概述
在运行视觉模型时,内存格式对性能有显著影响,通常“通道优先”(Channels Last)由于更好的数据局部性,从性能角度来看更为有利。
本博客将介绍内存格式的基本概念,并演示在Intel® Xeon® 可扩展处理器上,使用“通道优先”在流行的PyTorch视觉模型上带来的性能优势。
内存格式介绍
内存格式是指数据表示形式,它描述了多维(nD)数组如何存储在线性(1D)内存地址空间中。内存格式的概念有两个方面:
- 物理顺序是指数据在物理内存中的存储布局。对于视觉模型,我们通常谈论NCHW和NHWC。这些是物理内存布局的描述,也分别称为“通道优先”(Channels First)和“通道居后”(Channels Last)。
- 逻辑顺序是描述张量形状和步幅的约定。在PyTorch中,此约定为NCHW。无论物理顺序如何,张量的形状和步幅将始终以NCHW的顺序描述。
图1显示了形状为[1, 3, 4, 4]的张量在“通道优先”和“通道居后”内存格式下的物理内存布局(通道分别表示为R、G、B)

图1 “通道优先”和“通道居后”的物理内存布局
内存格式传播
PyTorch内存格式传播的一般规则是保留输入张量的内存格式。这意味着“通道优先”的输入将生成“通道优先”的输出,而“通道居后”的输入将生成“通道居后”的输出。
对于卷积层,PyTorch默认使用oneDNN(oneAPI深度神经网络库)在Intel CPU上实现最佳性能。由于直接使用“通道优先”内存格式无法实现高度优化的性能,因此输入和权重首先被转换为分块格式,然后进行计算。oneDNN可能会根据输入形状、数据类型和硬件架构选择不同的分块格式,以实现向量化和缓存重用。分块格式对PyTorch是不透明的,因此输出需要转换回“通道优先”格式。尽管分块格式可以带来最佳计算性能,但格式转换可能会增加开销,从而抵消性能提升。
另一方面,oneDNN针对“通道居后”内存格式进行了优化,可以直接使用它以获得最佳性能,PyTorch将简单地将内存视图传递给oneDNN。这意味着节省了输入和输出张量的转换。图2显示了PyTorch CPU上卷积的内存格式传播行为(实线箭头表示内存格式转换,虚线箭头表示内存视图)
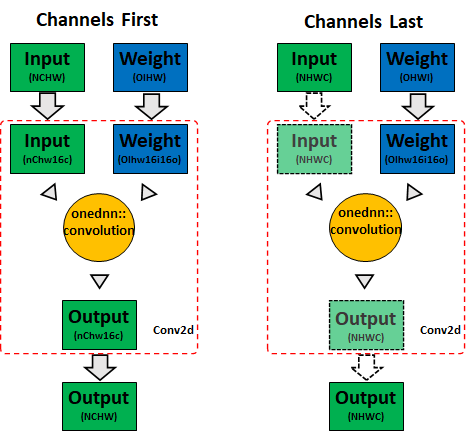
图2 CPU卷积内存格式传播
在PyTorch中,默认的内存格式是“通道优先”。如果某个特定运算符不支持“通道居后”,NHWC输入将被视为不连续的NCHW,因此会回退到“通道优先”,这将在CPU上消耗之前的内存带宽并导致次优性能。
因此,扩展“通道居后”支持的范围对于获得最佳性能至关重要。我们已经为CV领域常用运算符(推理和训练均适用)实现了“通道居后”核,例如:
- 激活函数(例如ReLU、PReLU等)
- 卷积(例如Conv2d)
- 归一化(例如BatchNorm2d、GroupNorm等)
- 池化(例如AdaptiveAvgPool2d、MaxPool2d等)
- 混洗(例如ChannelShuffle、PixelShuffle)
详情请参阅支持“通道居后”的运算符。
“通道居后”的本地级别优化
如上所述,PyTorch使用oneDNN在Intel CPU上实现卷积的最佳性能。其余内存格式感知运算符在PyTorch本地级别进行优化,无需任何第三方库支持。
- 缓存友好的并行化方案:为所有内存格式感知运算符保持相同的并行化方案,这将有助于在将每个层的输出传递给下一层时提高数据局部性。
- 多架构向量化:通常,我们可以在“通道居后”内存格式的最内层维度进行向量化。每个向量化的CPU核将同时为AVX2和AVX512生成。
在贡献“通道居后”核的同时,我们也尽力优化了“通道优先”对应的核。事实上,有些运算符在“通道优先”下无法实现最佳性能,例如卷积、池化等。
在“通道居后”上运行视觉模型
“通道居后”相关的API已在PyTorch内存格式教程中记录。通常,我们可以通过以下方式将4D张量从“通道优先”转换为“通道居后”:
# convert x to channels last
# suppose x’s shape is (N, C, H, W)
# then x’s stride will be (HWC, 1, WC, C)
x = x.to(memory_format=torch.channels_last)
要在“通道居后”内存格式上运行模型,只需将输入和模型转换为“通道居后”,即可开始运行。以下是一个最小示例,展示了如何在“通道居后”内存格式下运行带TorchVision的ResNet50:
import torch
from torchvision.models import resnet50
N, C, H, W = 1, 3, 224, 224
x = torch.rand(N, C, H, W)
model = resnet50()
model.eval()
# convert input and model to channels last
x = x.to(memory_format=torch.channels_last)
model = model.to(memory_format=torch.channels_last)
model(x)
“通道居后”优化是在本地内核级别实现的,这意味着您可以将其他功能(如torch.fx和torch script)与“通道居后”一起应用。
性能提升
我们在Intel® Xeon® Platinum 8380 CPU @ 2.3 GHz上对TorchVision模型的推理性能进行了基准测试,每个插槽单实例(批处理大小=2 x 物理核心数)。结果显示,“通道居后”比“通道优先”具有1.3倍到1.8倍的性能提升。
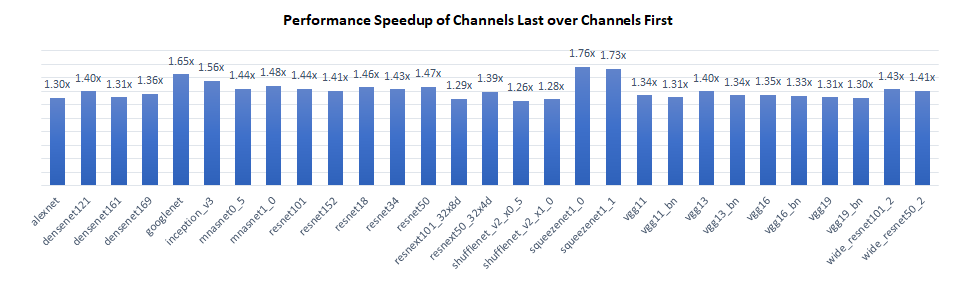
性能提升主要来自两个方面:
- 对于卷积层,“通道居后”节省了激活层到分块格式的内存格式转换,从而提高了整体计算效率。
- 对于池化和上采样层,“通道居后”可以在最内层维度(例如“C”)使用向量化逻辑,而“通道优先”则不能。
对于不感知内存格式的层,“通道居后”和“通道优先”具有相同的性能。
结论与未来工作
在本博客中,我们介绍了“通道居后”的基本概念,并演示了在CPU上使用“通道居后”在视觉模型上的性能优势。目前的工作仅限于2D模型,我们将在不久的将来将优化工作扩展到3D模型!
致谢
本博客中呈现的结果是Meta和Intel PyTorch团队共同努力的成果。特别感谢Meta的Vitaly Fedyunin和Wei Wei,他们付出了宝贵的时间并提供了实质性帮助!我们共同为改善PyTorch CPU生态系统迈出了又一步。