总结
我们利用第一性原理,展示了一个逐步加速当前 Triton GPTQ 内核的过程,使其速度提升 3 倍(核心 GPTQ)和 6 倍(AutoGPTQ)。例如:在典型的 Llama 风格推理输入上,从 275 微秒缩短到 47 微秒。目标是提供一个有用的模板,用于加速任何 Triton 内核。我们提供了 Triton 和 GPTQ 量化与反量化过程的背景知识,展示了合并内存访问以提高共享内存和全局内存吞吐量的影响,强调了为减少 warp 停滞以提高总吞吐量所做的更改,并概述了如何将 Triton 内核集成到 PyTorch 代码中。从长远来看,我们希望通过我们的 Triton 内核超越现有的 CUDA 原生 GPTQ 内核。
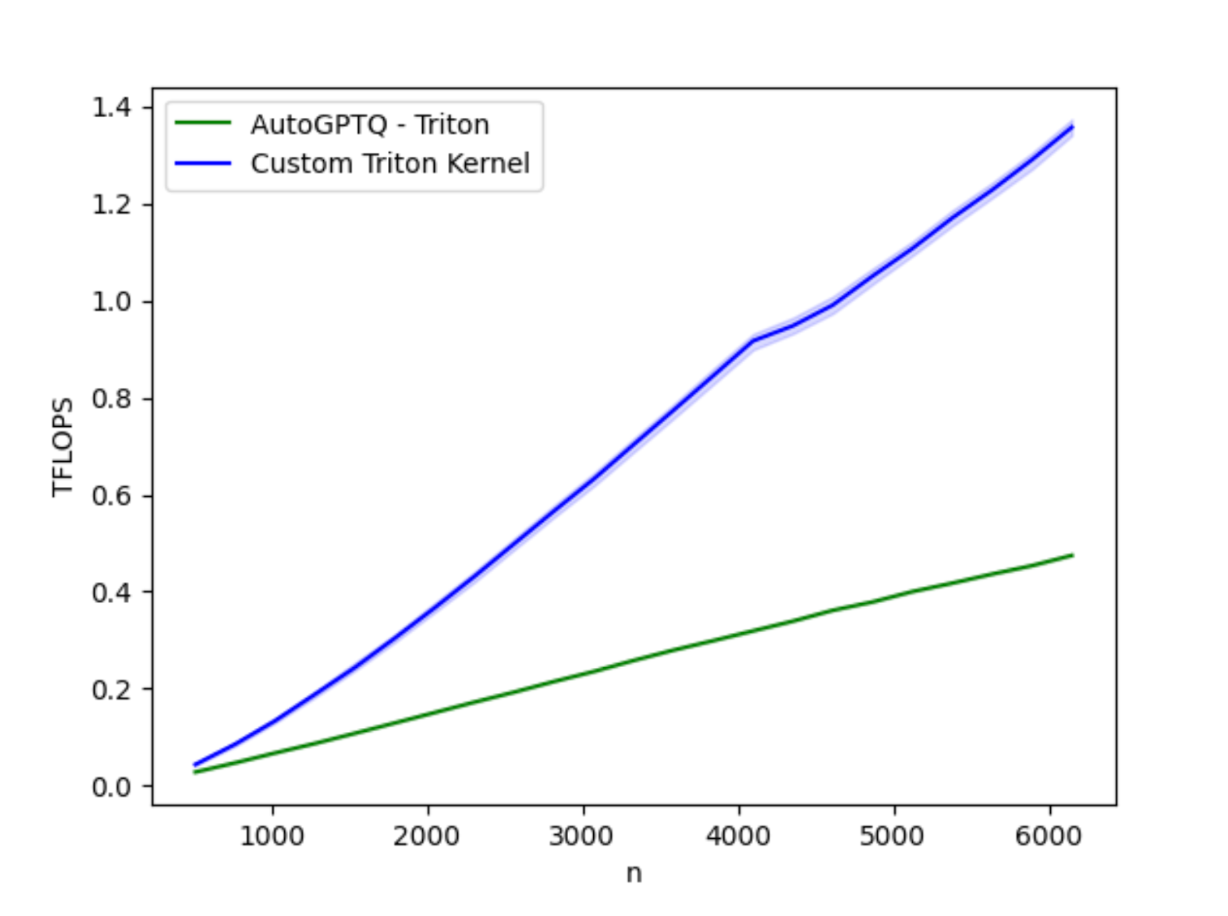
图 1:优化后的 AutoGTPQ 内核与当前 AutoGPTQ 内核在 H100 上的性能基准测试
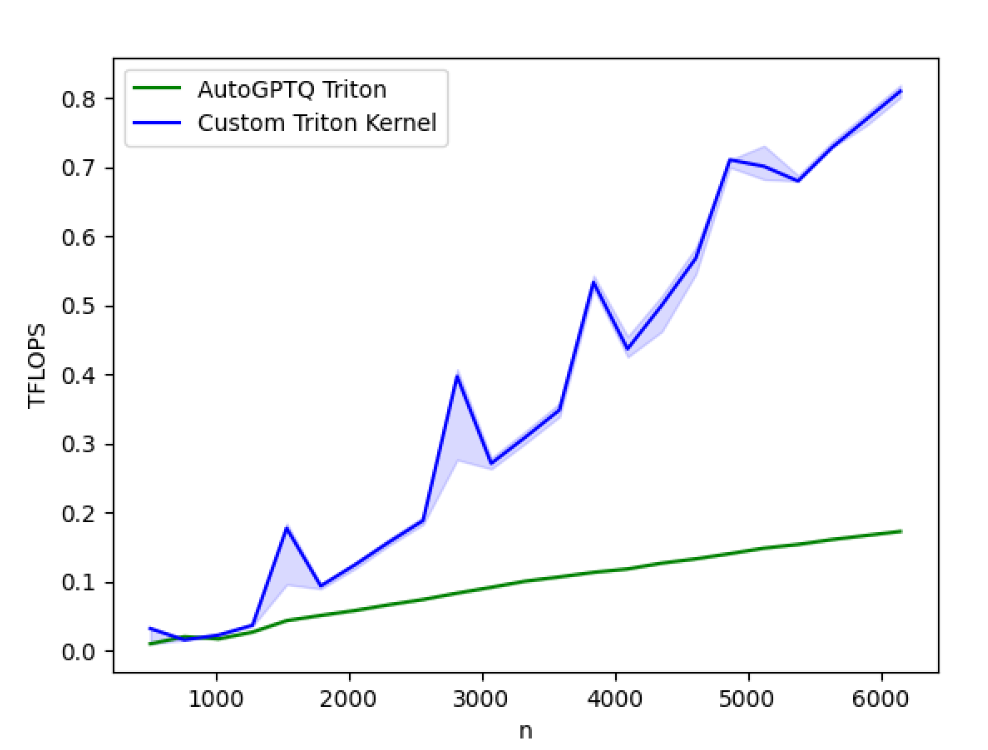
图 2:新优化的 AutoGTPQ 内核与当前 AutoGPTQ 内核在 A100 上的性能基准测试
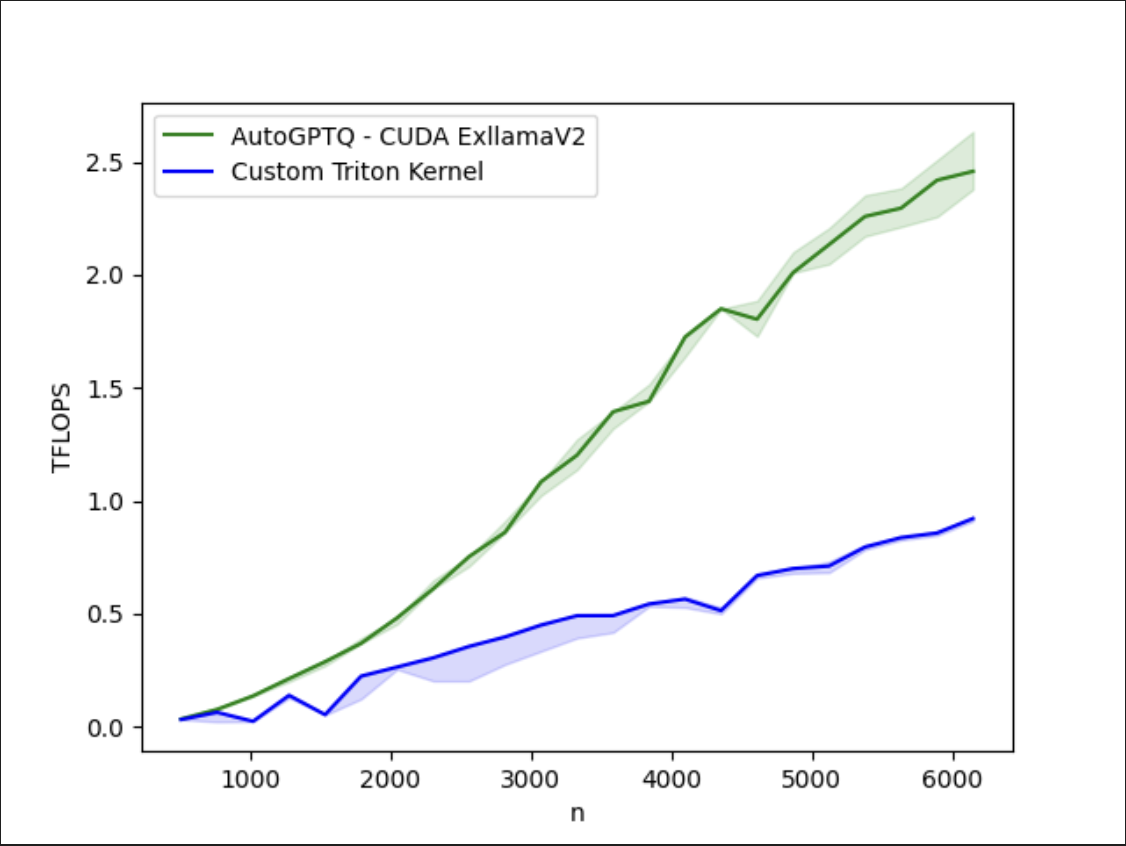
图 3:即使有这些改进,我们的优化 Triton 内核与 A100 上的 CUDA 原生 AutoGTPQ 内核之间仍存在差距。更多内容即将发布……
1.0 Triton 简介
Triton 框架提供了一种与硬件无关的 GPU 编程和目标定位方式,目前支持 NVIDIA 和 AMD,对其他硬件供应商的支持正在进行中。Triton 现在是 PyTorch 2.0 的主要组成部分,因为 torch.compile 会分解 Eager PyTorch 并将其重新组装成高比例的 Triton 内核,由 PyTorch 连接代码。
随着 Triton 被更广泛地采用,程序员将需要了解如何系统地遍历 Triton 堆栈(从高级 Python 到低级 SASS),以解决性能瓶颈,从而优化超出 torch.compile 生成内核的算法的 GPU 效率。
在这篇文章中,我们将介绍 Triton 编程语言的一些核心概念,如何识别 GPU 内核中常见的性能限制因素,并并行地调整 AutoGPTQ 中用于高吞吐量推理应用的量化内核。
GPTQ 量化与反量化简介
GPTQ 是一种量化算法,能够通过近似二阶信息(Hessian 逆矩阵)将超大型 (175B+) LLM 有效压缩为 int4 位表示。AutoGPTQ 是一个基于 GPTQ 构建的框架,允许对使用 GPTQ 量化的 LLM 进行快速反量化和推理/服务。
作为 AutoGPTQ 堆栈的一部分,他们提供了一个 Triton GPTQ 内核来处理模型的反量化以进行推理。
INT 量化的基本过程如下所示,涉及确定比例因子和零点,然后使用比例因子和零点计算量化的 4 位权重。

因此,我们将 4 位权重以及每组权重的比例因子和零点元信息存储起来。
要“反量化”这些权重,我们执行以下操作:
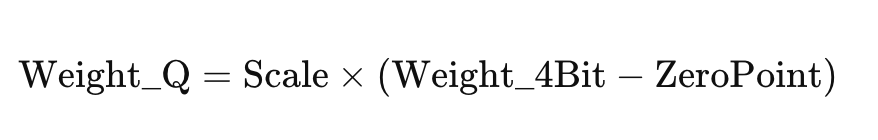
然后继续将反量化后的权重与此线性层的密集输入特征矩阵进行**矩阵乘法**。
2.0 识别瓶颈 – 优化矩阵乘法
事实证明,实现一个快速的矩阵乘法内核并非易事。一个天真实现的矩阵乘法在像 GPU 这样的高度并行机器上很少能达到峰值吞吐量性能。因此,我们需要分层地处理 GPU 中的计算和内存子系统,以确保我们最大限度地利用每种资源。
我们通过 Nvidia Nsight Compute 工具运行未优化的 Triton 内核来启动优化过程,并记录一些重要的指标和警告。

图 xy(待办)

我们首先注意到计算和内存吞吐量都很低,分别为 7.40% 和 21.19%(图 xy)。我们知道对于典型的推理矩阵问题大小,我们处于内存受限状态,我们将尝试通过应用针对 A100 GPU 内存子系统的代码更改来优化内核。
本文将涵盖的三个主题是:
- L2 优化
- 向量化加载
- Warp 停滞
让我们逐一探讨每个主题,进行适当的更改,并查看其对我们的 Triton 内核的相应影响。这个 Triton 内核是一个融合的反量化内核,它将一个打包的 int32 权重(我们将其称为 B 矩阵)张量反量化为 int4 权重,以 FP16 模式与激活张量(称为 A 矩阵)执行矩阵乘法,然后将结果存储回矩阵 C。
上述过程称为 W4A16 量化。请记住,我们描述的过程可以并且应该用于开发任何 GPU 内核,因为这些是任何未优化内核中常见的瓶颈。
3.0 L2 优化
此优化已存在于 AutoGPTQ 内核中,但我们希望专门用一节来帮助读者更好地理解 Triton 中线程块的映射和执行顺序是如何处理的。因此,我们将逐步介绍一种简单的映射,然后是一种更优的映射,以查看其相应的影响。
让我们从头开始构建我们的内核,首先是全局内存的“线性”加载,然后将其与更优化的“交错”加载进行比较。线性与交错决定了 GPU 上工作网格的执行顺序。让我们看看 Nvidia Nsight Compute 工具 在简单情况下针对我们内核的共享内存访问模式提供的提示

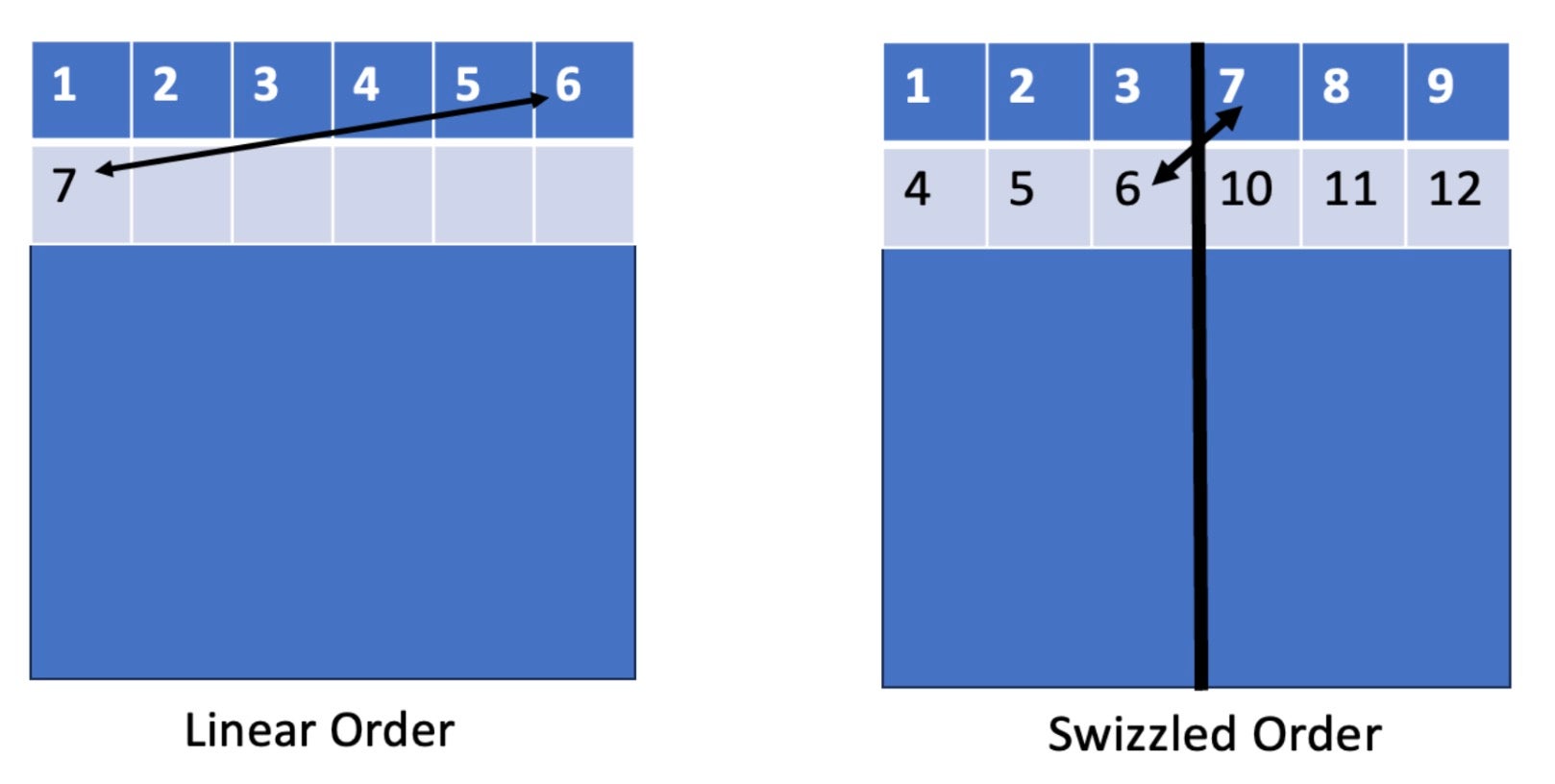
为了解决这个问题,我们可以使用一种称为“瓦片交错”的方法。这种方法的思想是以一种更对 L2 缓存友好的顺序启动我们的线程块。
让我们退一步,熟悉一些 Triton 语义,并做一个简单的 CUDA 类比来更好地理解这个概念。Triton 内核启动“程序”。这些所谓的程序映射到 CUDA 中的线程块概念,它是 Triton 内核中并行的基本单元。每个程序都有一个关联的“pid”,并且程序中的所有线程都保证执行相同的指令。
如果您将“pid”简单线性映射到输出矩阵 C 的 2D 网格位置,Triton 程序将以一种简单的方式分布到您的 SM 上。
这个二维网格位置由 Triton 中的 pid_m 和 pid_n 决定。当我们在分发工作网格时,我们希望利用 GPU L2 缓存中的数据和缓存局部性。要在 Triton 中实现这一点,我们可以进行以下更改
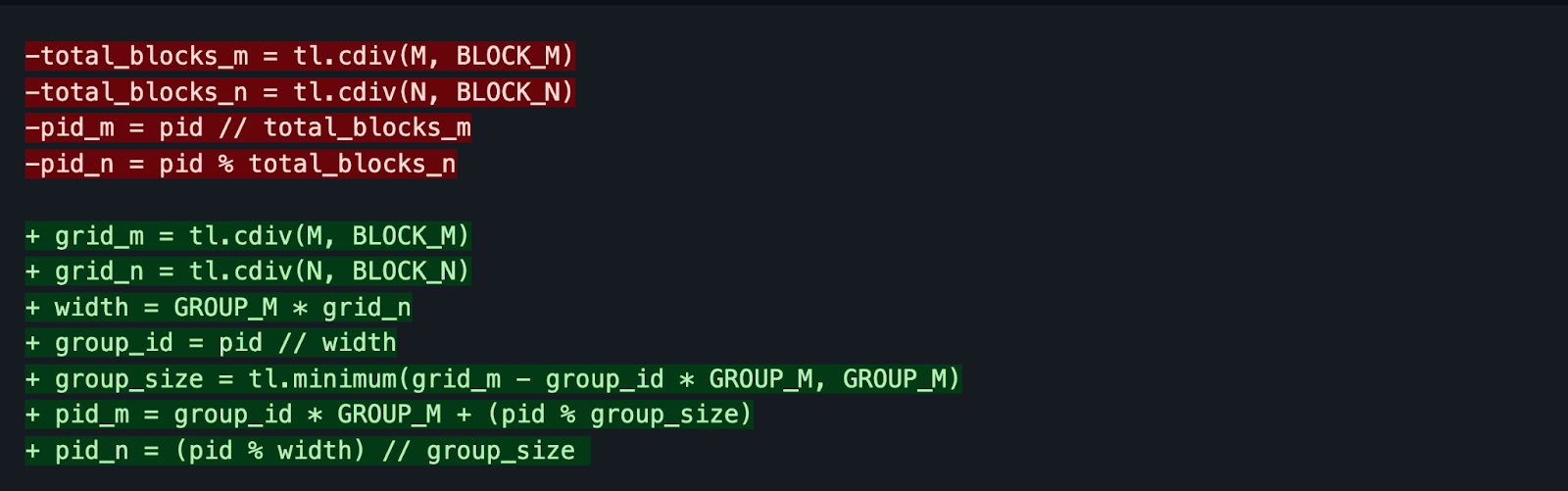
红色高亮的代码是简单的“线性”瓦片排序,绿色高亮的代码是“交错”瓦片排序。这种启动方式促进了局部性。这里有一个视觉图来帮助更好地理解这一点。
在整合了这一改变之后,分析器不再抱怨非合并内存访问。让我们来看看我们的内存吞吐量发生了怎样的变化。
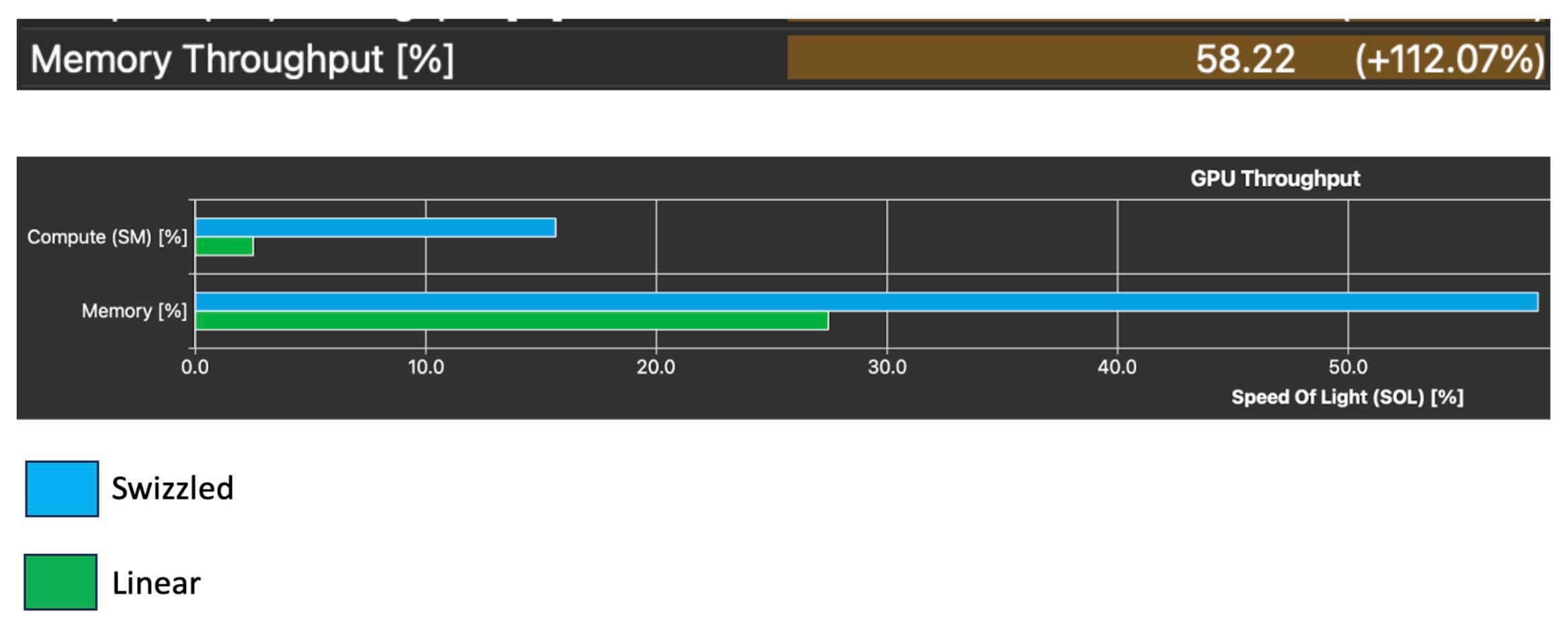
此更改在一个简单的加载存储内核上进行了测试。在分析器中的 GPU 光速统计部分,我们还看到简单加载内核的内存吞吐量增加了 112.07%,这正是我们通过此优化所追求的。同样,此优化已存在于 AutoGPTQ 内核中,但它是每个 Triton 内核程序员在内核开始时,在任何令人兴奋的反量化或矩阵乘法逻辑之前,都必须编写的样板逻辑。因此,理解以下几点很重要:
- 这种映射不是唯一的
- Triton 不会自动为程序员处理这种优化,必须仔细考虑以确保您的内核最优地处理共享内存访问
对于 Triton 新手来说,这些并不明显,因为大部分共享内存访问优化都由 Triton 编译器处理。然而,在编译器未处理这些情况时,理解可用的工具和方法来影响内存行为非常重要。
4.0 向量化加载
现在,回到我们未优化内核的原始抱怨。我们希望优化内核的全局内存访问模式。从 Nvidia Nsight compute 工具的详细信息页面,我们看到以下注释,其中分析器抱怨非合并的全局内存访问。
让我们深入研究,看看未优化内存读取的 SASS(汇编)代码加载
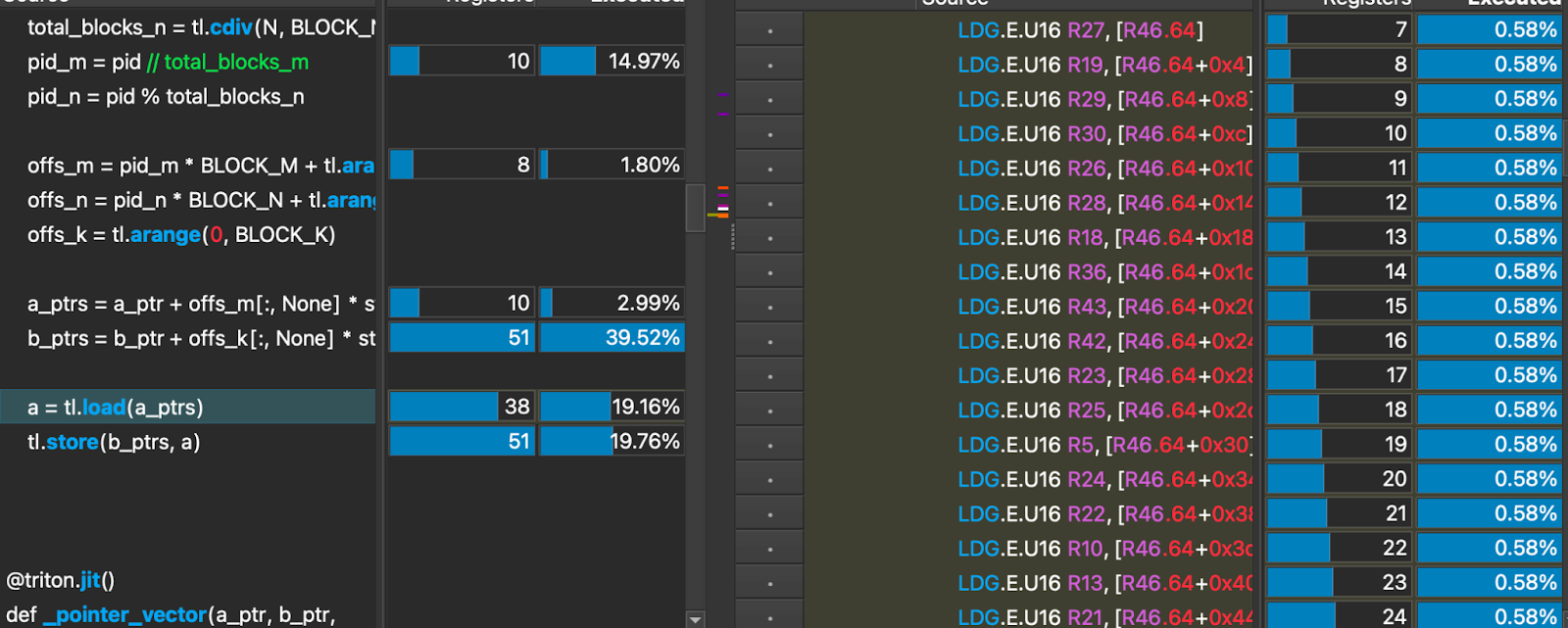
这个加载操作导致了 32 个 16 位宽的全局加载操作。这并非最佳。
我们希望以向量化的方式进行全局内存加载,从而导致最少的加载指令。为了解决这个问题,我们可以给 Triton 编译器一些帮助。
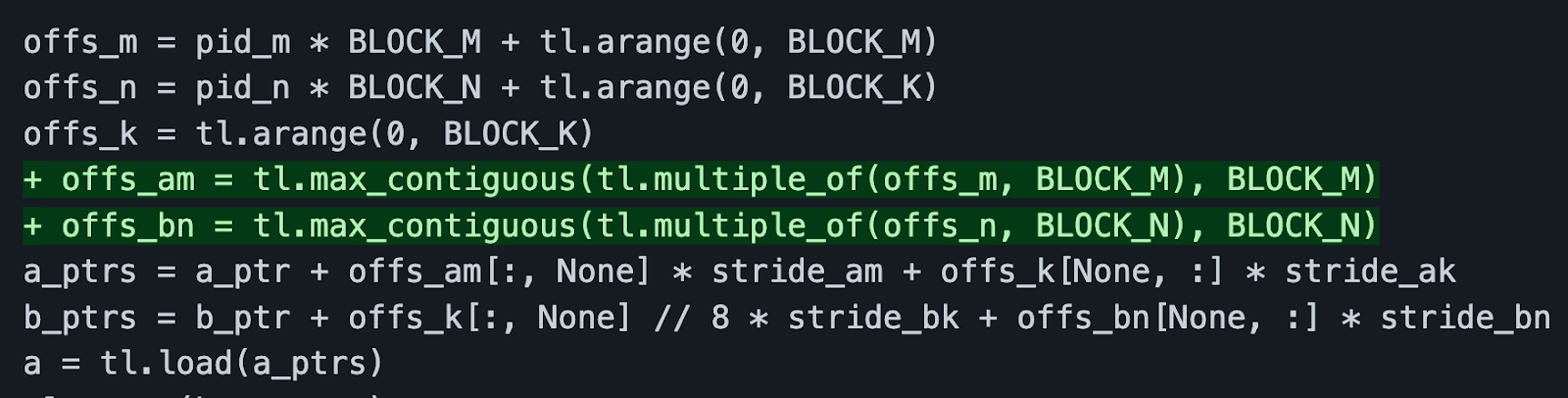
上面绿色高亮的行作为编译器提示。它告诉编译器这些元素在内存中是连续的,并且这个加载操作可以合并。
让我们看看添加这些行后,汇编代码的效果。
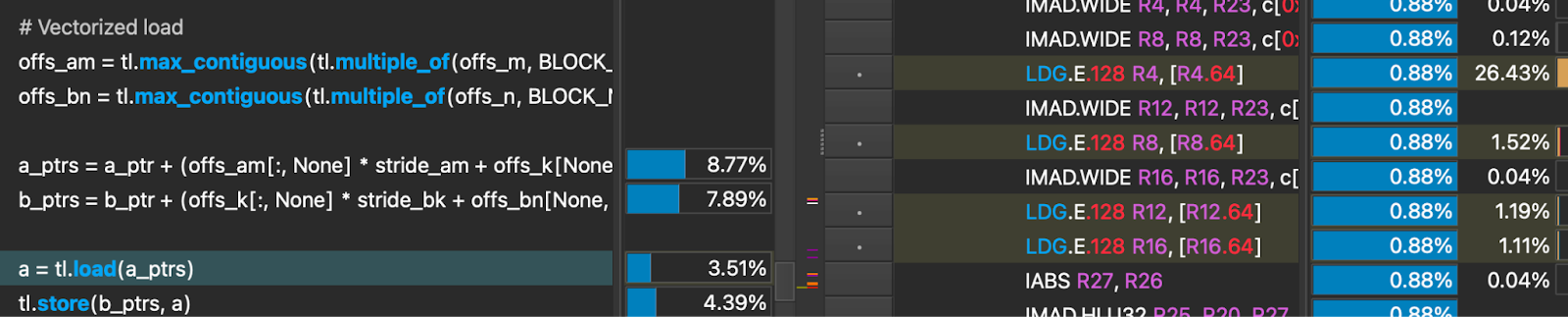
现在加载操作通过 4 个 128 位宽的全局加载操作完成,而不是 32 个 16 位全局加载操作。这意味着减少了 28 条内存取指令,更重要的是实现了合并内存访问。这可以从一个线程没有访问连续内存地址这一事实看出,而没有编译器提示时,行为并非如此。
最终效果是在独立加载操作中实现了 73 倍的加速,并在将其整合到完整的反量化内核后,我们又看到了 6% 的加速。这是朝着正确方向迈出的又一步!
5.0 Warp 停滞
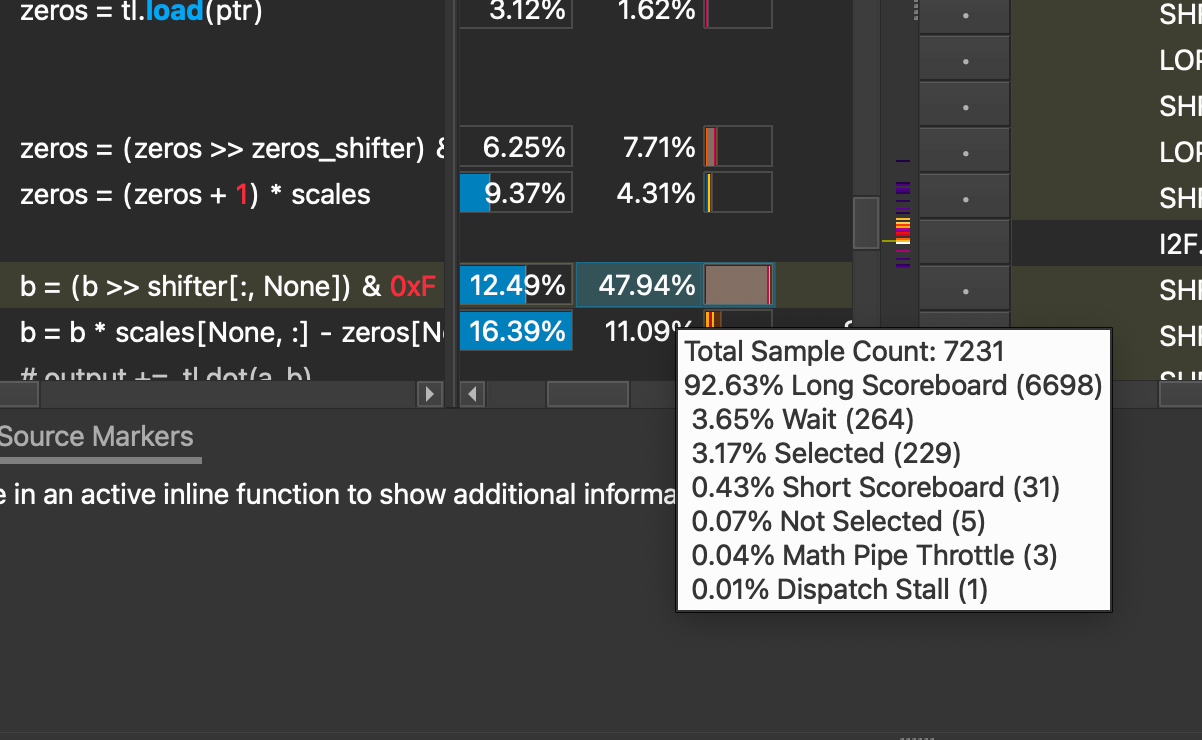
现在,将所有更改重新整合到我们的完整反量化内核中,我们看到了以下性能限制因素:warp 停滞。
这些 warp 停滞主要由“长记分板”停滞引起,占总数的 92.63%。
从高层次来看,长记分板停滞 发生在当一个 warp 需要的数据可能尚未准备好才能进入“已发出”状态时。换句话说,GPU 是吞吐量机器,我们需要用计算指令来隐藏加载指令的延迟。通过加载更多数据并重新安排脚本中加载指令的位置,我们可以解决这个问题。
在理想情况下,每个 warp 调度器都能够在每个时钟周期发出 1 条指令。注意 - A100 GPU 上的每个 SM 都有 4 个 warp 调度器。
然而,我们的内核存在瓶颈,在 AutoGPTQ Triton 内核认为在给定其预设的情况下最优的块大小下,它在停滞状态下花费了 4.4 个周期。
我们如何改进这一点?
我们希望能够提高内存吞吐量,以便增加当 warp 发出指令时,我们不会等待加载指令存储在 SRAM 中以便用于计算的机会。我们尝试了多个参数(例如流水线阶段数和 warp 数),其中影响最大的是将 k 维度中的块大小增加一倍。
这些变化对计算和内存吞吐量都产生了立竿见影的影响。
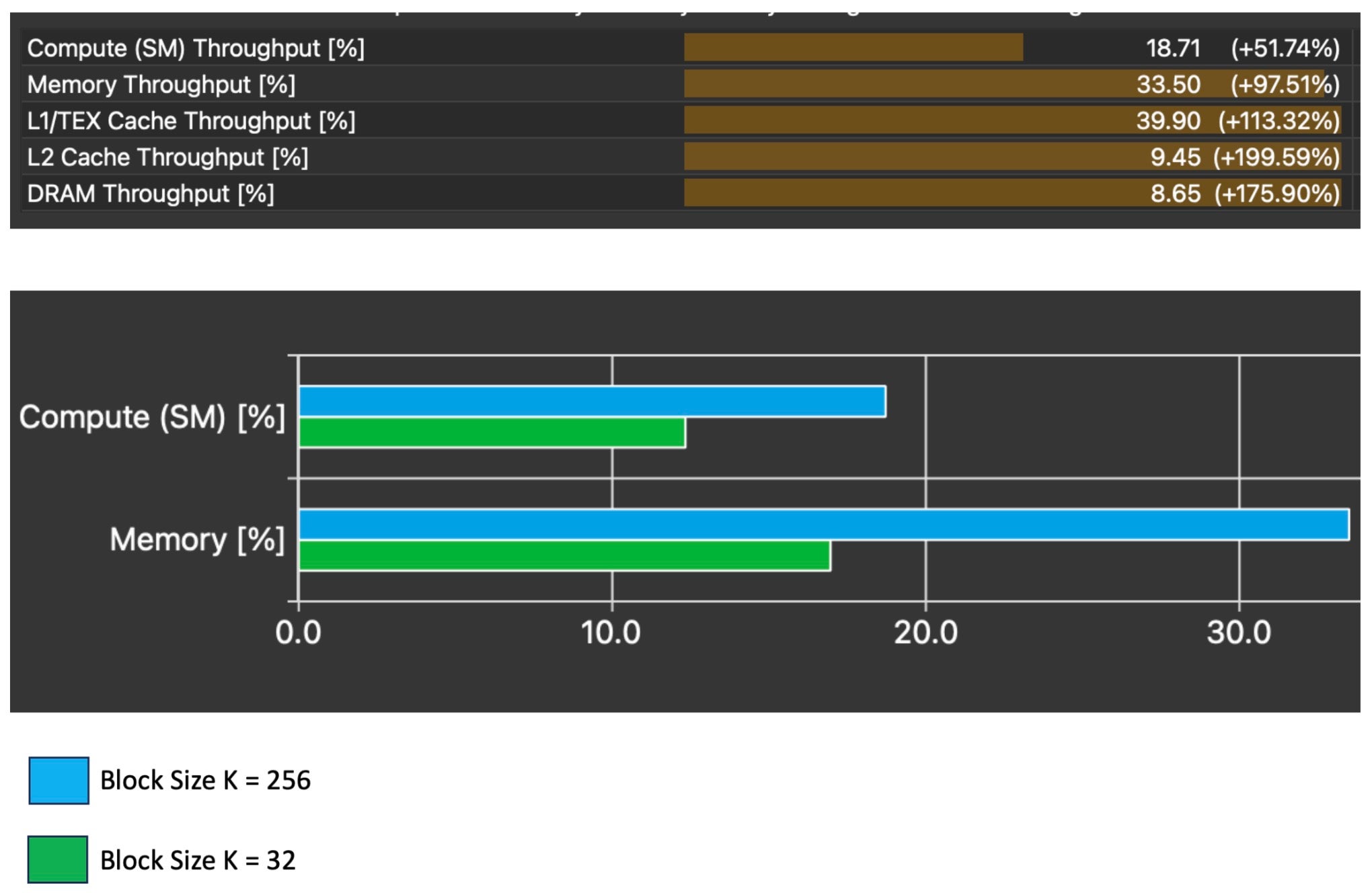
我们还看到,在量化权重进行移位和缩放的步骤中,长记分板等待时间显著下降,而这正是我们在源代码中识别出的原始瓶颈。尽管在此行仍存在停滞,但只有 68% 是由长记分板停滞引起的,而原始比例为 92%。理想情况下,我们不希望看到任何停滞,所以这里仍有工作要做,但长记分板引起的停滞数量减少告诉我们,此时我们的数据(在 L1TEX 内存中)以比原始内核更高的频率准备好供 warp 想要执行的指令使用。

相应的影响是内核执行时间加快了 1.4 倍。
6.0 结果
通过系统地解决所有这些问题区域,我们最终的内核在 Nvidia A100 GPU 上比开箱即用的 AutoGPTQ Triton 内核快 6 倍。
以一个相关的 Llama 推理样本数据点为例,我们开发的 Triton 内核只需 47 微秒即可完成反量化和矩阵乘法,而 AutoGPTQ 内核对于相同大小的矩阵则需要 275 微秒。
通过复制这种循序渐进的方法,应该可以在其他内核中获得类似的加速,并有助于加深对常见 GPU 瓶颈及其解决方法。
需要注意的是,虽然 AutoGPTQ Triton 内核的性能得到了显著提升,但我们尚未完全弥补与 AutoGPTQ 中现有 exllamaV2 CUDA 内核之间的差距。
需要进行更多研究,以了解如何进一步优化此内核,使其达到与自定义 CUDA 内核相当的性能。
总结与未来工作
Triton 通过允许在比 CUDA 编程更高层次的抽象级别上进行低级 GPU 优化来扩展 PyTorch,最终结果是添加优化的 Triton 内核可以帮助 PyTorch 模型运行得更快。
我们在这篇文章中的目标是展示一个加速 GPTQ 反量化内核的示例,并提供实现加速的模板工作流程。
对于未来的工作,我们将研究矩阵乘法的 SplitK 工作分解作为潜在的加速方法。
将自定义 Triton 内核集成到 PyTorch 中
鉴于上面所示的加速,一个常见的问题是如何在给定的 PyTorch 代码库中实际使用自定义内核。
一个 Triton 内核将至少包含两部分——实际的 Triton 内核代码,它将由 Triton 编译器编译。
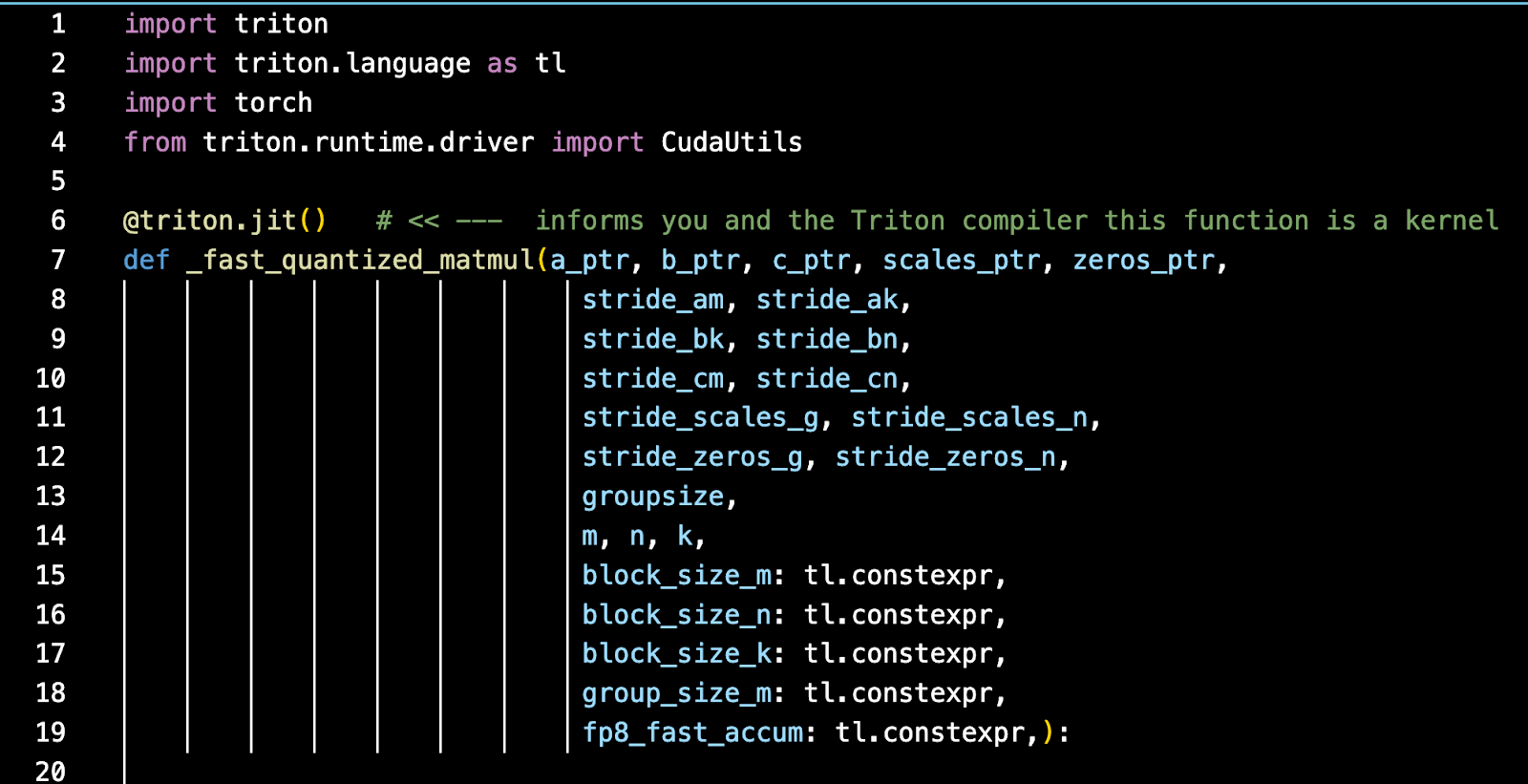
除了实际的内核代码,还有一个 Python 包装器,它可能会或可能不会继承 PyTorch autograd 类——这取决于它是否支持反向传播(即用于训练目的或仅用于推理目的)。
您只需将 Python 类导入到您想要使用的 PyTorch 代码中,就像使用任何其他 Python / PyTorch 函数一样。
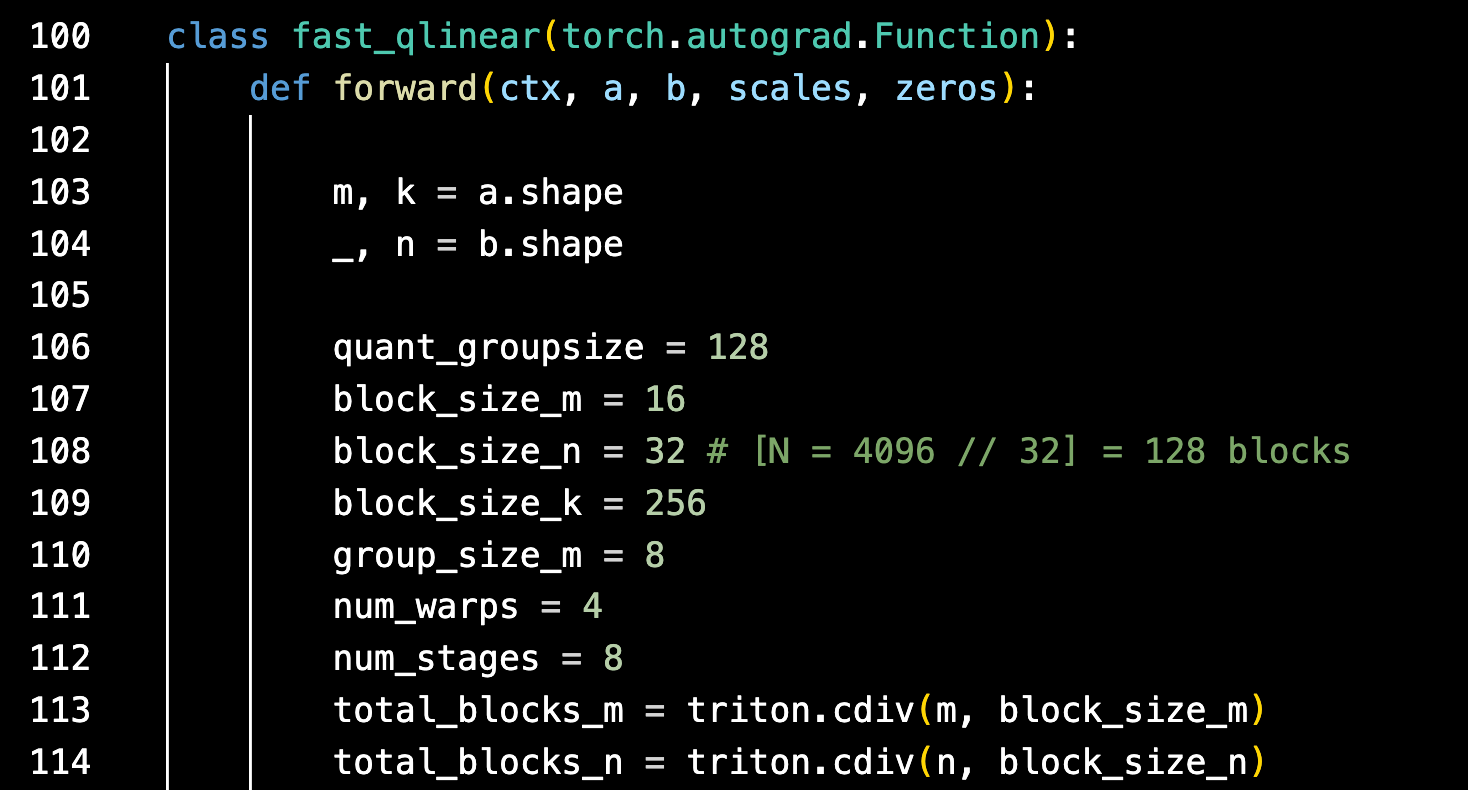
在这种情况下,简单地导入并使用“fast_qlinear”将调用底层的 Triton 内核,并将其上面展示的加速应用于您的 PyTorch 模型。
致谢
感谢 IBM Research 的 Jamie Yang 和 Hao Yu 在这些结果收集过程中提供的技术指导。