1.0 摘要
我们展示了通过实施列主序调度以改善数据局部性,我们可以将 MoE(混合专家)的核心 Triton GEMM(通用矩阵乘法)核在 A100 上加速高达 4 倍,在 H100 Nvidia GPU 上加速高达 4.4 倍。本文演示了几种不同的 MoE GEMM 工作分解和调度算法,并从硬件层面展示了为什么列主序调度能产生最高的速度提升。
代码库和代码可在以下链接获取:https://github.com/pytorch-labs/applied-ai/tree/main/kernels/triton/inference/col_major_moe_gemm。
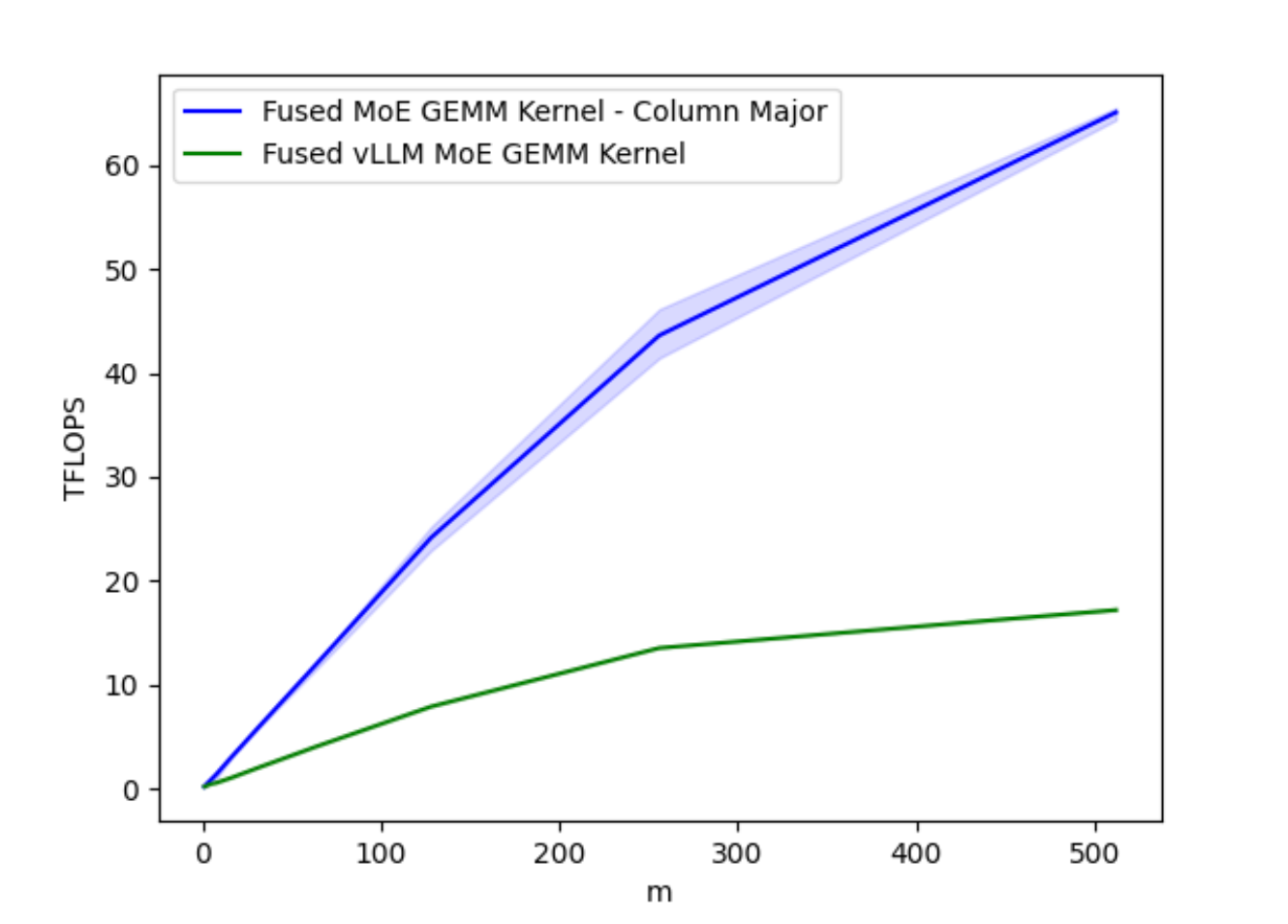
图1A. 针对不同批量大小 M 优化的融合 MoE GEMM 核在 A100 上的 TFLOPs
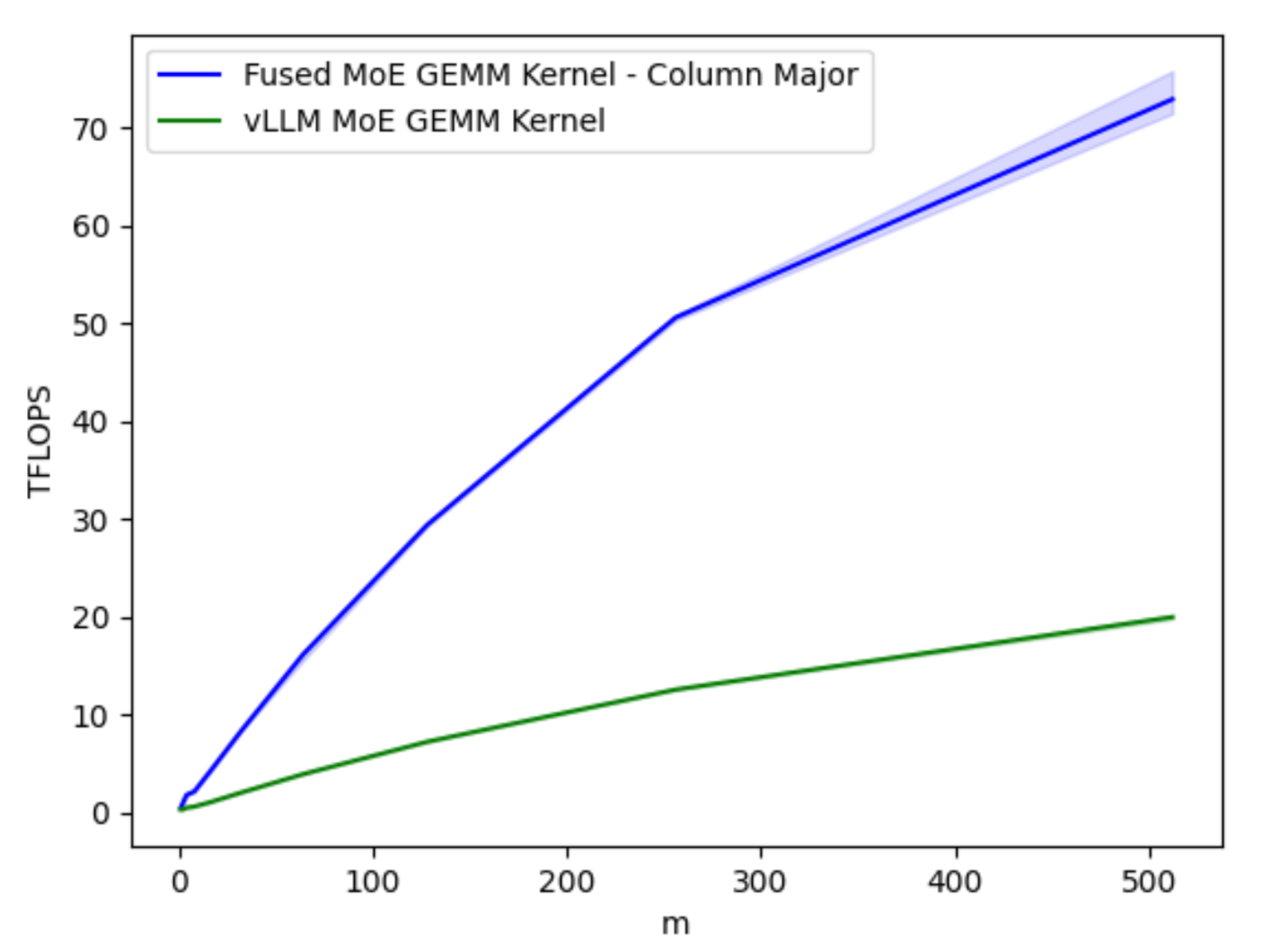
图1B. 针对不同批量大小 M 优化的融合 MoE GEMM 核在 H100 上的 TFLOPs
2.0 背景
OpenAI 的 Triton 是一种与硬件无关的语言和编译器,正如我们之前的博文所示,它可用于加速量化工作流。我们还展示了在核开发方面,CUDA 的许多相同经验和性能分析工具可用于深入了解 Triton 核的内部工作原理,并随后采取措施在延迟敏感的环境中加速这些核。随着 Triton 在生产环境中得到越来越多的采用,开发人员了解开发高性能核的常见技巧和窍门,以及这些方法对各种不同架构和工作流的通用性至关重要。因此,本文将探讨我们如何使用经典技术优化 vLLM 为流行的混合专家 (MoE) Mixtral 模型开发的 Triton 核,以及如何在 Triton 中实现这些技术以获得性能提升。
Mixtral 8x7B 是一种稀疏混合专家语言模型。与经典的密集 Transformer 架构不同,每个 Transformer 块包含 8 个 MLP 层,每个 MLP 都是一个“专家”。当一个 token 流经时,一个路由器网络会选择 8 个专家中的哪 2 个来处理该 token,然后将结果组合起来。同一 token 在每个层中选择的专家不同。因此,尽管 Mixtral 8x7B 总共有 47B 参数,但在推理时只有 13B 参数是活跃的。
MoE GEMM(通用矩阵乘法)核接收一个包含所有专家的堆叠权重矩阵,然后必须利用路由器网络产生的得分映射数组,将每个 token 路由到 TopK(Mixtral 为 2)专家。在本文中,我们提供了在推理时(特别是在自回归(或解码阶段))高效并行化这种计算的方法。
3.0 工作分解 – SplitK
我们之前已经展示,对于 LLM 推理中的矩阵问题大小,特别是在 W4A16 量化推理的上下文中,可以通过应用SplitK 工作分解来加速 GEMM 核。因此,我们通过在vLLM MoE 核中实现 SplitK 来开始我们的 MoE 加速研究,这比数据并行方法产生了大约 18-20% 的速度提升。
该结果表明,SplitK 优化可作为在推理设置中改进/开发 Triton 核的更规范方法的一部分。为了对这些不同的工作分解建立直观理解,我们来看一个简单的 4×4 矩阵乘法和 SplitK=2 的例子。
在下面所示的数据并行 GEMM 核中,输出矩阵的单个块的计算将由 1 个线程块 TB0 处理。
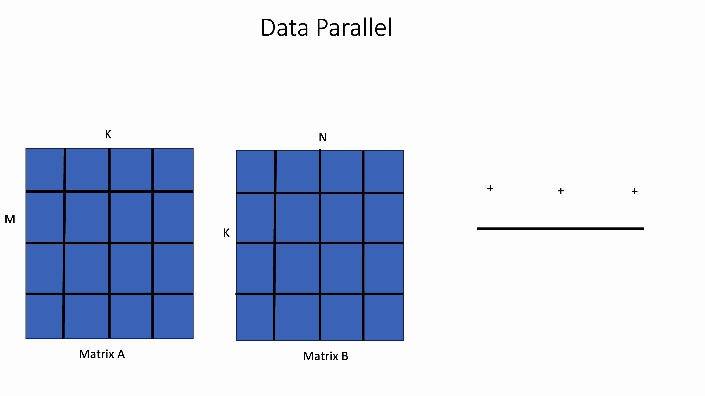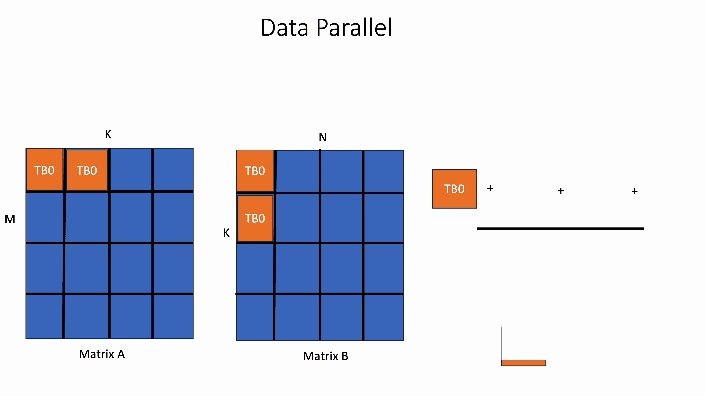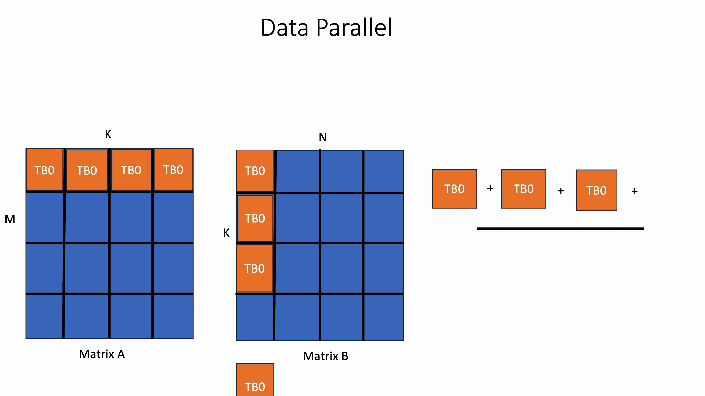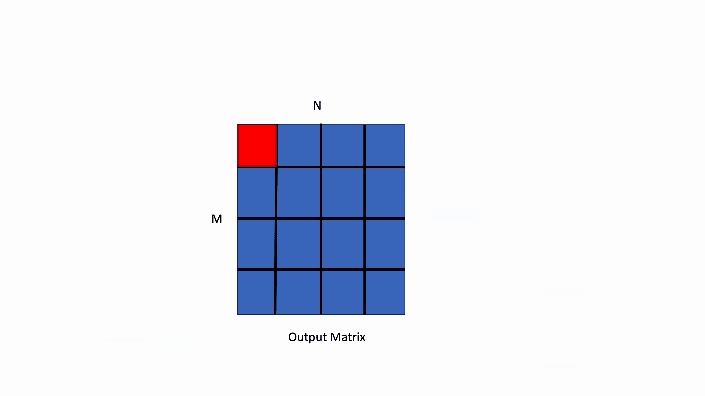
图2. 数据并行 GEMM
相比之下,在 SplitK 核中,计算输出矩阵中 1 个块所需的工作被“分割”或共享给 2 个线程块 TB0 和 TB1。这提供了更好的负载平衡和更高的并行度。
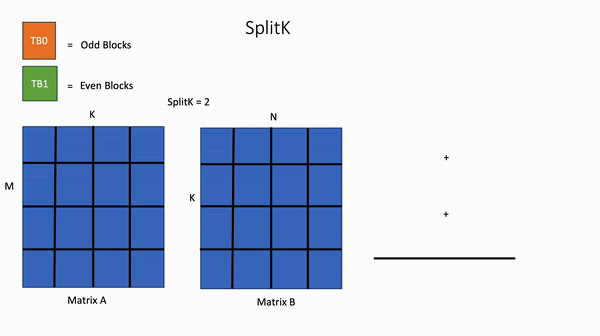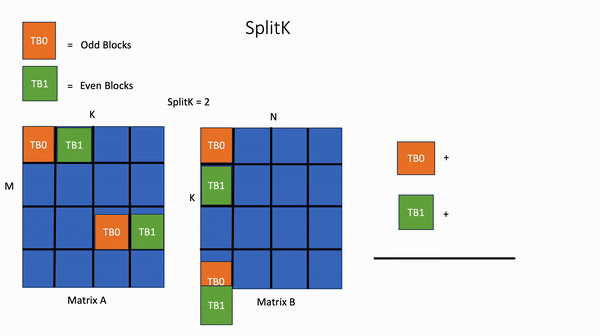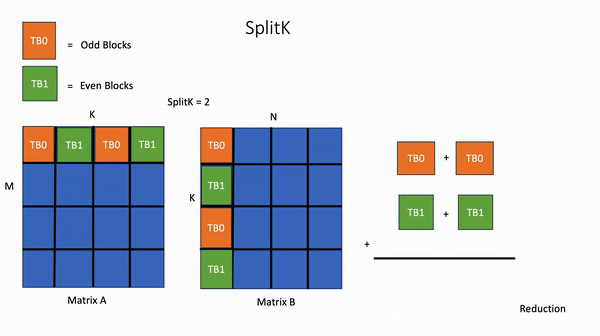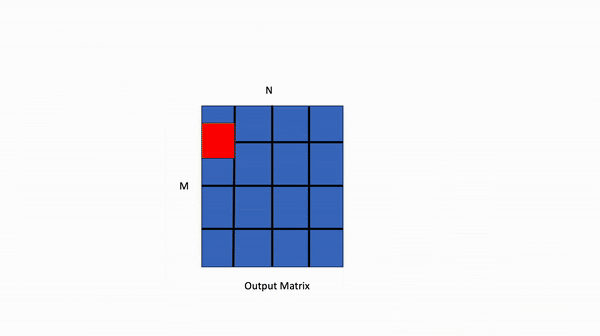
图3. SplitK GEMM
关键思想是我们将并行度从 M*N 增加到 M*N*SplitK。这种方法确实会产生一些成本,例如通过原子操作增加线程块间通信。然而,与共享内存和寄存器等其他受限 GPU 资源的节省相比,这些成本是微不足道的。最重要的是,SplitK 策略为瘦矩阵(如 MoE 推理中常见的情况)提供了卓越的负载平衡特性,并且是解码和推理期间常见的矩阵配置文件。
4.0 GEMM 硬件调度——列主序
为了在 SplitK 基础上进一步提高约 20% 的加速,我们将研究重点放在控制 Triton 核中 GEMM 硬件调度的逻辑上。我们对 vLLM MoE 核的性能分析显示 L2 缓存命中率较低,因此我们研究了三种调度选项——列主序、行主序和分组启动。由于 MoE 模型的一些固有特性,例如大型专家矩阵,以及在核执行期间必须动态加载 TopK(Mixtral 为 2)矩阵,缓存重用/命中率成为一个瓶颈,此优化将解决此问题。
作为背景,在我们之前的博客中,我们提到了“瓦片交错”的概念,这是一种实现更高 L2 缓存命中率的方法。这个概念与软件如何将 GEMM 调度到 GPU 的 SMs 相关。在 Triton 中,这个调度是由 pid_m 和 pid_n 计算决定的。我们的关键见解是,对于瘦矩阵乘法,列主序调度确保了权重矩阵 B 的列的最佳重用。为了说明这一点,让我们看一下列主序计算 pid_m 和 pid_n 的代码片段。
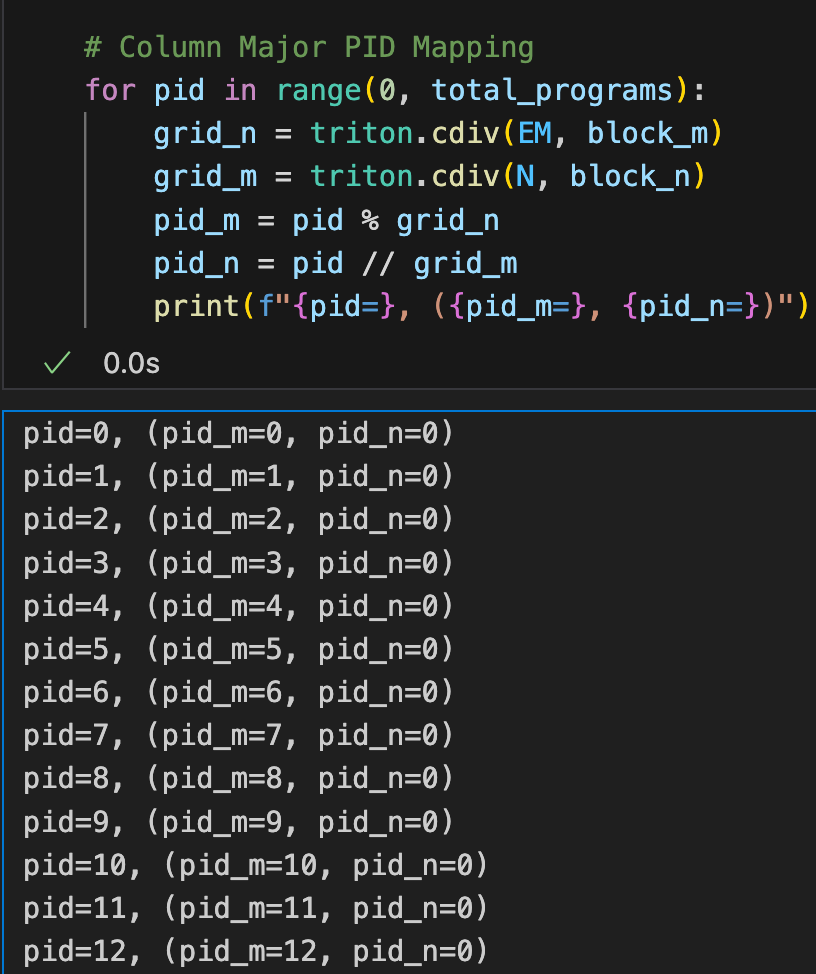
图4. PyTorch 中的列主序
从上面可以看出,通过这种映射,我们安排 GEMM 按照以下顺序计算 C 的输出块:C(0, 0), C(1, 0), C(2, 0),... 等。为了理解其含义,我们提供以下图示。
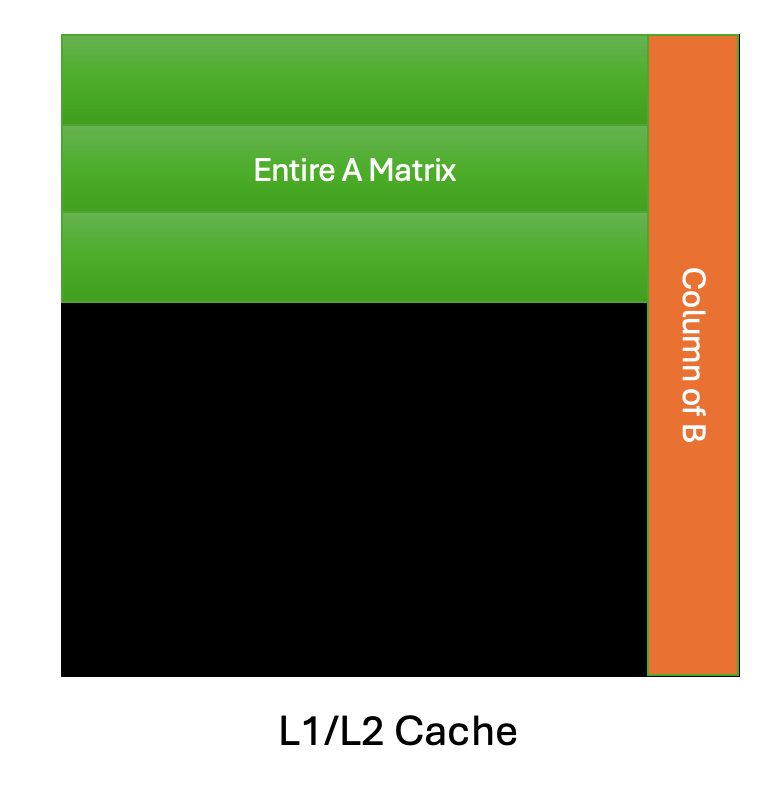
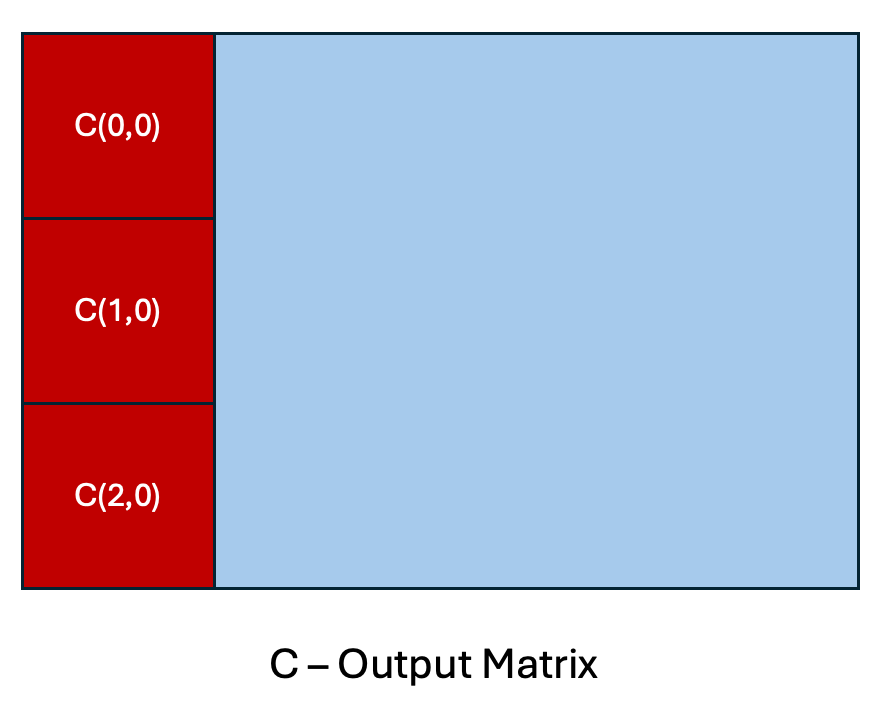
图5. 列主序 GEMM 调度的缓存重用模式
在上述列主序调度的简化视图中,假设对于具有瘦激活矩阵 A 的 GEMM,整个矩阵可以放入 GPU 缓存中,这对于 MoE 推理中遇到的问题大小来说是一个合理的假设。这使得权重矩阵 B 的列能够得到最大程度的*重用*,因为 B 列可以用于相应的输出瓦片计算,即 C(0,0)、C(1,0) 和 C(2,0)。相比之下,考虑行主序调度,C(0,0)、C(0,1)、C(0,2) 等。我们将不得不驱逐 B 的列,并向 DRAM 发出多个加载指令来计算相同数量的输出块。
优化核时的一个重要设计考虑是内存访问模式,它能导致最少的全局加载指令。这种最优的内存访问模式是通过列主序调度实现的。以下结果展示了我们研究的三种调度的性能。
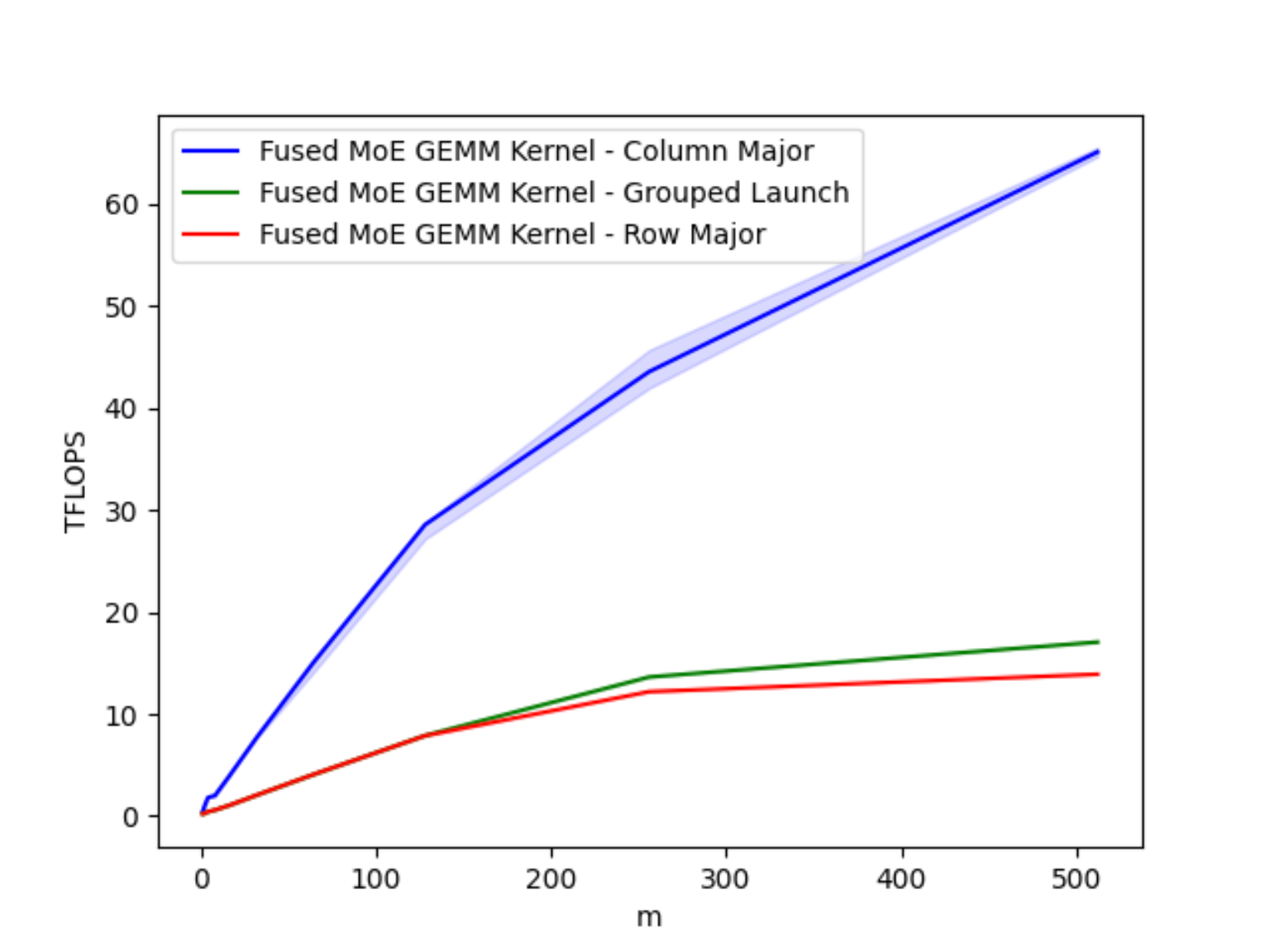
图6. 针对不同批量大小 M 的 A100 GEMM 调度比较
列主序调度比其他模式提供了高达 4 倍的速度提升,正如我们将在下一节中展示的,它通过极大地改进数据局部性提供了最优的内存访问模式。
5.0 Nsight Compute 分析——吞吐量和内存访问模式
对于性能分析,我们重点关注 H100 上 **M = 2** 的情况。A100 也可以进行类似的研究,因为许多相同的观察结果都适用。我们注意到以下突出结果,它们展示了我们优化的影响。
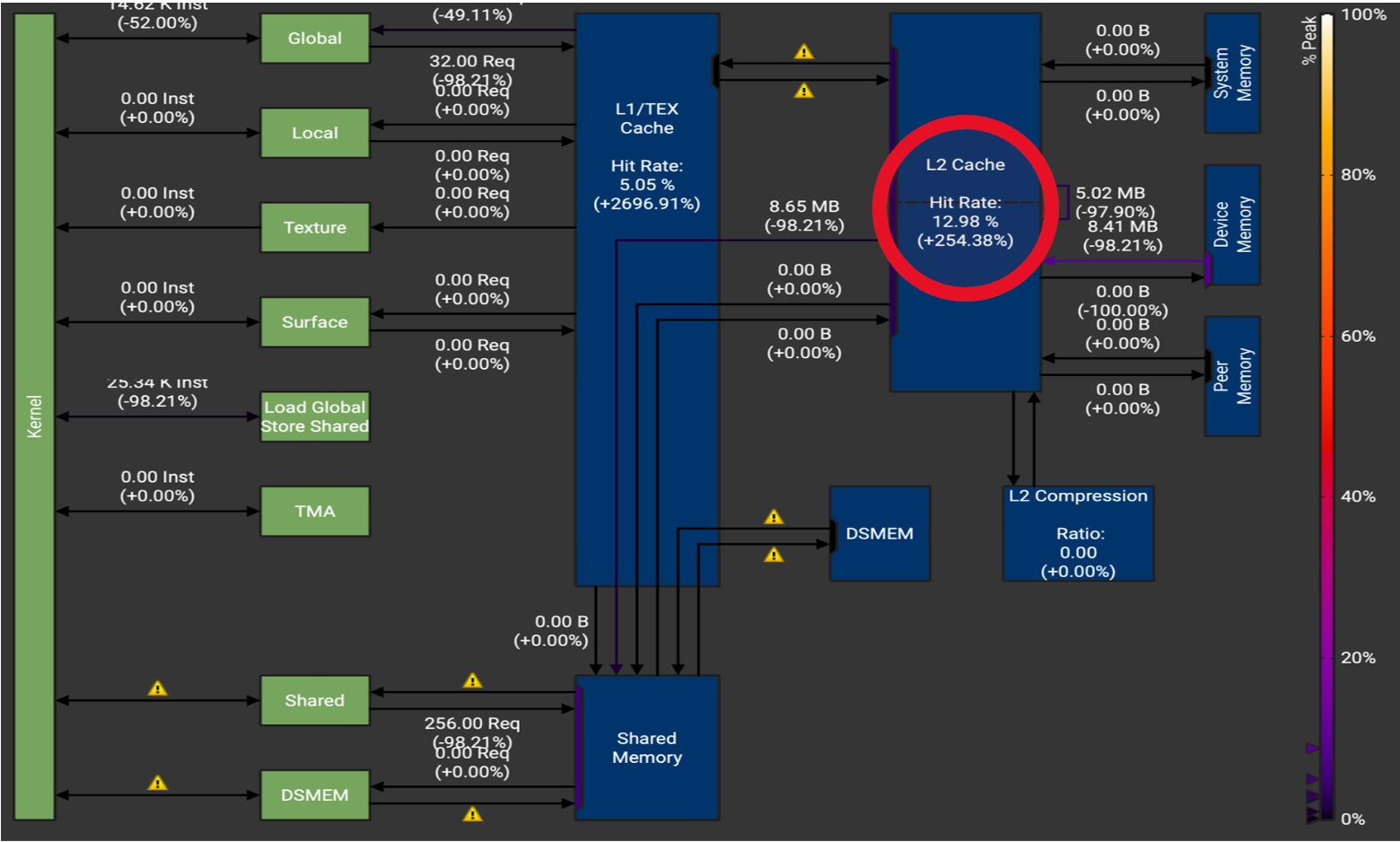
图7. H100 M = 2 的内存吞吐量图。请注意缓存命中率 L1 缓存命中率(+2696%)和 L2 缓存命中率(+254%)的大幅增加。
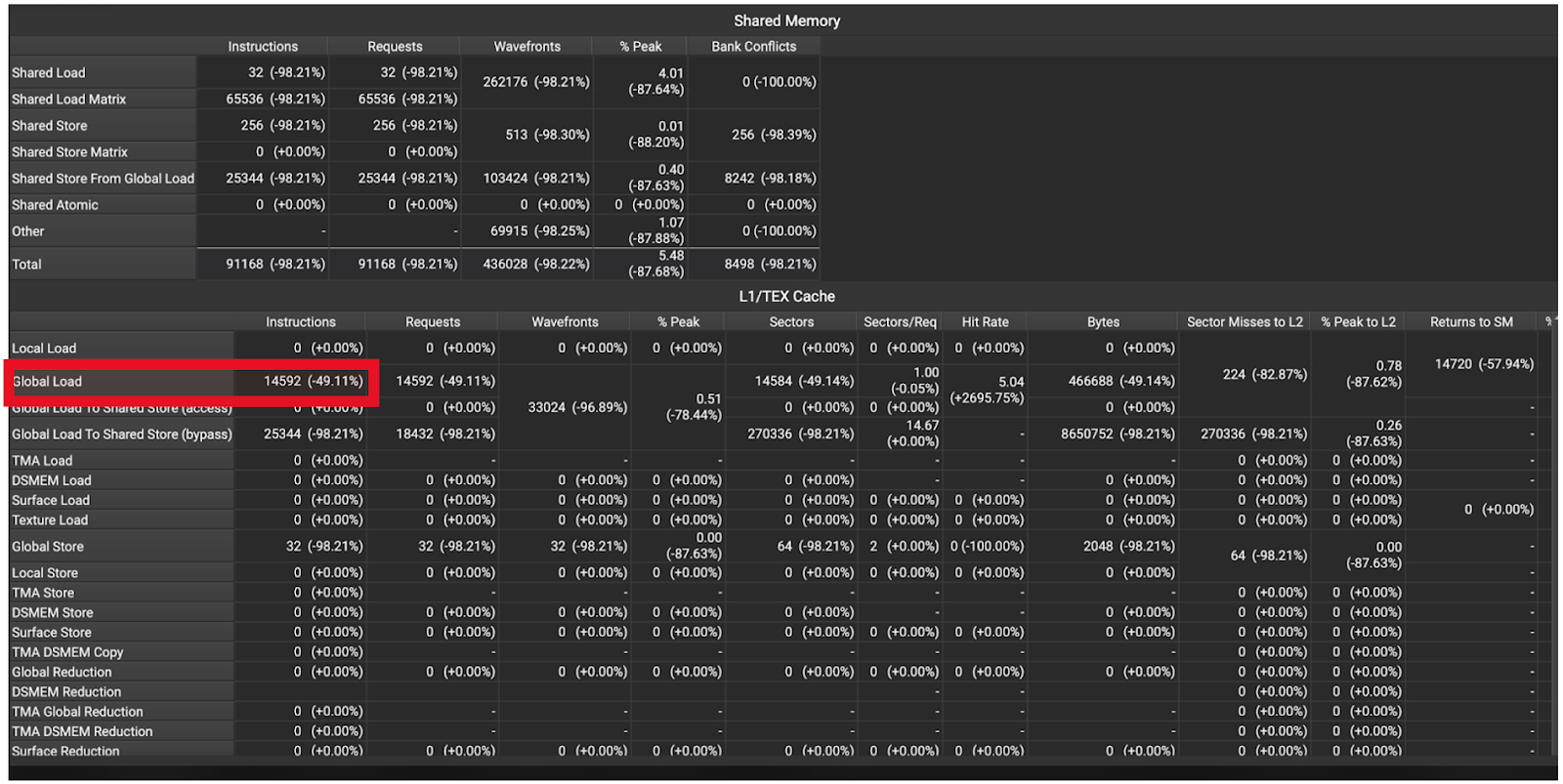
图8. H100 内存指令统计 M = 2。请注意全局内存加载减少了 49%。
这些统计数据表明我们的优化达到了预期效果,这体现在缓存未命中减少、内存访问减少以及由此产生的 2.7 倍加速。更具体地说,跟踪显示 L2 命中率增加了 2.54 倍(图 7),DRAM 访问减少了约 50%(图 8)。
这些改进最终带来了延迟的降低,对于 bs=2,优化后的核速度提高了 2.7 倍,对于 bs=512,则提高了 4.4 倍。
6.0 未来工作
我们的核在 FP16 中进行了测试,这展示了 MoE 列主序调度的数值和性能,但大多数生产模型都使用 BFloat16。我们在 Triton 中遇到了一个限制,即 tl.atomic_add 不支持 Bfloat16,并且遇到了启动延迟问题,这需要 CUDA 图支持才能用于列主序生产。在初步测试中,这带来了 70% 的端到端加速,但我们在端到端环境中遇到了一些专家映射不一致的问题,这些问题在测试环境中没有反映出来,因此需要进一步的工作才能完全实现这些加速。\
对于未来的工作,我们打算将其转移到 CUDA 核中,这将确保完全的 BFloat16 支持并降低相对于 Triton 的启动延迟,并可能解决专家路由不一致的问题。我们之前还发表过关于使用 Triton GEMM 核实现 GPTQ W4A16 的工作,因此自然的后续工作将包括将解量化融合到这个核中,以实现 GPTQ 量化推理路径。
7.0 可复现性
我们已经开源了 Triton 核代码以及易于运行的性能基准测试,供有兴趣在自己的 GPU 上比较或验证性能的读者使用。
致谢
我们要感谢 Daniel Han、Raghu Ganti、Mudhakar Srivatsa、Bert Maher、Gregory Chanan、Eli Uriegas 和 Geeta Chauhan 对所呈材料的审阅,以及 vLLM 团队的 Woosuk,因为我们是基于他的融合 MoE 核的实现进行开发的。