1.0 概述
我们提出了一个优化的 Triton FP8 GEMM(通用矩阵乘法)内核 TK-GEMM,它利用了 SplitK 并行化。对于小批量推理,在 NVIDIA H100 GPU 上,针对 Llama3-70B 推理问题规模,TK-GEMM 比 Triton 基础矩阵乘法实现加速高达 1.94 倍,比 cuBLAS FP8 加速 1.87 倍,比 cuBLAS FP16 加速 1.71 倍。
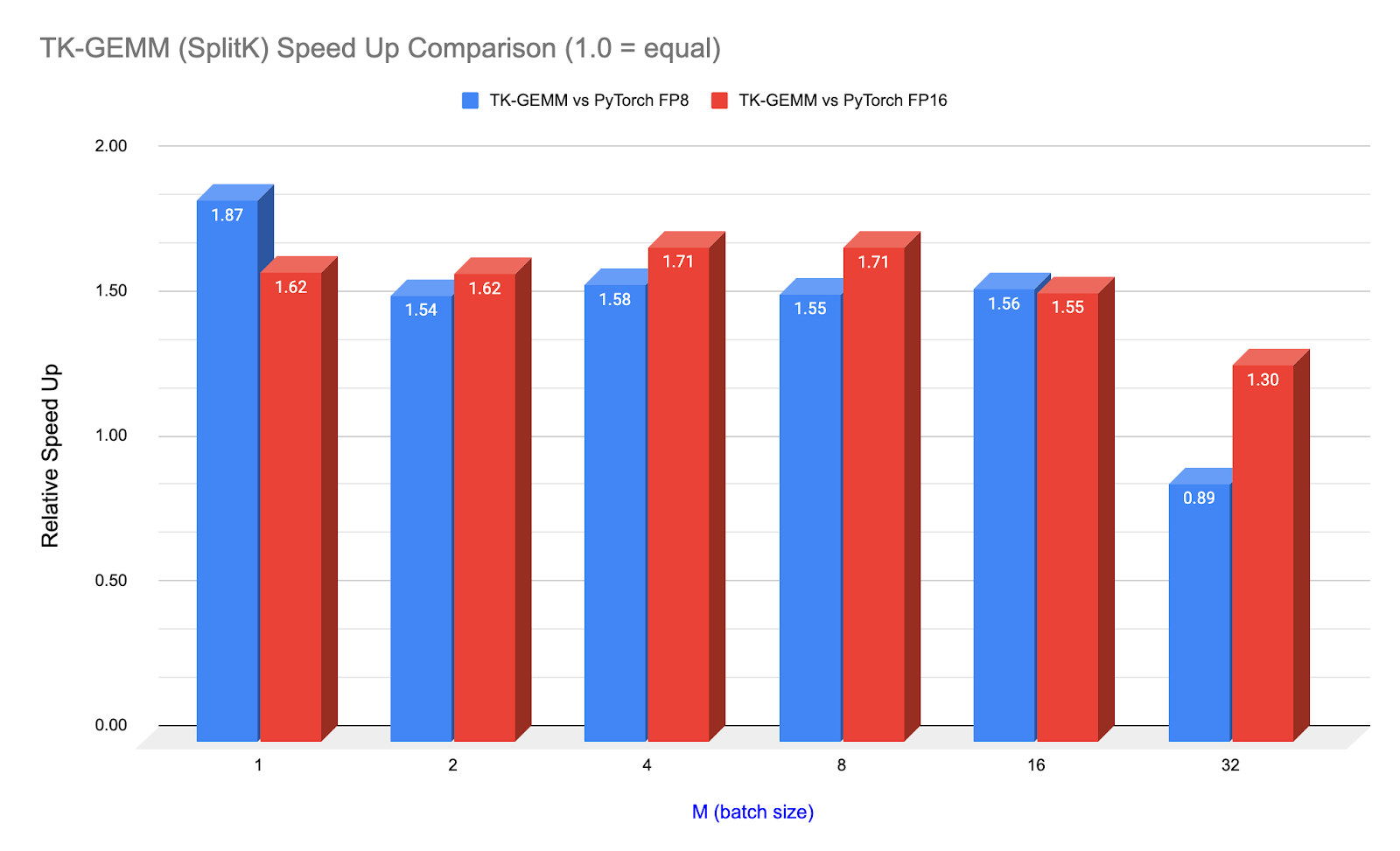
图 1. TK-GEMM 相对于 PyTorch(调用 cuBLAS)在 Llama3-70B 注意力层矩阵形状(N=K=8192)上的加速
在本博客中,我们将介绍如何使用 Triton 设计优化的 FP8 推理内核,并针对 Lama3-70B 推理进行调优。我们将介绍 FP8(8 位浮点),一种 Hopper 代 GPU (SM90) 支持的新数据类型,Triton 支持的关键 SM90 功能,以及我们如何修改并行化以最大化内存密集型(推理)问题规模的内存吞吐量。
我们还将专门介绍 CUDA 图,这项重要技术将有助于实现内核级别的加速,并使希望在生产环境中使用 Triton 内核的开发者获得额外的性能提升。
仓库和代码可在以下链接获取:https://github.com/pytorch-labs/applied-ai
2.0 FP8 数据类型
FP8 数据类型由 Nvidia、Arm 和 Intel 联合 引入,作为 16 位浮点类型的后继。由于比特数减半,它有可能为 Transformer 网络提供比其前身显著的吞吐量改进。FP8 数据类型包含 2 种格式:
E4M3(4 位指数和 3 位尾数)。能够存储 +/- 448 和 nan。
E5M2(5 位指数和 2 位尾数)。能够存储 +/- 57,334、nan 和 inf。
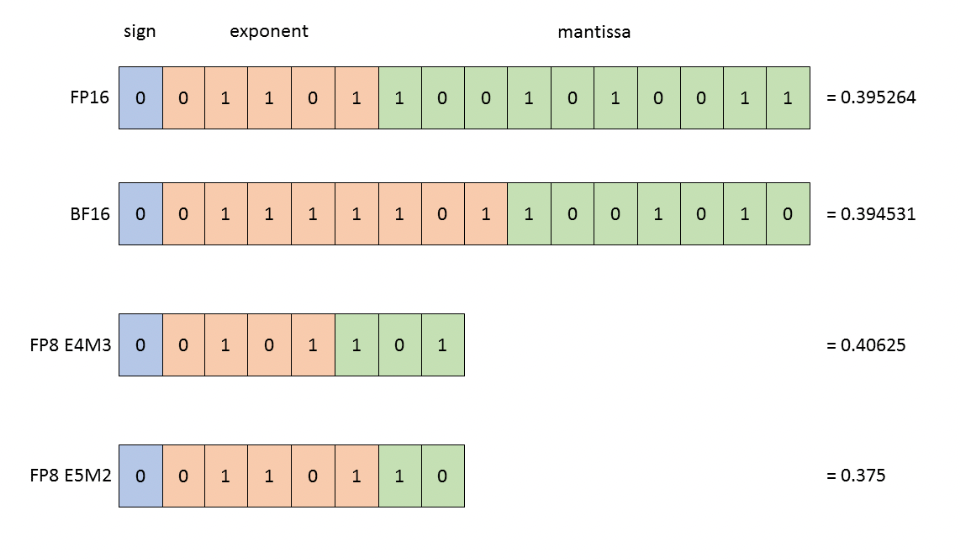
上图: BF16、FP16、FP8 E4M3 和 FP8 E5M2。
为了显示精度差异,图中显示了每种格式中最接近 0.3952 的表示。
图片来源:Nvidia
在推理和前向训练中,我们使用 E4M3,因为它具有更高的精度;在训练反向传播中,我们使用 E5M2,因为它具有更高的动态范围。Nvidia 设计的 H100 FP8 Tensor Core 可提供 3958 TFLOPS 的峰值性能,是 FP16 Tensor Core FLOPS 的 2 倍。
我们在设计 Triton 内核时考虑了这些硬件创新,在本博客的其余部分,我们将讨论如何利用并验证 Triton 编译器确实利用了这些功能。
3.0 Triton Hopper 支持和 FP8 Tensor Core 指令
Hopper GPU 架构增加了以下 新功能,我们预计这些功能将加速 FP8 GEMM。
- TMA(张量内存加速器)硬件单元
- WGMMA(Warp Group 矩阵乘累加指令)
- 线程块簇
Triton 目前利用了其中一项功能,即 wgmma 指令,而 PyTorch(调用 cuBLAS)则利用了所有这三项功能,这使得这些加速更加令人印象深刻。为了充分利用 Hopper FP8 Tensor Core,wgmma 是必需的,尽管仍然支持旧的 mma.sync 指令。
mma 和 wgmma 指令之间的关键区别在于,wgmma 指令不再由一个 CUDA warp 负责一个输出分片,而是由整个 warp group(4 个 CUDA warp) 异步 地贡献一个输出分片。
为了实际查看此指令,并验证我们的 Triton 内核是否确实使用了此功能,我们使用 nsight compute 分析了 PTX 和 SASS 汇编。
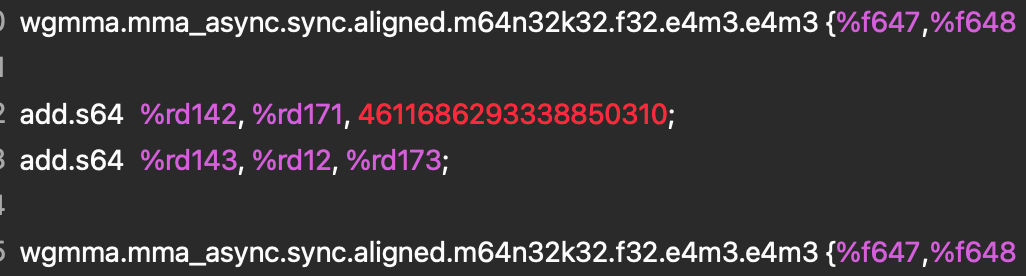
图 2. PTX 汇编
此指令在 SASS 中进一步降级为 QGMMA 指令。

图 3. SASS 汇编
这两个指令都告诉我们,我们正在将两个 FP8 E4M3 输入张量相乘并在 F32 中累加,这证实了 TK-GEMM 内核正在利用 FP8 Tensor Core,并且降级正在正确执行。
4.0 SplitK 工作分解
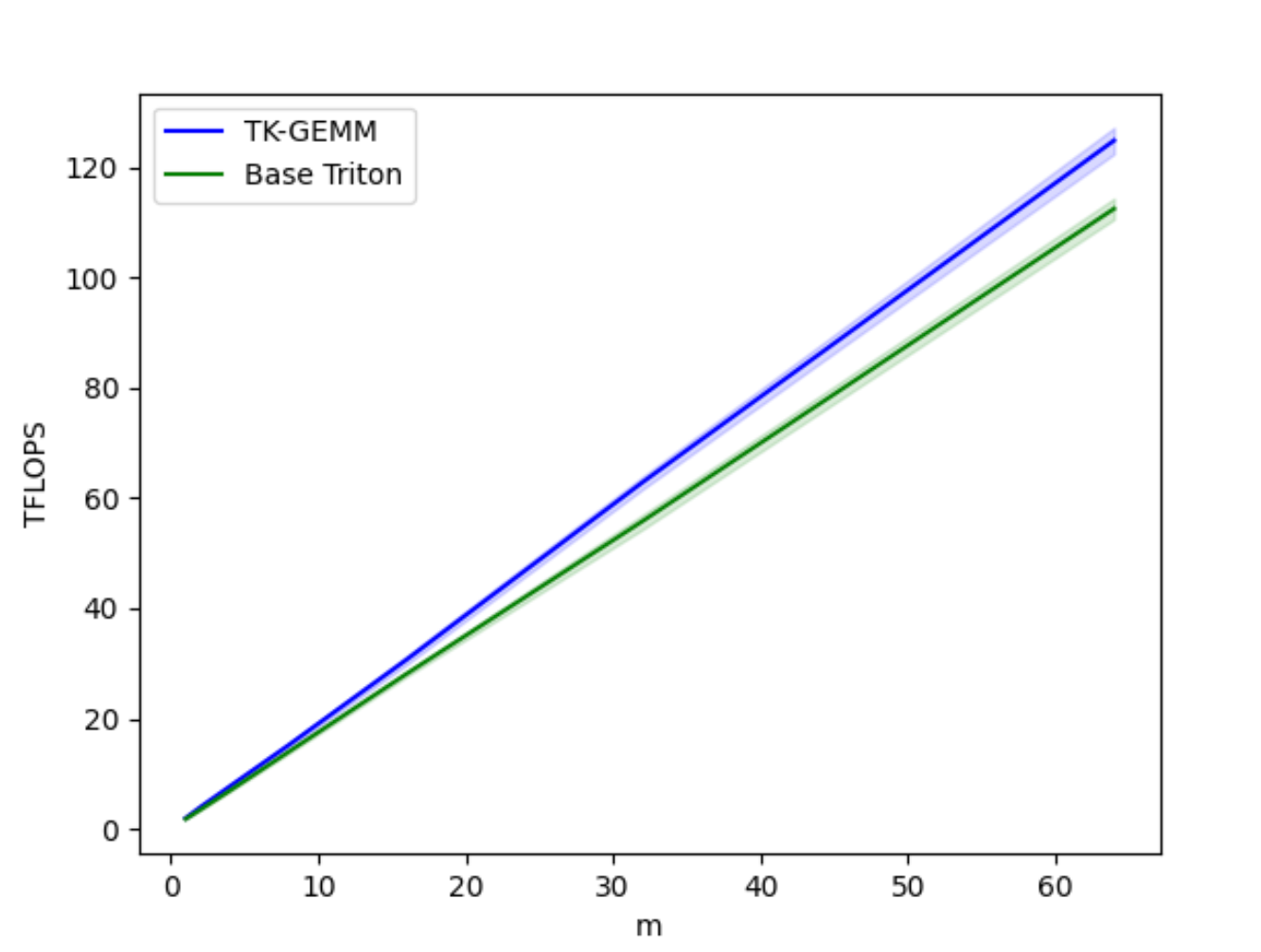
图 4. TK-GEMM 与基础 Triton GEMM 在 M = 1-64 时的 TFLOPS 对比
基础 Triton FP8 GEMM 实现对于小 M 范围的性能 不佳,其中矩阵乘法 A (MxN) x B (NxK) 中,M < N, K。为了优化此类矩阵配置文件,我们采用了 SplitK 工作分解,而不是基础 Triton 内核中的数据并行分解。这大大改善了小 M 范围的延迟。
背景知识:SplitK 沿 k 维度启动额外的线程块来计算部分输出和。然后使用原子归约将每个线程块的部分结果相加。这允许更细粒度的工作分解,从而提高性能。有关 SplitK 的更多详细信息,请参见我们的 arxiv 论文。
在仔细调整了我们内核的其他相关超参数,例如瓦片大小、warp 数量和 Llama3-70B 问题大小的流水线级数后,我们能够比 Triton 基础实现 实现高达 1.94 倍 的加速。有关超参数调优的更全面介绍,请参阅我们的 博客。
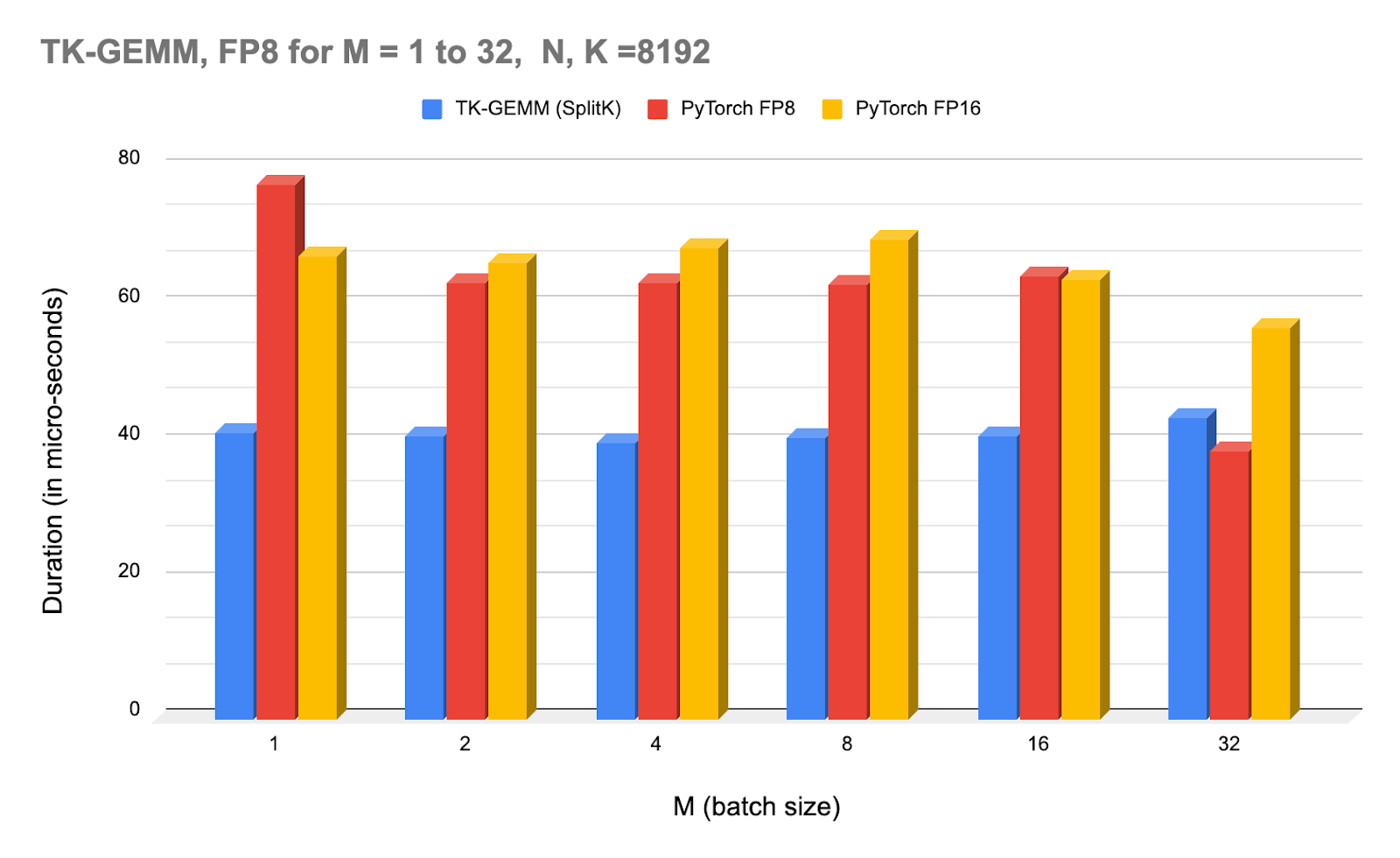
上图:NCU 分析器在不同批量大小下 TK-GEMM 的时间,并与 PyTorch(调用 cuBLAS)FP8 和 FP16 进行比较。
请注意,从 M=32 开始,cuBLAS FP8 内核开始优于 TK-GEMM。对于 M >= 32,我们怀疑我们找到的超参数不是最优的,因此需要进行另一组实验来确定中等大小 M 范围的最佳参数。
5.0 CUDA 图实现端到端加速
为了在端到端设置中实现这些加速,我们必须同时考虑内核执行时间(GPU 持续时间)和墙钟时间(CPU+GPU)持续时间。Triton 内核是手写的(而不是 torch compile 生成的),众所周知会受到高内核启动延迟的影响。如果我们使用 torch profiler 跟踪 TK-GEMM 内核,我们可以看到 CPU 侧的调用堆栈,从而精确地找出导致减速的原因。
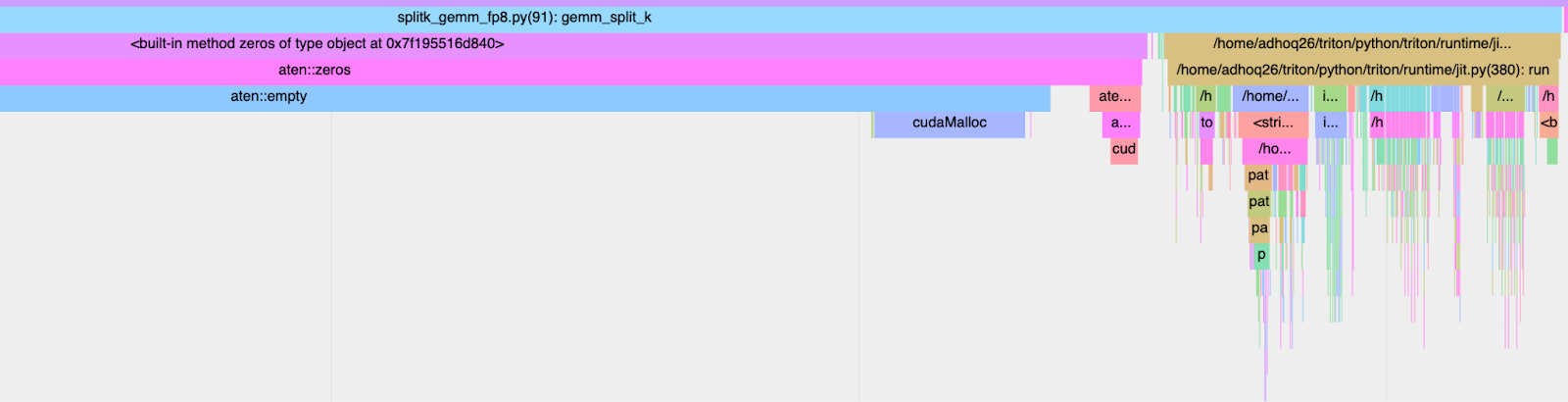
图 5. CPU 启动开销:2.413 毫秒
从上图可以看出,我们优化内核的大部分墙钟时间都由 JIT(即时)编译开销主导。为了解决这个问题,我们可以使用 CUDA 图。
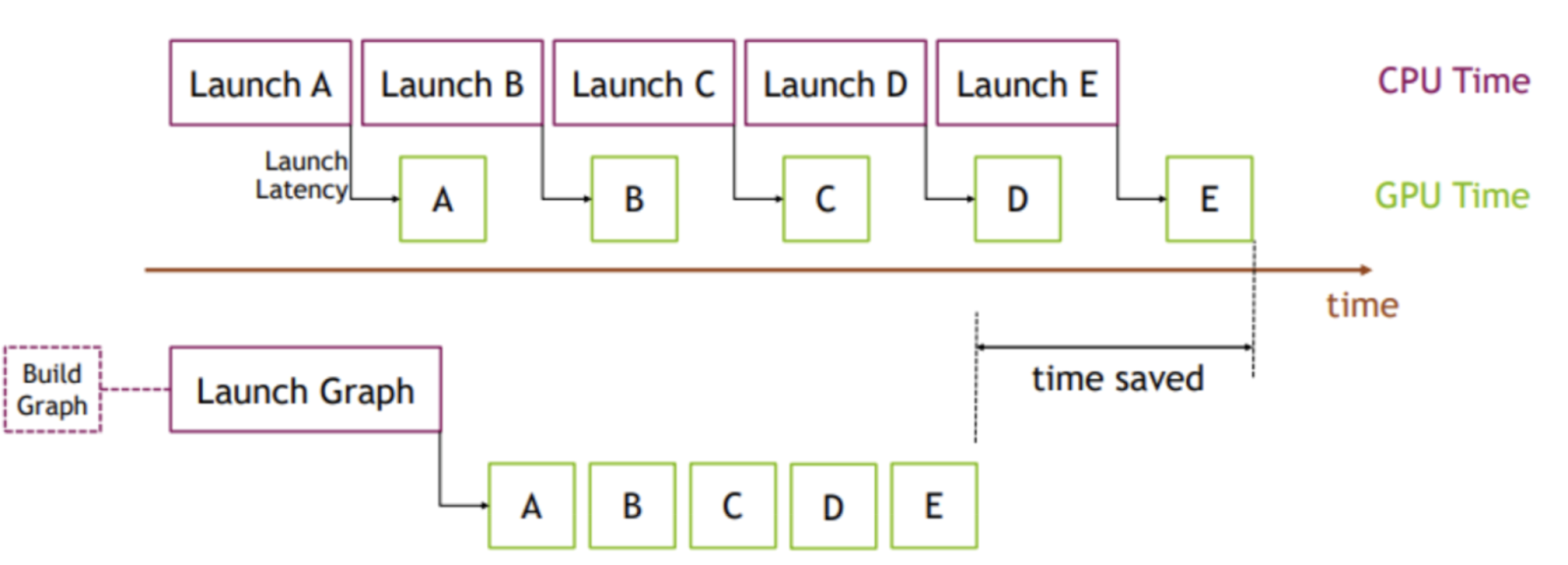
图 6. CUDA 图可视化
图片来源:PyTorch
其核心思想是,我们不是多次启动内核,而是可以创建一个并实例化一个图(一次性成本),然后提交该图实例进行执行。为了说明这一点,我们模拟了一个 Llama3-70B 注意力层,如以下使用 nsight systems 生成的图所示,由于 CPU 内核启动开销,每个 GEMM 之间的时间为 165us,而实际的矩阵乘法花费 12us。这意味着在注意力层中,GPU 有 92% 的时间处于空闲状态,没有做任何工作。
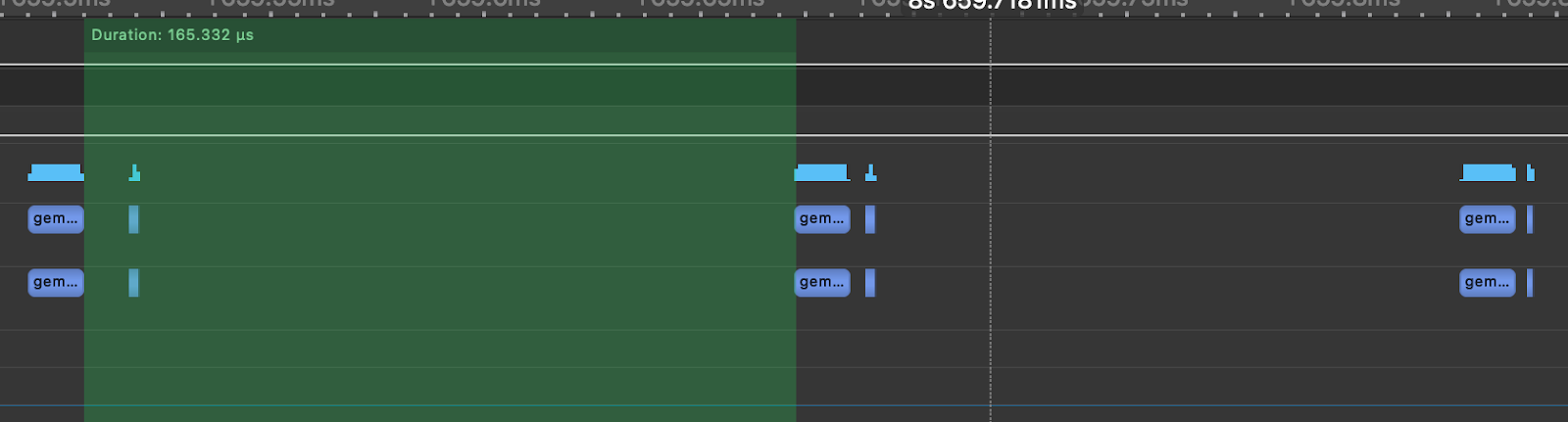
图 7. 模拟的 Llama3-70B 注意力层,带 TK-GEMM
为了展示 CUDA 图的影响,我们接着在玩具注意力层中创建了 TK-GEMM 内核的图并重放了该图。在下方,我们可以看到内核执行之间的间隔减少到 6.65us。
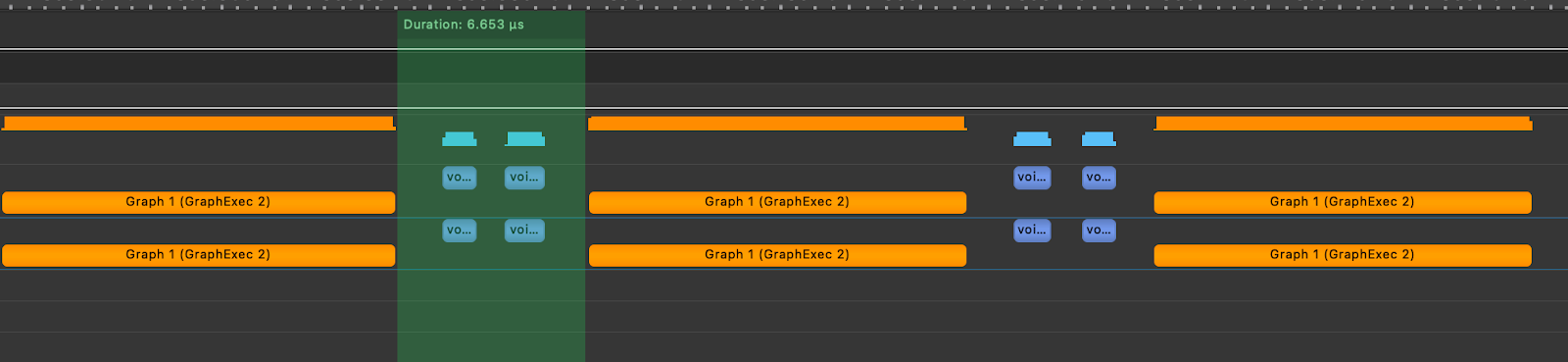
图 8. 模拟的 Llama3-70B 注意力层,带 TK-GEMM 和 CUDA 图
实际上,这种优化将使 Llama3-70B 中单个注意力层的速度提高 6.4 倍,而这比在没有 CUDA 图的模型中简单地使用 TK-GEMM 要快。
6.0 潜在的未来优化路径
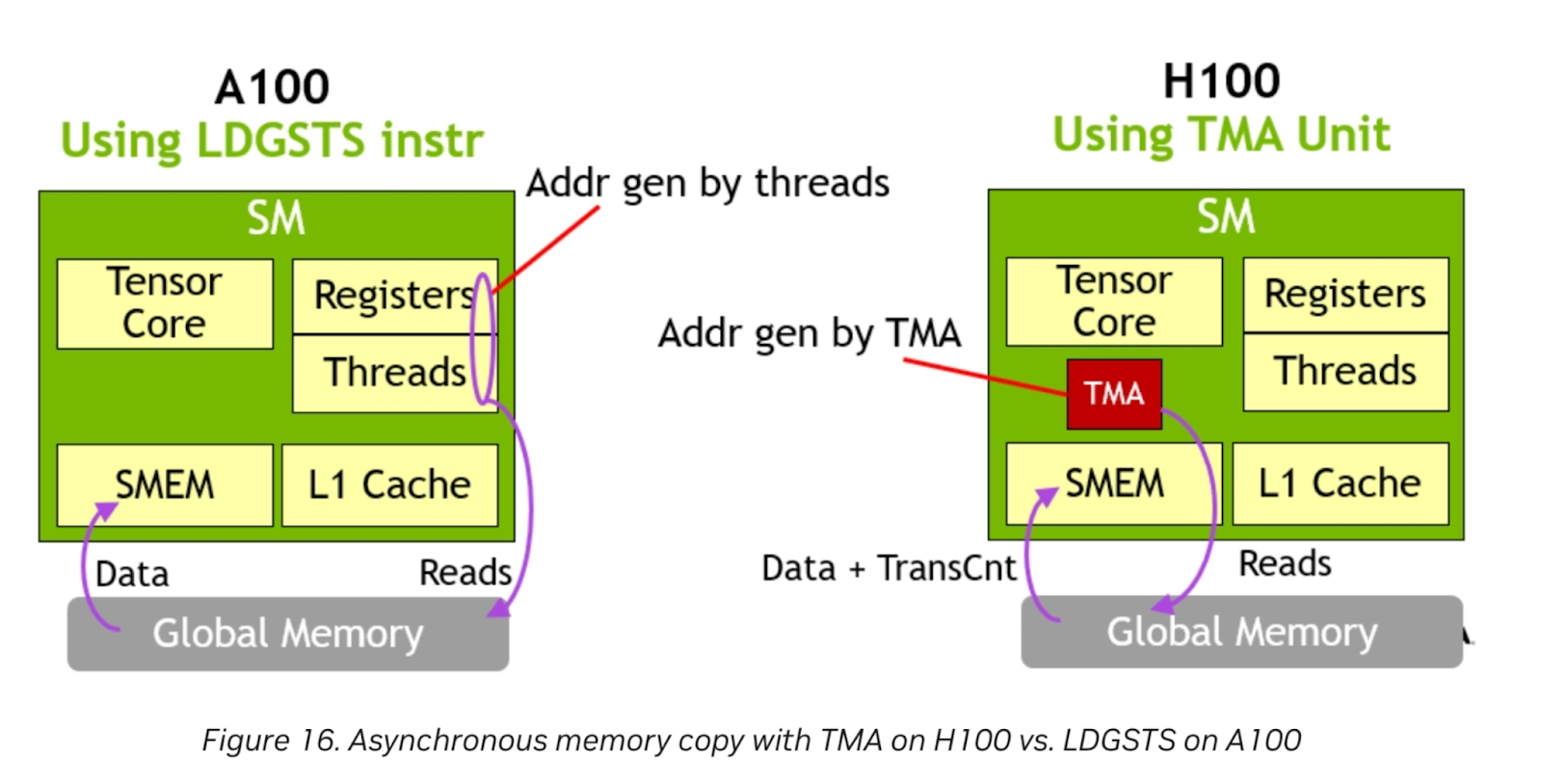
图 9. TMA 硬件单元
图片来源:Nvidia
Nvidia H100 具有 TMA 硬件单元。专用的 TMA 单元释放了寄存器和线程来执行其他工作,因为地址生成完全由 TMA 处理。对于内存密集型问题,当 Triton 支持此功能时,可以提供进一步的增益。
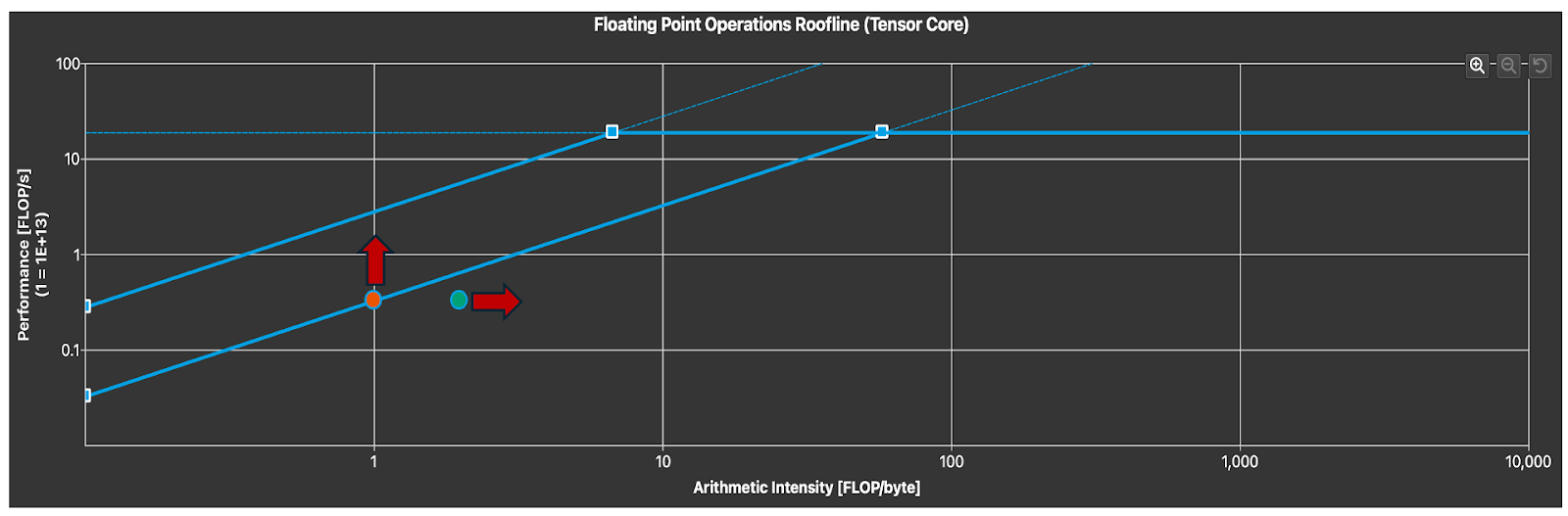
图 10. Tensor Core 利用率(箭头表示自由度)
为了确定 Tensor Core 的利用率,我们可以分析屋顶线图。请注意,正如预期的那样,对于小 M,我们处于内存受限区域。为了提高内核延迟,我们可以通过利用数据局部性和其他循环 优化 来增加算术强度(在固定问题大小下),或者增加内存吞吐量。这需要一种更优化的并行算法,专门针对 FP8 数据类型以及我们期望在 FP8 推理中看到的问题大小特征。
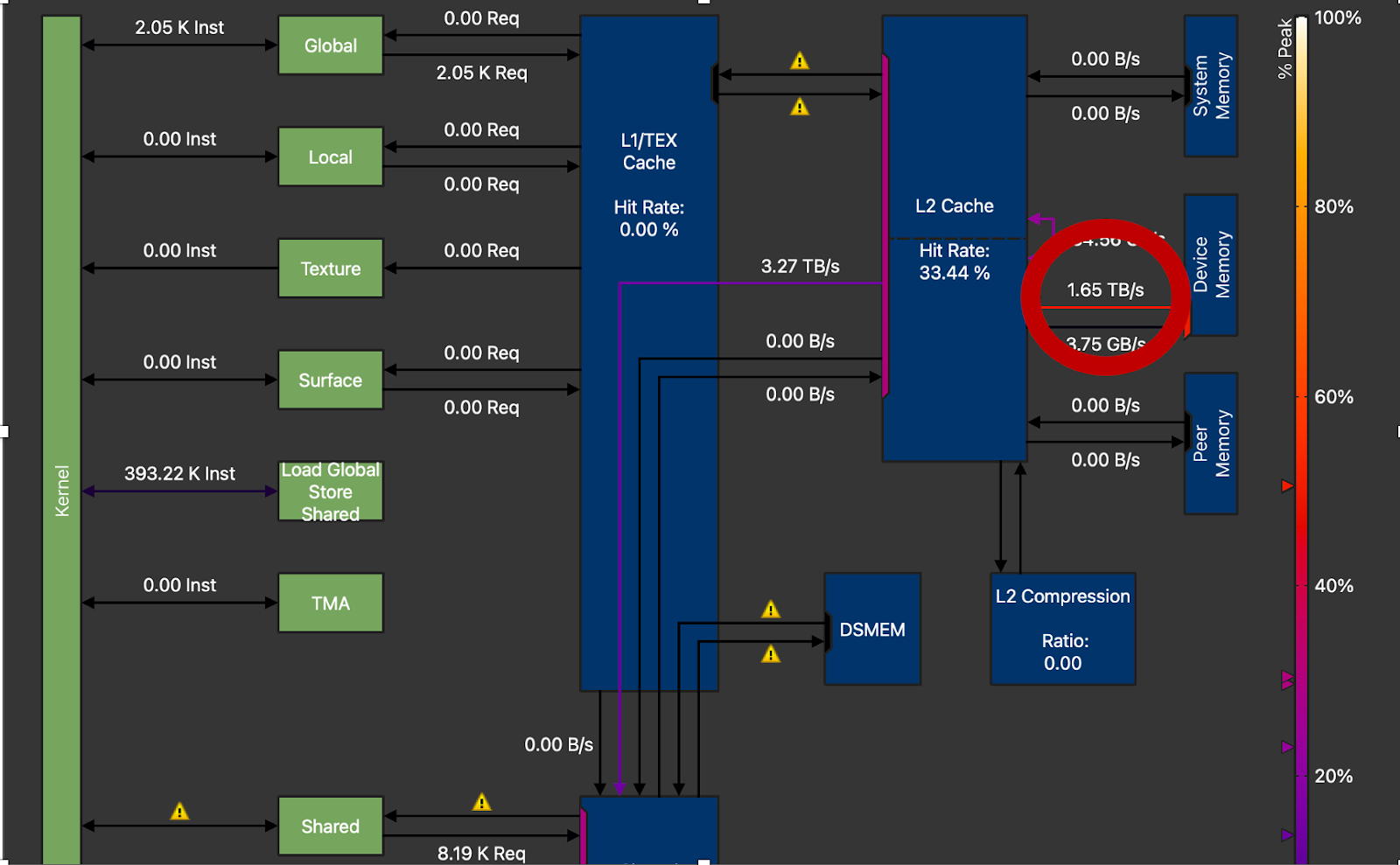
图 11. DRAM 吞吐量圈出,H100 上为 1.65TB/s,峰值为 3.35TB/s(M=16,N=8192,K=8192)
最后,我们可以看到我们只达到了 NVIDIA H100 峰值 DRAM 吞吐量的 50% 左右。高性能 GEMM 内核通常能达到峰值吞吐量的 70-80%。这意味着仍有很大的改进空间,并且需要上述技术(循环展开、优化并行化)以获得额外的增益。
7.0 未来工作
未来的研究中,我们希望探索 CUTLASS 3.x 和 CuTe,以更直接地控制 Hopper 功能,尤其是在获得直接 TMA 控制和探索乒乓架构方面,这已显示出对 FP8 GEMM 的良好结果。