在这篇文章中,我们介绍了一个优化的 Triton BF16 分组 GEMM 内核,用于在专家混合 (MoE) 模型(例如 DeepSeekv3)上运行训练和推理。
分组 GEMM 在一次内核调用中对输入张量的多个切片(组)应用独立的 GEMM。在基线 PyTorch 实现中,这些 GEMM 将在组的 for 循环中执行,每次迭代启动一个内核。
我们的内核在 DeepSeekv3 训练中,与手动 PyTorch 循环实现相比,在 NVIDIA H100 GPU 上实现了高达 2.62 倍的加速。我们讨论了所利用的 Triton 内核优化技术,并展示了端到端的结果。
使用 FSDP2 的 8x NVIDIA H100 上 16B DeepSeekv3 TPS 吞吐量
Triton 内核分组 GEMM 与 PyTorch 手动循环分组 GEMM(1.42 倍-2.62 倍加速)
背景
GEMM(通用矩阵乘法)是 LLM 工作负载中的基本原语。当输入激活矩阵乘以权重矩阵时,就执行了 GEMM。在现代基于深度学习的架构中,GEMM 占据了 FLOP 计数的主导地位,因此它们的效率通常决定了端到端模型的速度。
在专家混合 (MoE) 模型中,令牌被动态路由到不同的专家,从而导致许多独立的 GEMM。分组 GEMM 在一次内核启动中执行多个较小的 GEMM。我们不是将每个专家或层视为一个独立的 GEMM,而是将它们批量处理,这减少了启动开销并提高了 GPU 利用率。

图 1. 具有 3 个专家的 GEMM 问题示例
为了说明这一点,我们可以想象一个玩具场景,我们有 3 个专家权重,以及数量不等的令牌被路由到每个专家,因此激活的大小不同。我们可以将这 3 个不同大小的矩阵乘法构建成一个分组 GEMM 问题,这使我们能够在一个内核启动中计算输出矩阵 C1、C2 和 C3。
优化 1:持久化内核设计
Nvidia GPU 具有流式多处理器单元 (SM),其中包含专门的硬件单元来执行加载、存储和计算操作。SM 利用率是内核性能的关键。因此,在使用 Triton 编程语言实现并行算法(如分组矩阵乘法)时,一个关键的考虑因素是 SM 之间工作分解。
在朴素的工作划分中,每个工作块都会启动一个新的线程块 (CTA)。相比之下,持久化内核使 CTA“保持活动”并动态地向它们提供新的工作块,直到整个 GEMM 完成。这避免了启动开销,提高了缓存重用,并减少了调度不平衡,这可能导致称为波量化的效应。波量化是一种低效率,当输出块的数量不能被 GPU SM 的数量均匀整除时发生,从而导致低利用率。这篇 Colfax 文章深入探讨了该主题。
我们通过在分组 GEMM 内核中应用持久化内核策略来构建这个想法。在 MoE 模型的训练和预填充工作负载中,矩阵乘法问题大小很大。因此,在朴素的工作分解中,需要调度大量的线程块来计算输出矩阵,这将导致多波工作。相反,通过我们的持久化内核设计,我们可以通过在 Triton 内核中进行两个关键更改来在单波工作中计算整个矩阵乘法,如下面代码片段中讨论的那样。
首先,我们将内核网格设置为等于 H100 GPU 上的 SM 数量,即 132。
grid = (NUM_SMS, 1, 1) (Host Code)
接下来,我们将外部 for 循环结构更改为
for tile_id in tl.range(start_pid, num_tiles, NUM_SMS) (Device Code)
我们为每个 SM 启动一个 Triton 程序,因此所有 Triton 程序都适合单个波中,没有程序在队列中等待。在内核内部,每个程序循环遍历其分配的工作块,获取新工作直到所有工作块都计算完毕。这种设计使 Triton 程序在 SM 上保持活动状态,消除了重复启动,并使 GEMM 成为一个连续的工作波。
优化 2:分组启动顺序
内核速度的一个重要考虑因素是缓存性能。在 Triton 中,程序员控制输出块的计算顺序,因此我们可以在内核级别优化 L2 缓存性能。我们尝试了线性块排序(行主序)和分组启动排序调度。为了说明这两种方法之间的差异,我们可以检查以下玩具矩阵乘法示例,其中 A 和 B 是输入矩阵,C 是输出矩阵。
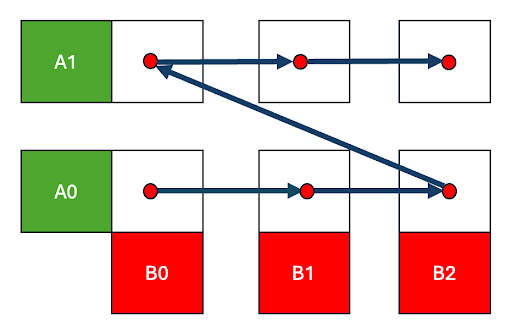
图 2. 行主序调度
在输出 C 矩阵的行主序遍历中,我们快速地遍历 B 矩阵和 C(0,0) -> C(0,1) -> C(0,2) 的列,然后移动到下一行 C(1,0)。这意味着 B 块只有在遍历完 C 的整行之后才会被重新访问,届时数据可能已经被逐出。
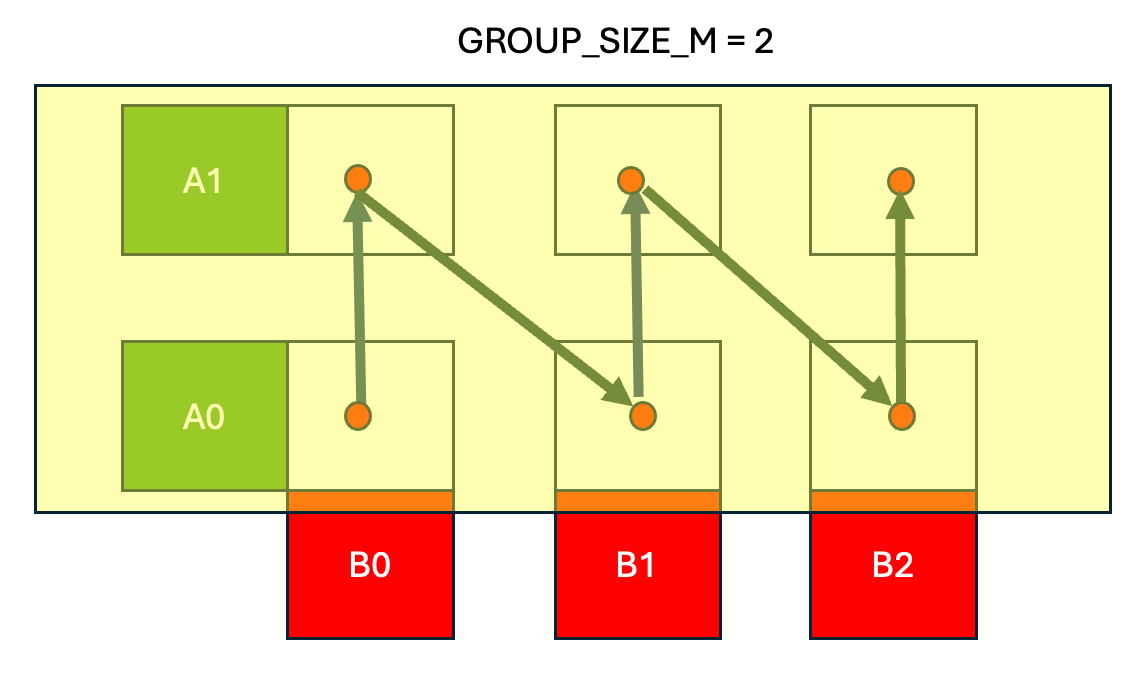
图 3. 分组启动调度,组大小 = 2
在 分组启动调度中,我们保持 A 矩阵中的一行带(图 3 中为 2)在缓存中,并按列主序遍历输出 C 矩阵,计算 C(0,0) -> C(1,0) ->…-> C(GROUP_SIZE_M, 0),然后移动到下一列并计算 C(0,1) -> C(1,1) 等。
最终结果是,分组启动调度提高了 A 和 B 矩阵的缓存性能。连续的 Triton 程序 (CTA) 快速连续地重用相同的 B 块,同时将 A 行带保留在缓存中。
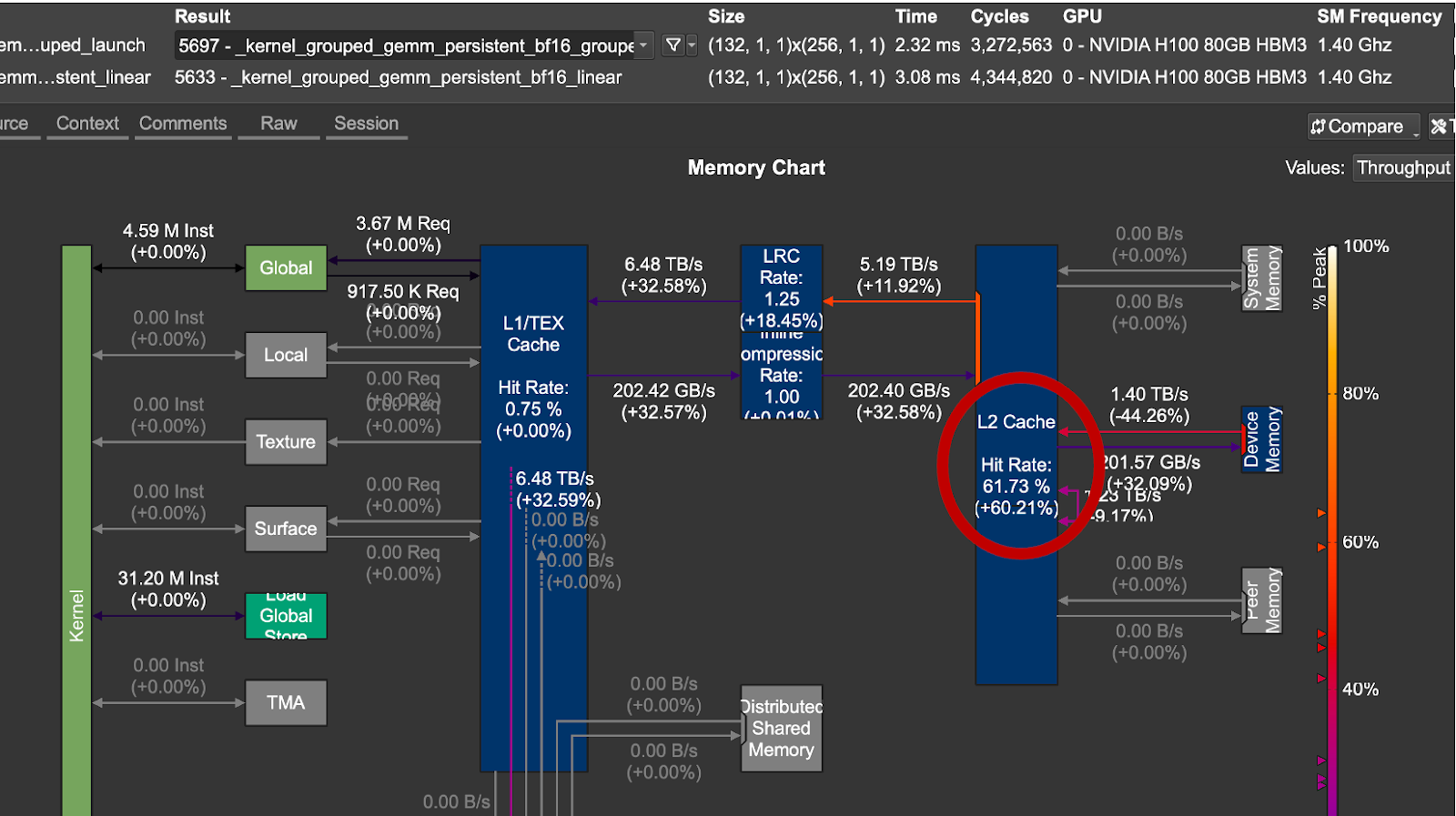
图 4. 分组启动顺序与线性启动顺序的 L2 缓存增益
num_groups, m, k, n = 8, 4096, 2048, 7168
对于我们测试的问题大小,分组启动顺序在数据重用和延迟方面表现更好。从上图 4 中,我们注意到优化的调度实现了 1.33 倍 的加速和 +60% 的 L2 缓存命中率。
在我们的分组 GEMM 内核中使用分组启动调度的主要好处是它强制执行时间局部性,如上图所示。这是通过重新排序程序的启动顺序来实现的,以便以允许更好地重用输入激活和专家权重的顺序计算 GEMM 问题的块,从而提高 L2 缓存命中率,增加算术强度,从而减少内核延迟。
优化 3:专家权重张量内存加速器 (TMA) 利用率
NVIDIA Hopper GPU 上的 TMA 单元是用于张量加载/存储操作的专用硬件单元。在我们的内核设计中利用 TMA 单元的好处是,当数据从全局内存移动到共享内存时,它可以释放 SM 资源,例如寄存器和 CUDA 核心。要了解有关 Triton 中 TMA 用法的更多信息,请参阅我们之前关于此主题的深入探讨。
然而,由于该内核的特殊用例,存在一个注意事项。通常,包含张量元数据的 TMA 描述符是在主机上创建的,然后传递给内核。
对于 MoE 模型,需要修改方法,因为所选专家是预先未知的。相反,它在运行时确定,从而创建对专家权重矩阵的数据依赖访问。这种类型的访问在 Triton 中是可能的,方法是根据所选专家索引动态创建本地 TMA 描述符。我们将在下面的代码中演示如何为所选专家在设备上构建 TMA 2D 描述符,以及如何使用它来发出 TMA 加载。
首先,我们在主机上预分配一块 GPU 内存,即工作区
workspace = torch.empty( NUM_SMS * desc_helper.tma_size, #Host Code device=x.device, dtype=torch.uint8)
我们保留的内存大小等于单个 TMA 描述符的大小(以字节为单位),desc_helper.tma_size,乘以我们正在启动的持久化 Triton 程序的数量,NUM_SMs。这确保了每个 Triton 程序都有空间来写入自己的 TMA 描述符。
expert_desc_ptr_tile = workspace + start_pid * TMA_SIZE tl.extra.cuda.experimental_device_tensormap_create2d( desc_ptr= expert_desc_ptr_tile, global_address=b_ptr + expert_idx*N*K + n_start*K, (Device Code) load_size=[BLOCK_SIZE_N, BLOCK_SIZE_K], global_size=[NUM_EXPERTS*N, K], element_ty=tl.bfloat16) tl.extra.cuda.experimental_tensormap_fenceproxy_acquire(expert_desc_ptr_tile) expert_weight = tl._experimental_descriptor_load( expert_desc_ptr_tile, [0, k_offset], [BLOCK_SIZE_N, BLOCK_SIZE_K], tl.bfloat16)
在 Triton 代码中,每个 Triton 程序首先在工作区中创建一个私有槽来放置专家描述符。接下来,我们通过传递专家元数据来创建一个指向路由专家块的 2D 张量映射。然后,我们显式调用一个代理栅栏,这是在两个不同的代理(SM 和 TMA 引擎)之间同步内存操作所必需的。在我们的内核中,每当选择一个新的 expert_idx 时,SM 都会将新的 TMA 描述符写入全局内存。栅栏保证在 TMA 引擎发出加载指令之前,新的 TMA 描述符是全局可见的。这确保我们不会读取陈旧/不正确的数据。
现在,由于 TMA 描述符是根据所选的 expert_idx 动态构建的,因此分组 GEMM 内核中的每个 Triton 程序都可以将其 TMA 加载定向到路由的专家权重。
微基准测试
我们将我们的 Hopper 优化内核与不包含我们讨论的优化的基线 Triton 分组 GEMM 内核进行了基准测试,以隔离这些技术带来的增益。
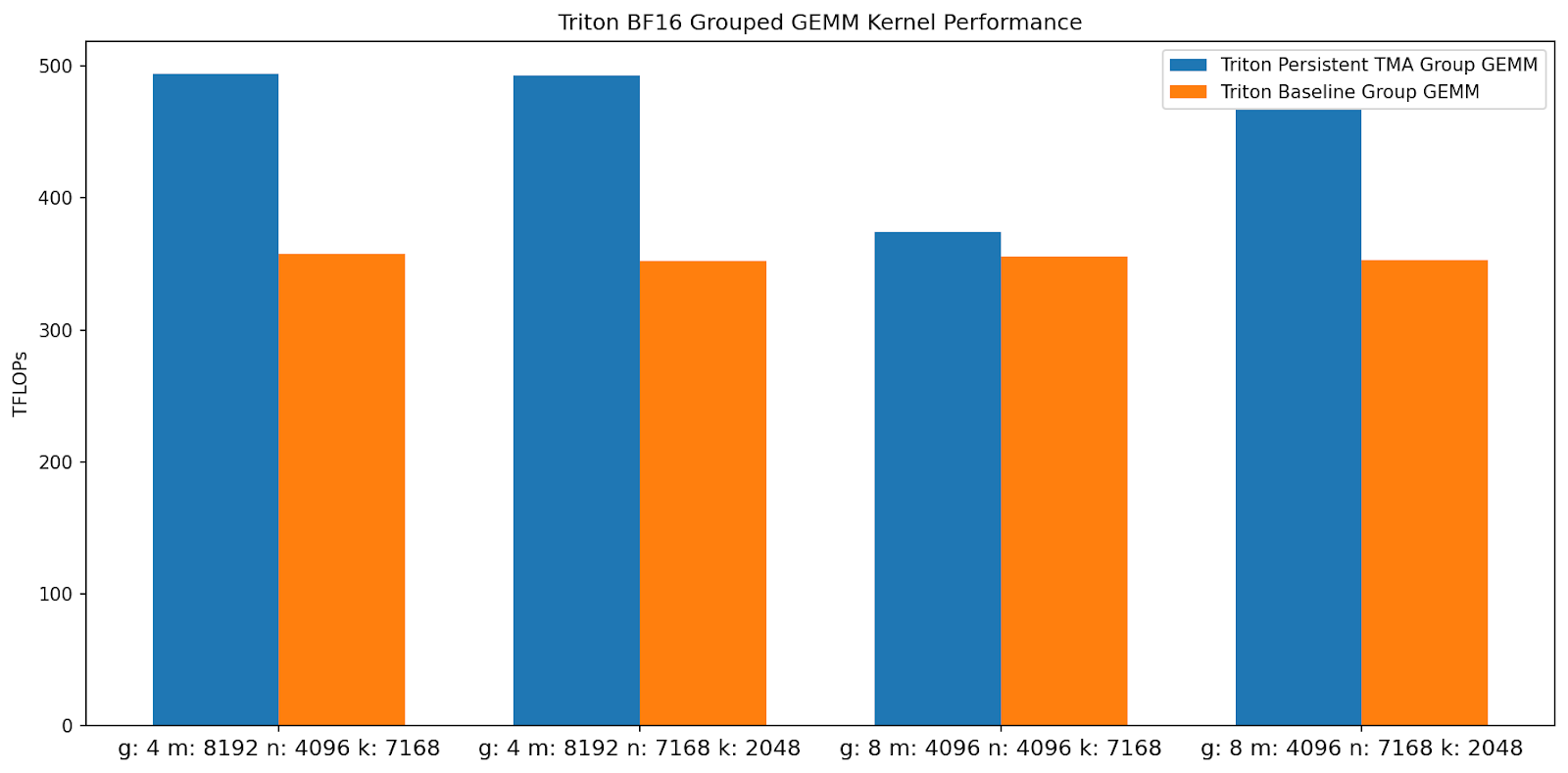
图 5. Triton 分组 GEMM 内核 TFLOPs 比较(越高越好)
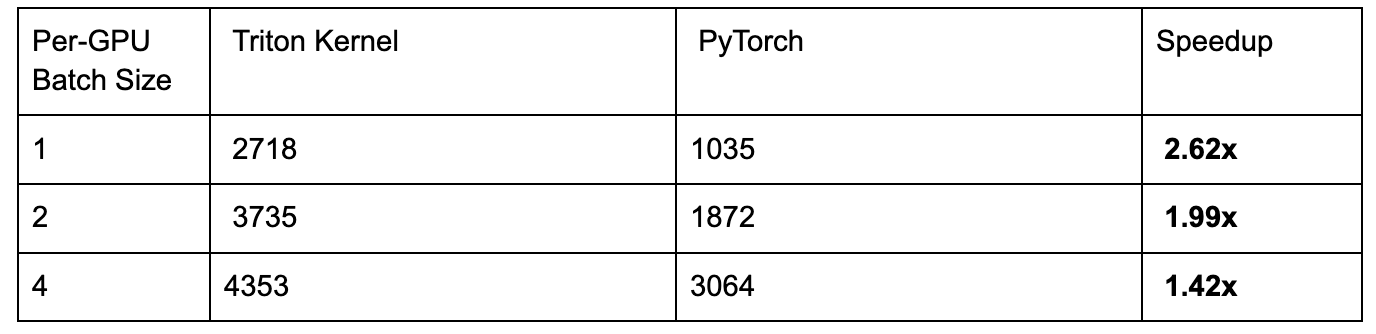
图 6. 内核延迟比较及相对于基线 Triton 内核的加速
通过利用持久化内核设计、分组启动块排序和 Hopper TMA 单元,我们的内核比基线 Triton 内核实现了高达 1.50 倍 的加速。
端到端基准测试
我们将内核集成到 torchtitan 中,以创建一个端到端测试,其中我们使用 FSDP2 在 8xH100 上训练 16B 参数的 DeepSeekv3 模型。不同批次大小的加速如下:

图 7. 16B DeepSeekv3 E2E 每秒令牌数/GPU 吞吐量汇总
MoE 模型的参数与 FLOPs 比率远高于密集模型,这一事实使得 FSDP2 对于训练来说不是最优的,因为通信大权重成本很高。相反,通过将不同的专家静态放置在不同的 GPU 上并通信激活来并行化会更有益。在这种专家并行训练中,每个 GPU 处理的令牌数量是动态变化的,这使得 Triton 内核的使用具有挑战性,因为每个新的令牌计数可能需要内核重新编译,具体取决于实现的细节。我们将对这种动态训练工作负载的支持留待未来的工作。
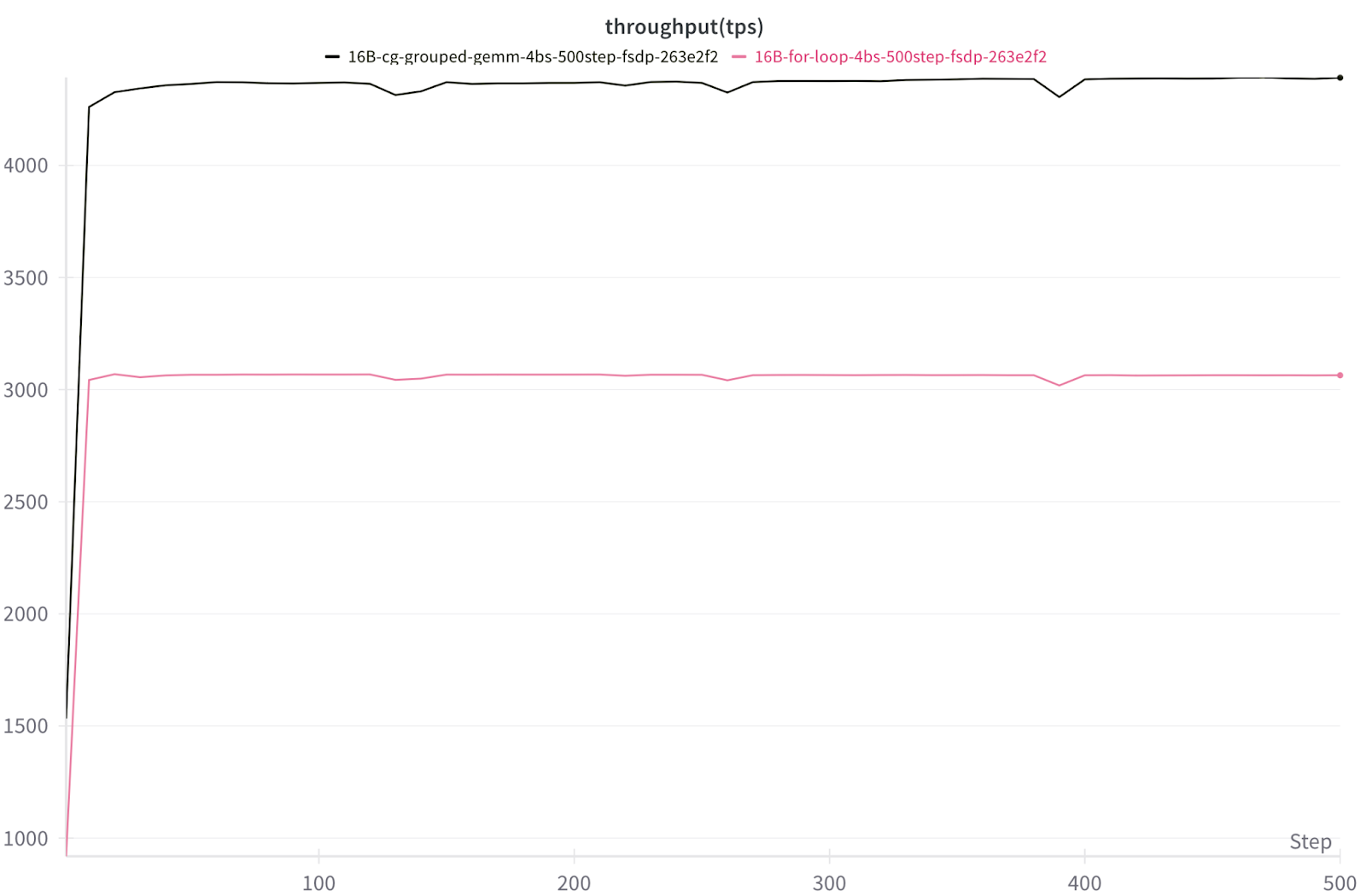
训练 (torchtitan)
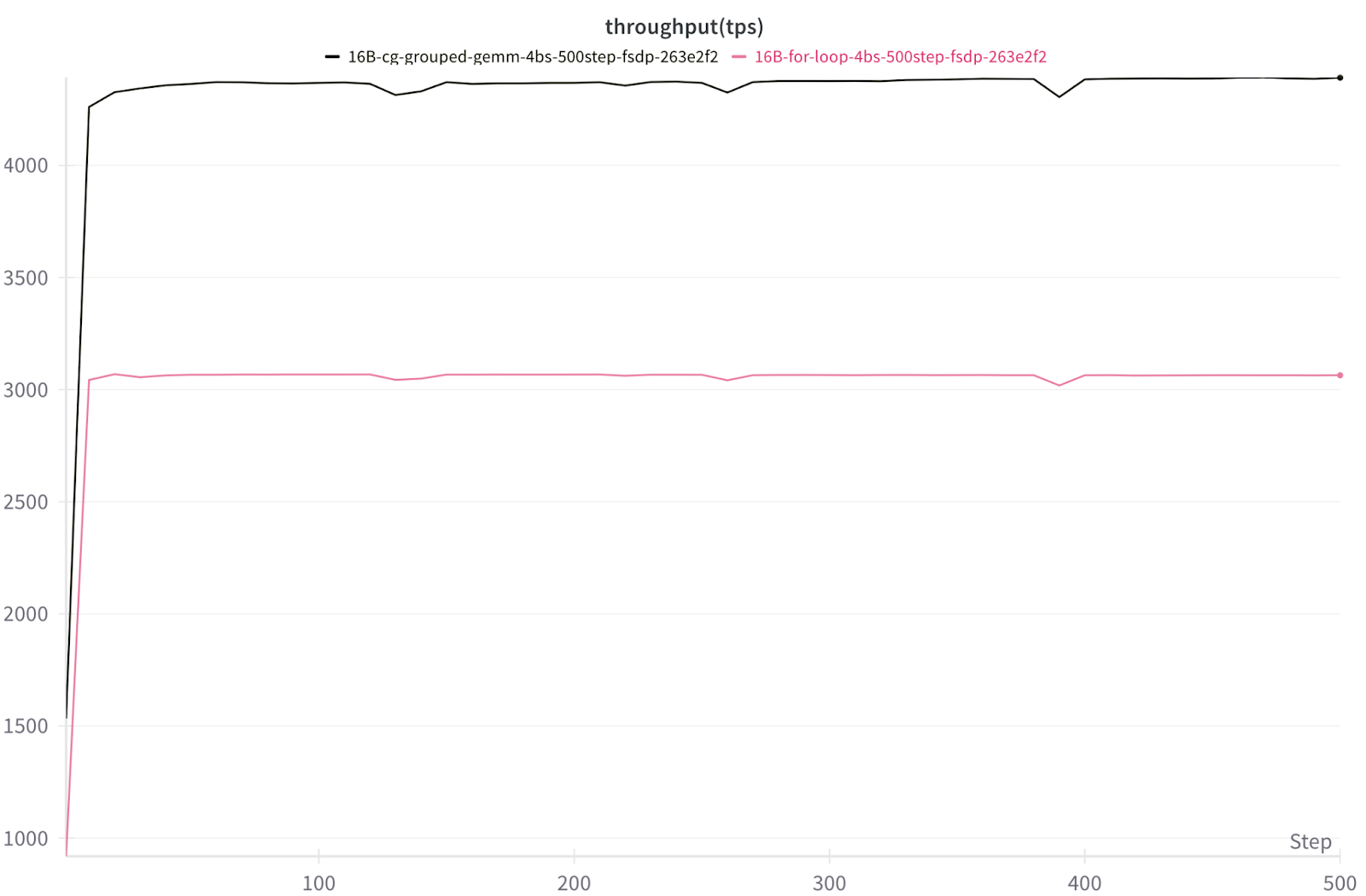
图 8. 在 8x NVIDIA H100 上使用 FSDP2 训练批次大小为 4 的 16B DeepSeekv3 的每秒令牌数/GPU

训练 (torchtitan)
图 9. 在 8x NVIDIA H100 上使用 FSDP2 训练 16B DeepSeekv3 的 Triton 与 for 循环的损失曲线比较
结论
未来的工作,我们计划将我们的内核集成到 vLLM(正在进行的 PR 在此处),并扩展此内核以支持前向和后向的 FP8。我们的内核可以从 torchtitan 在此处利用。 此外,我们还计划试验更低精度的datatypes,例如 MXFP4,这些 datatype 受到新一代 NVIDIA GPU(如 B200)的支持。