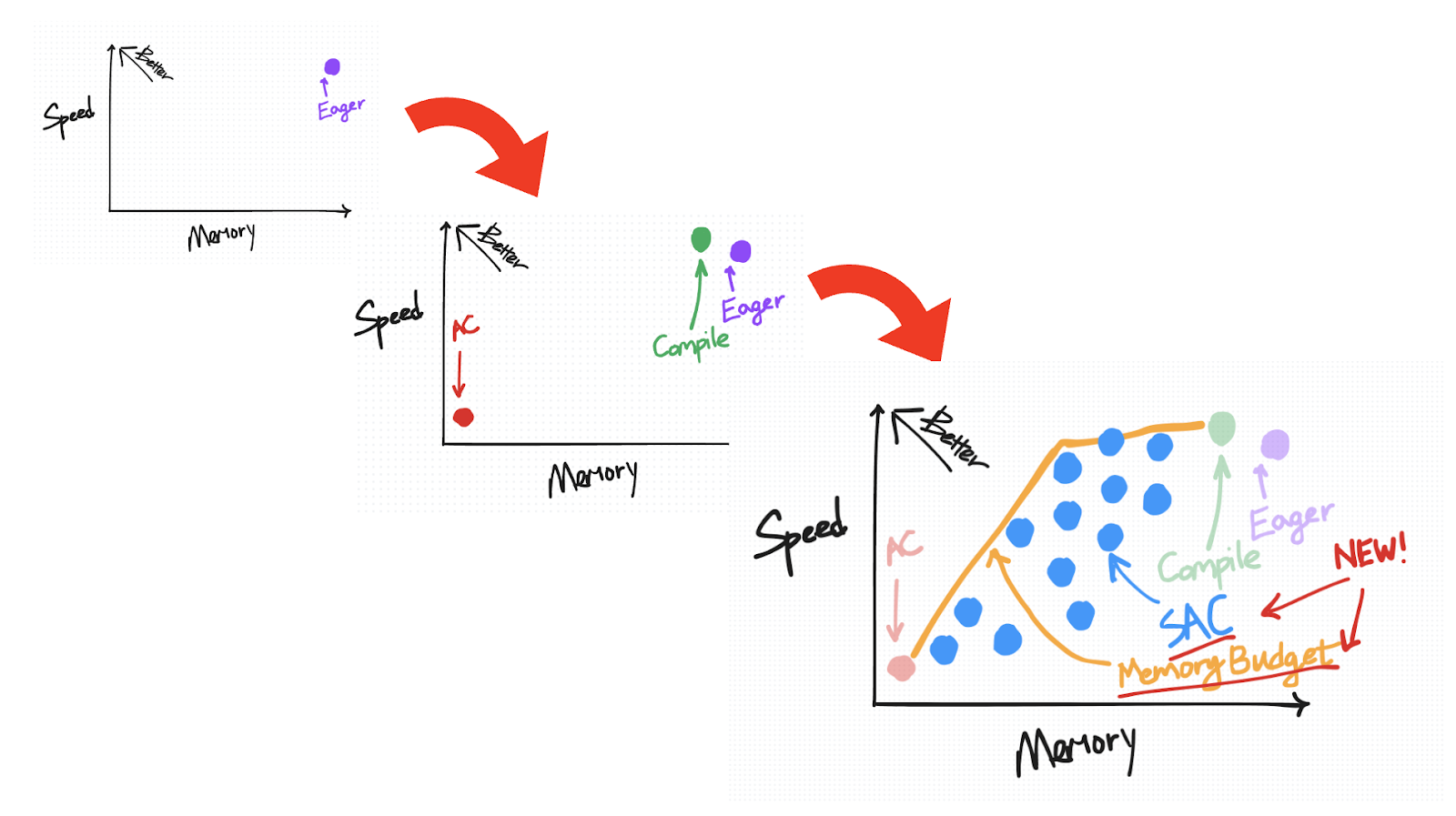
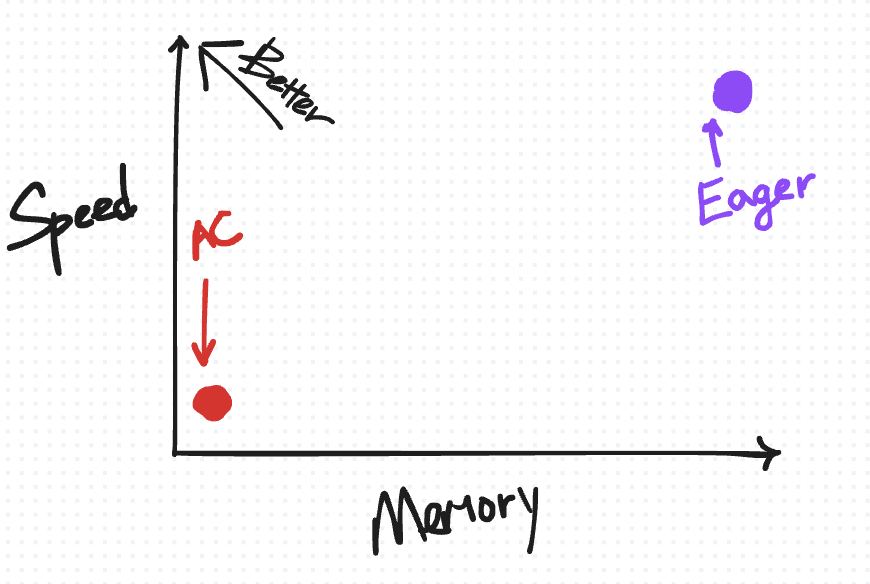
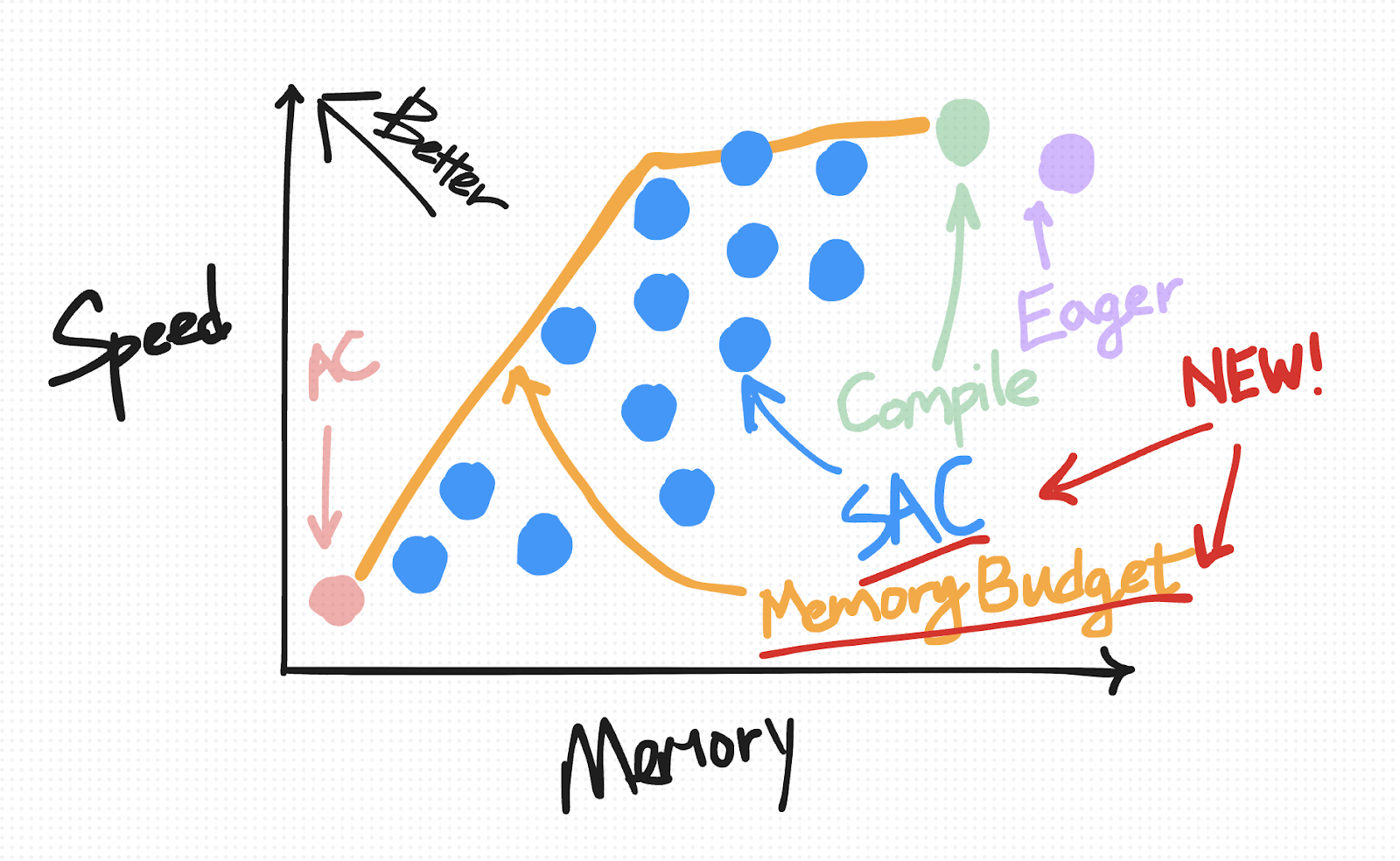
一种有用的方法,可以直观地组织 eager 模式下的这种默认保存行为以及我们将要介绍的技术,是根据它们在速度与内存之间的权衡方式来组织。
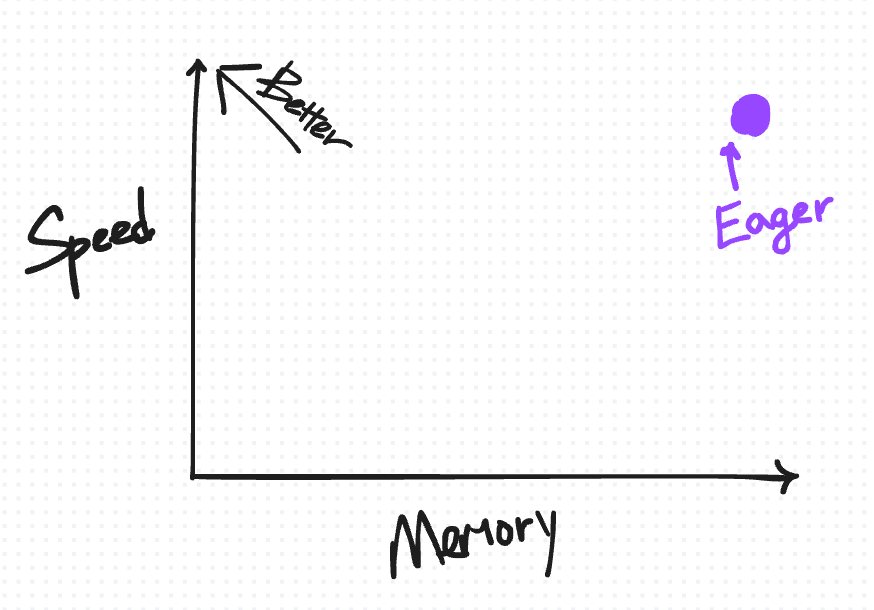
在此图上理想的位置是左上角,您拥有“高”速度但内存使用量低。
我们首先将默认保存行为放在右上方(原因我们将在介绍其他技术的更多点时详细解释)。
激活检查点 (AC)
激活检查点 (AC) 是一种在 PyTorch 中减少内存使用量的流行技术。
在前向传递期间,AC 区域内执行的任何操作都不会保存张量用于反向传递。(只保存函数的输入。)在反向传递期间,通过第二次运行函数来重新实例化梯度计算所需的中间激活。
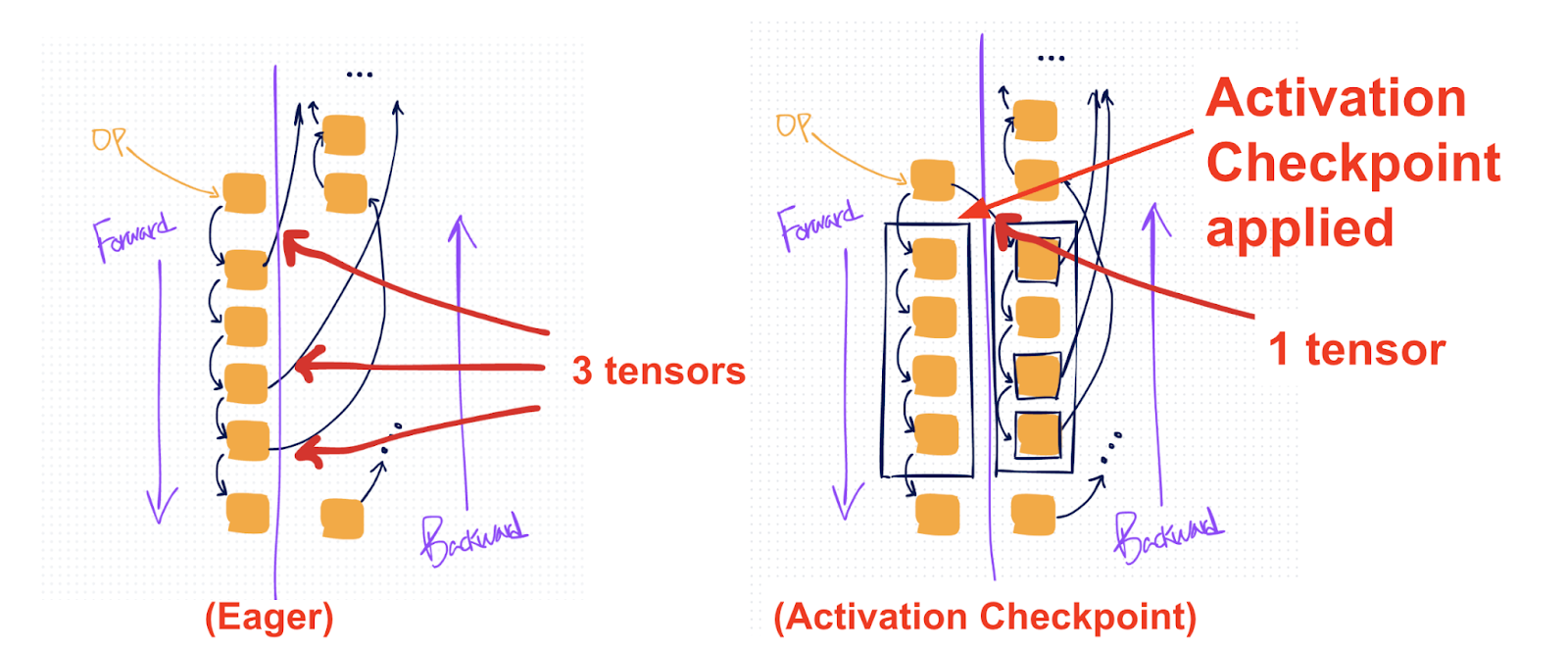
在图中(右侧),黑框显示了应用激活检查点的位置。与默认的 eager 方法(左侧)相比,这种设置导致保存的张量更少(1个而不是3个)。
在模型的正确部分应用 AC 可以减少峰值内存,因为当内存使用量通常达到峰值时(在反向传递开始时),中间激活不再实例化在内存中。
在速度与内存权衡图上,AC 绘制在左下方。相对于 eager 模式,它减少了为反向保存的内存量,但由于重新计算而增加了计算成本。
请注意,AC 的速度-内存权衡可以/通过选择检查点前向传递的哪些部分以及定义使用多少个检查点区域来调整。但是,实施这些更改可能需要修改模型的结构,并且根据代码的组织方式可能会很麻烦。为了本图的目的,我们假设只检查点一个区域;在此假设下,AC 在权衡图上显示为单个点。
另请注意,这里的“内存”不是指峰值内存使用量;相反,它表示为固定区域的反向保存了多少内存。
torch.compile 和最小割分区器
另一个值得注意的方法是 torch.compile(在 PyTorch 2.0 中引入)。像激活检查点一样,torch.compile 也可以在底层执行某种程度的重新计算。具体来说,它将前向和反向计算跟踪到一个单一的联合图中,然后由一个“最小割”分区器进行处理。这个分区器使用最小割/最大流算法来分割图,以最小化为反向传递需要保存的张量数量。
乍一看,这听起来很像我们希望用于减少激活内存的方法。然而,现实情况更为微妙。默认情况下,分区器的主要目标是减少运行时。因此,它只重新计算某些类型的操作——主要是更简单、可融合且非计算密集型的操作(如逐点操作)。
将“compile”放在速度与内存权衡图上……
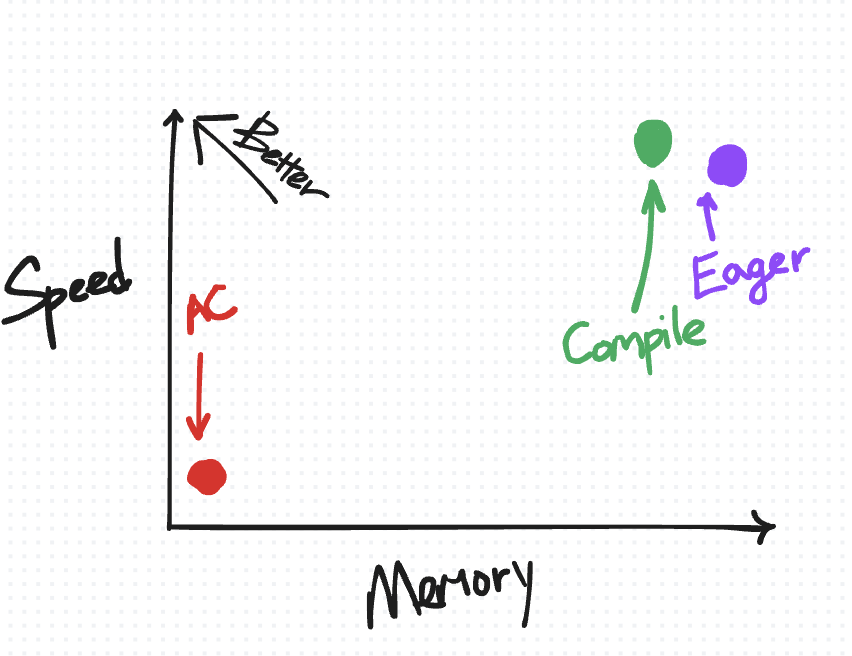
它位于 eager 非 AC 点的左上方,因为我们期望 torch.compile 在速度和内存方面都有所改进。
另一方面,相对于激活检查点,torch.compile 在重新计算方面更为保守,这使其在速度与内存图上更靠近左上方。
选择性激活检查点 [新功能!]
虽然普通检查点会重新计算所选区域中的每个操作,但选择性激活检查点 (SAC) 是在激活检查点之上的一项额外设置,您可以应用它来更精细地控制要重新计算的操作。
如果您有某些更昂贵的操作(如矩阵乘法),您希望避免重新计算,但仍然普遍希望重新计算更便宜的操作(如逐点操作),这会很有用。
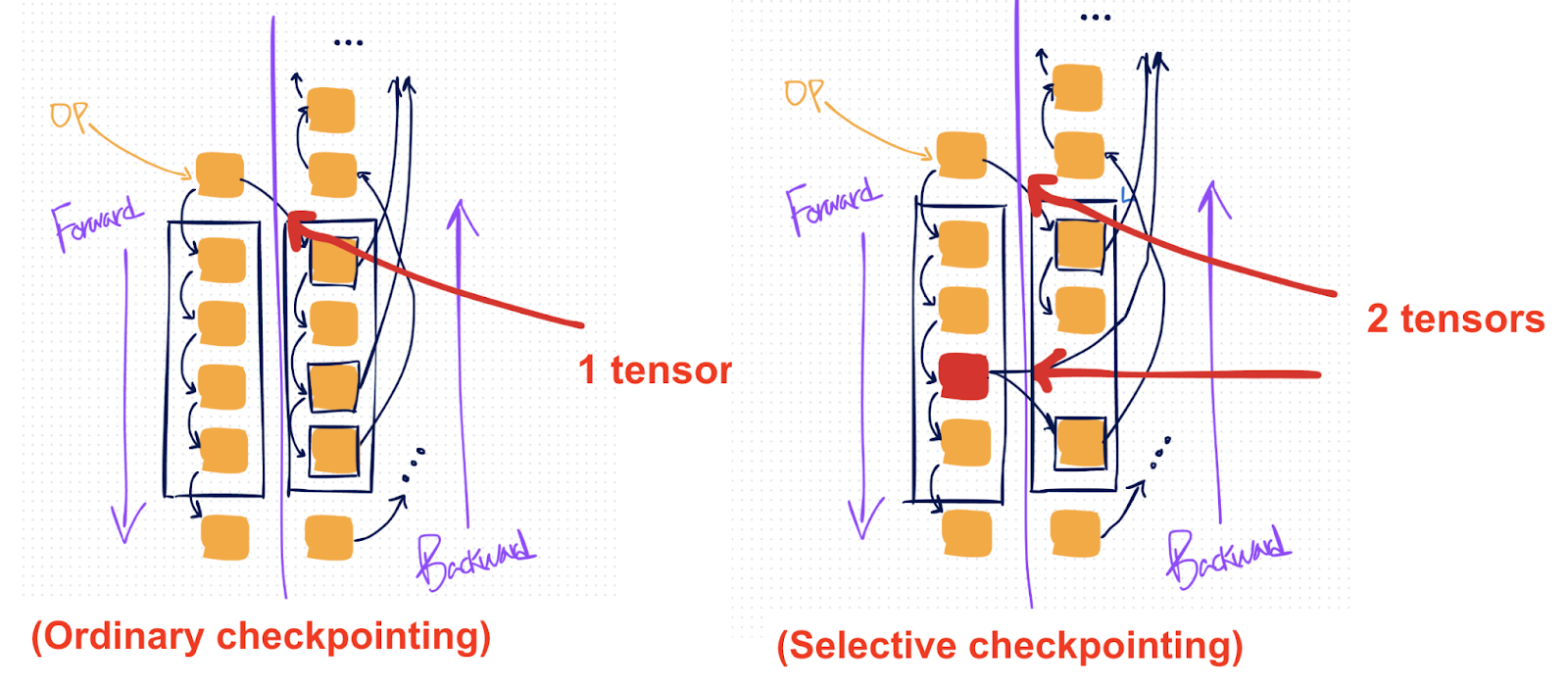
普通 AC(左侧)会保存单个张量,然后重新计算整个 AC 区域,而 SAC(右侧)允许您选择性地保存区域中的特定操作(标记为红色),这样您就可以避免重新计算它们。
要指定要选择性保存的内容,您可以指定一个 policy_fn。为了说明您可以利用这一点进行的其他权衡,我们提供了两个简单的策略函数。
策略1:不重新计算矩阵乘法
aten = torch.ops.aten
compute_intensive_ops = [
aten.mm,
aten.bmm,
aten.addmm,
]
def policy_fn(ctx, op, *args, **kwargs):
if op in compute_intensive_ops:
return CheckpointPolicy.MUST_SAVE
else:
return CheckpointPolicy.PREFER_RECOMPUTE
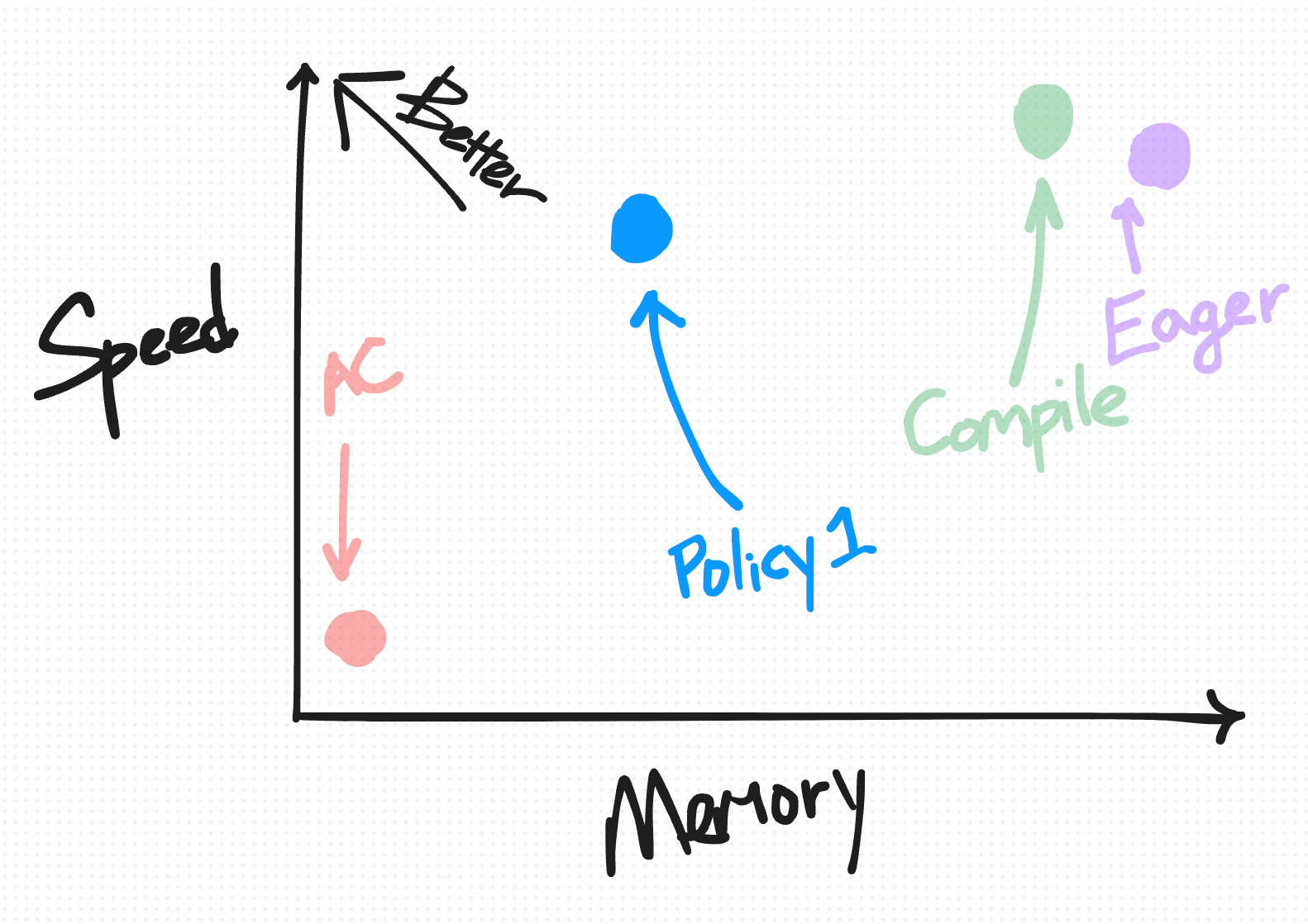
策略2:更积极地保存任何计算密集型操作
# torch/_functorch/partitioners.py
aten = torch.ops.aten
compute_intensive_ops = [
aten.mm,
aten.convolution,
aten.convolution_backward,
aten.bmm,
aten.addmm,
aten._scaled_dot_product_flash_attention,
aten._scaled_dot_product_efficient_attention,
aten._flash_attention_forward,
aten._efficient_attention_forward,
aten.upsample_bilinear2d,
aten._scaled_mm
]
def policy_fn(ctx, op, *args, **kwargs):
if op in compute_intensive_ops:
return CheckpointPolicy.MUST_SAVE
else:
return CheckpointPolicy.PREFER_RECOMPUTE
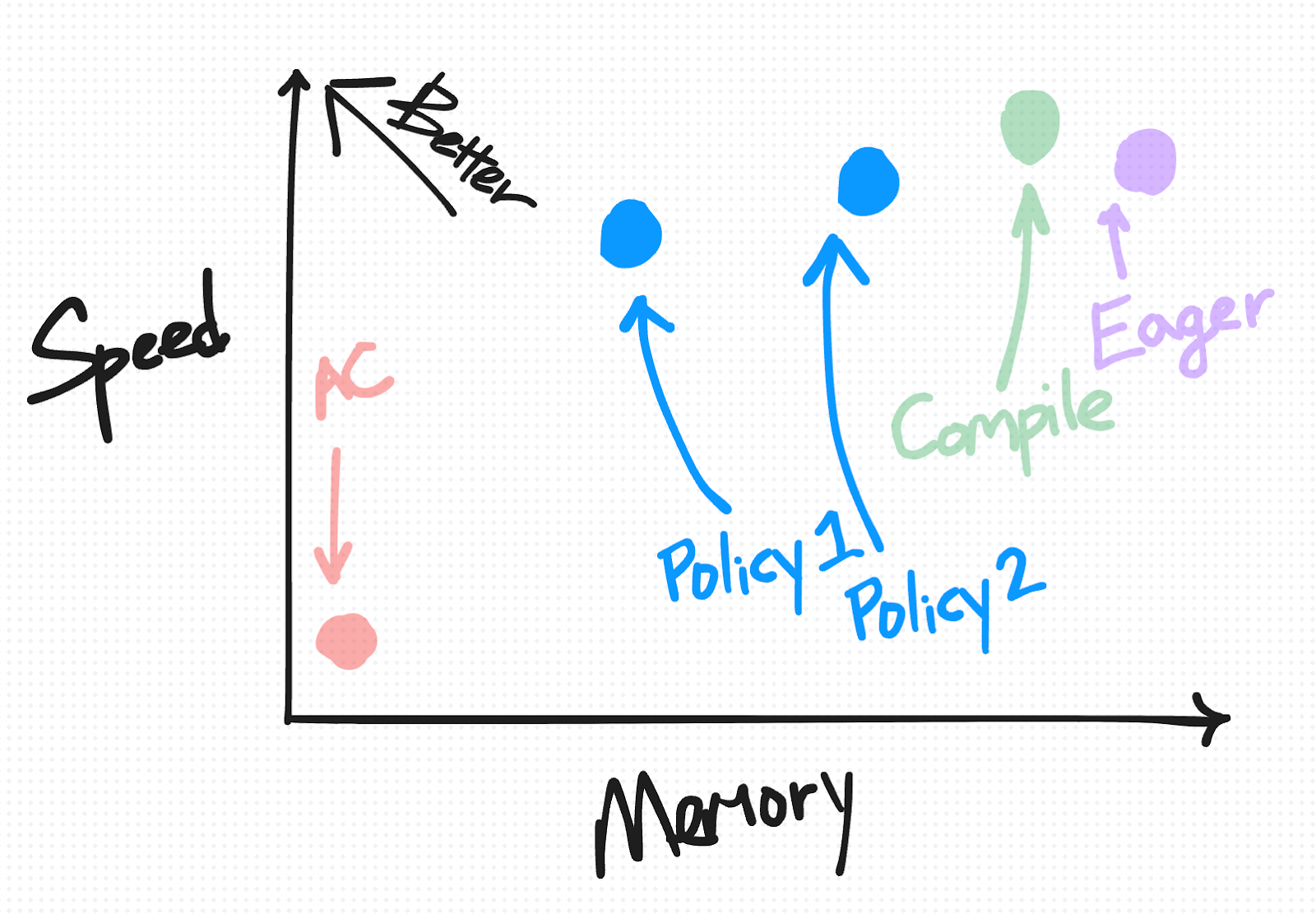
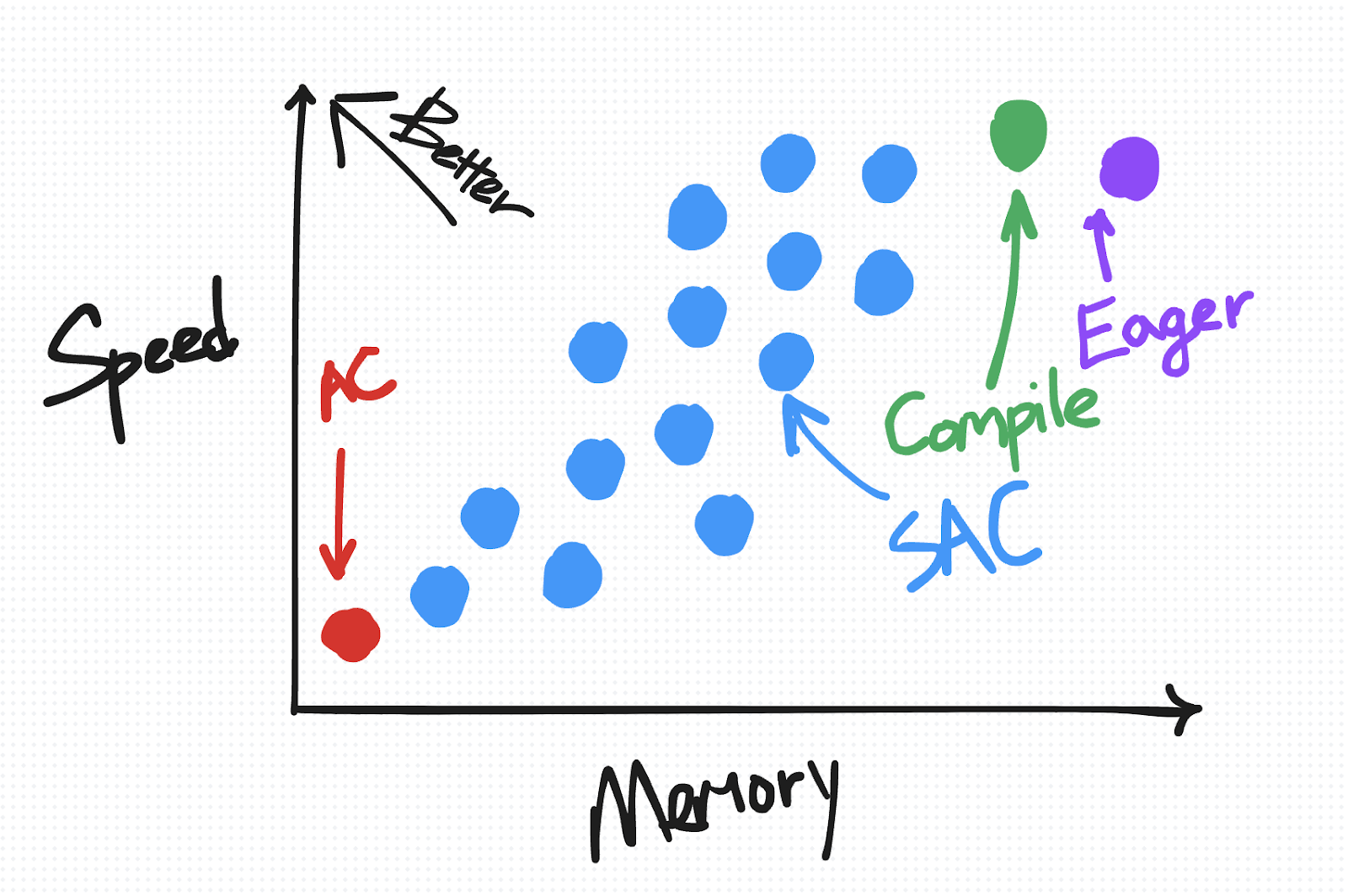
在速度与内存图上,SAC 根据您选择的策略,被绘制成从靠近 AC 到靠近 Eager 的一系列点。
快来试试吧! (作为原型功能在 2.5 版本中可用;请参阅文档了解更多信息 + 可复制粘贴的示例)
from torch.utils.checkpoint import checkpoint, create_selective_checkpoint_contexts
# Create a policy function that returns a CheckpointPolicy
def policy_fn(ctx, op, *args, **kwargs):
if op in ops_to_save:
return CheckpointPolicy.MUST_SAVE
else:
return CheckpointPolicy.PREFER_RECOMPUTE
# Use the context_fn= arg of the existing checkpoint API
out = checkpoint(
fn, *args,
use_reentrant=False,
# Fill in SAC context_fn's policy_fn with functools.partial
context_fn=partial(create_selective_checkpoint_contexts, policy_fn),
)
(仅限编译)内存预算 API [新功能!]
如前所述,任何给定的 SAC 策略都可以表示为速度-内存权衡图上的一个点。然而,并非所有策略都是等同的。“最优”策略是落在帕累托曲线上方的策略,例如,对于所有产生相同内存开销的策略,此策略是最小化所需计算量的策略。
对于使用 torch.compile 的用户,我们提供了一个内存预算 API,它会自动在您编译的区域上应用具有帕累托最优策略的 SAC,给定用户指定的 0 到 1 之间的“内存预算”,其中预算为 0 时表现为普通 AC,预算为 1 时表现为默认 torch.compile。
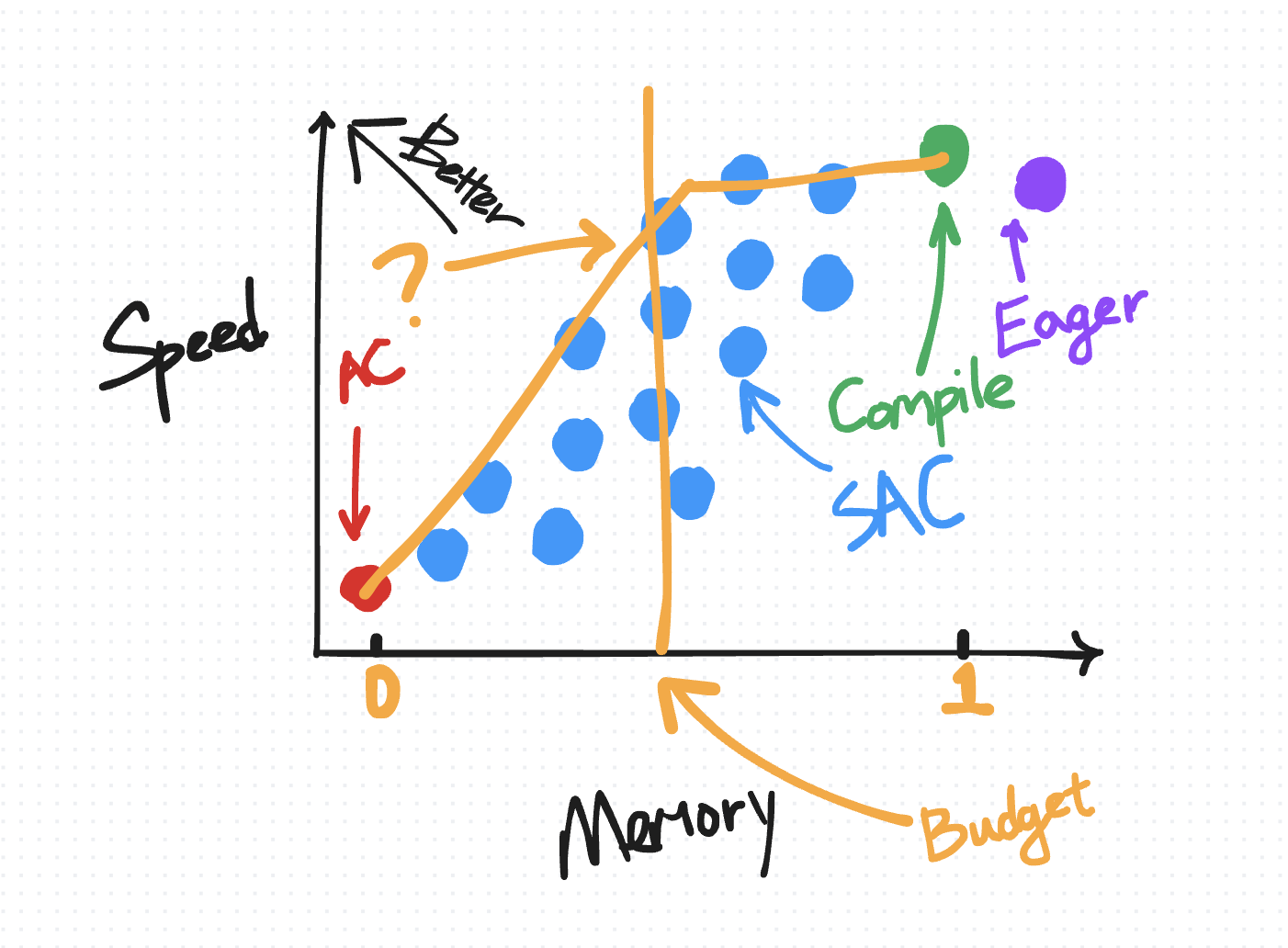
以下是 Transformer 模型的一些真实结果
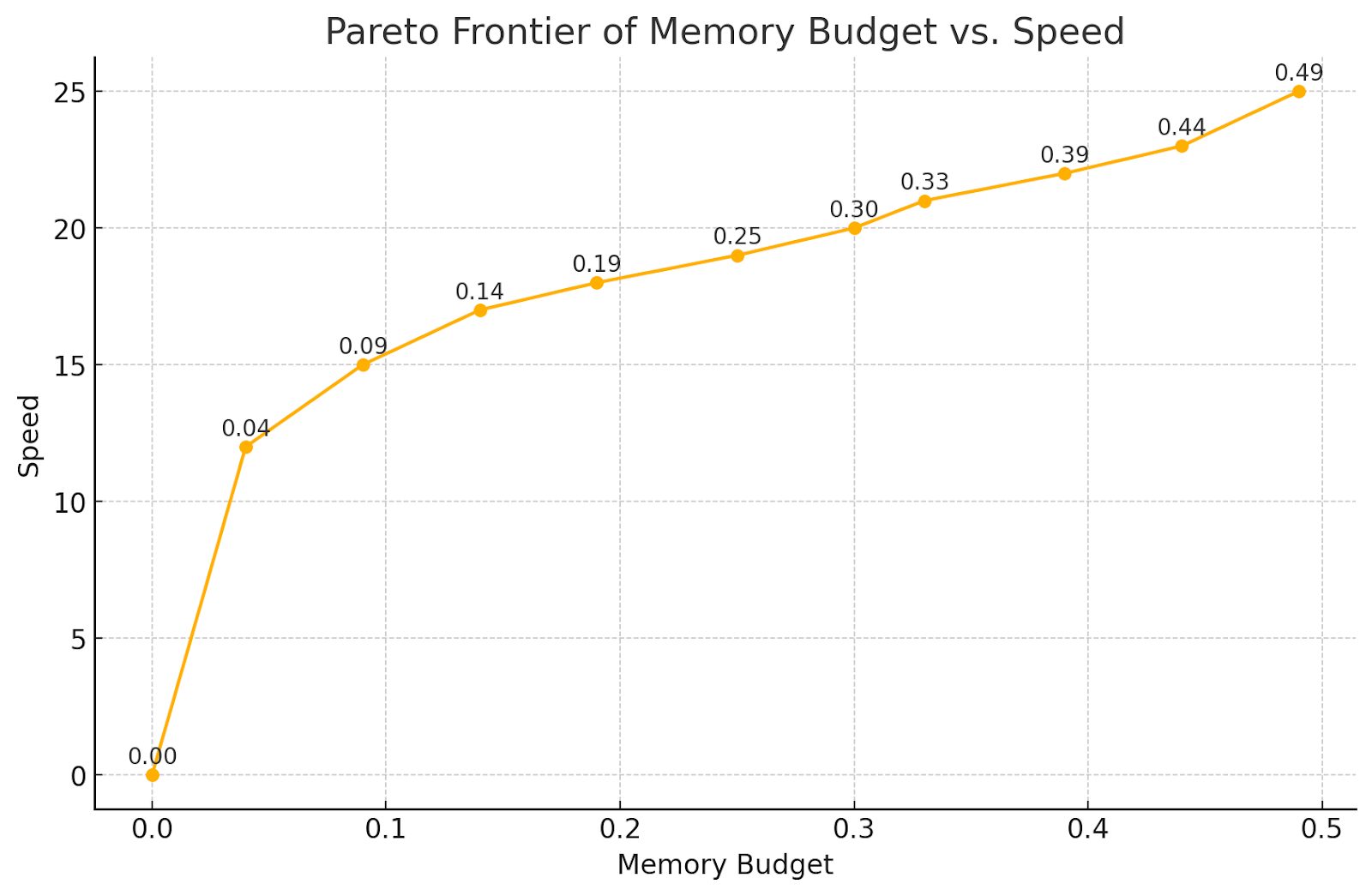
我们观察到,通过仅重新计算逐点操作,内存减少了 50%,并且随着您重新计算越来越多的矩阵乘法,内存持续下降。注意力计算是最昂贵的,因此您倾向于最后重新计算它们。
快来试试吧! (作为实验性功能在 2.4 版本中可用;请参阅此注释块了解更多信息)
torch._dynamo.config.activation_memory_budget = 0.5
out = torch.compile(fn)(inp)
结论
总而言之,PyTorch 中的激活检查点技术提供了多种平衡内存和计算需求的方法,从简单的基于区域的检查点到更具选择性和自动化的方法。通过选择最适合您的模型结构和资源限制的选项,您可以在可接受的计算权衡下显着节省内存。
致谢
我们要感谢 Meta 的 xformers 团队,包括 Francisco Massa,感谢他们开发了选择性激活检查点的原始版本。