Meta:Less Wright、Hamid Shojanazeri、Vasiliy Kuznetsov、Daniel Vega-Myhre、Gokul Nadathur、Will Constable、Tianyu Liu、Tristan Rice、Driss Guessous、Josh Fromm、Luca Wehrstedt、Jiecao Yu Crusoe:Ethan Petersen、Martin Cala、Chip Smith
通过与 Crusoe.AI 合作,我们获得了他们位于冰岛的新型 2K H200 集群的访问权限。这使我们能够利用 TorchTitan 的 HSDP2 和 TorchAO 新的 Float8 Rowwise,展示大规模训练加速 34-43%,同时保持与 BF16 可比的收敛性和稳定性。
 在这篇文章中,我们将详细介绍 H200 与 PyTorch 新的 Float8 Rowwise 训练在 TorchTitan 的 FSDP2/HSDP2 和大规模 CP 下的协同作用。
在这篇文章中,我们将详细介绍 H200 与 PyTorch 新的 Float8 Rowwise 训练在 TorchTitan 的 FSDP2/HSDP2 和大规模 CP 下的协同作用。
背景 – 什么是 H200?
H200 是 H100 的“增强版”,提供与 H100 完全相同的计算能力,但有两项额外改进。
- 更大的全局内存,141GiB HBM3e,而标准为 80GiB HBM3。
- 内存带宽快约 43%,达到 4.8TB/s,而标准为 3.35 TB/s。更快的内存传输对训练速度有显著影响,尤其是对于 PyTorch 的 AsyncTP。
什么是 PyTorch Float8 Rowwise?
Float8 Rowwise 是 Float8 相对于之前“tensor wise”Float8 的更精细分辨率。它旨在确保更精细的精度,以支持更大的工作负载,这些工作负载在规模扩大和训练进展过程中往往对量化变得更敏感。
Float8 Rowwise 有两个关键改进。
- 现在每行都保持自己的缩放因子,而不是整个张量使用单个缩放因子,从而提高了量化精度。每行更精细的缩放有助于减少异常值(极端值会迫使量化缩放因子拉伸并降低正态分布值的精度)的影响,从而确保更好的精度。
- 缩放因子本身现在通过向下舍入到最接近的 2 的幂来实现。这已被证明有助于在乘以/除以缩放因子时减少量化误差,并确保大值在正向和反向传播中都缩放到相同的值。
请注意,其他大规模模型已使用 Float8 以 2K 规模进行训练,结合了 1×128 groupwise 和 128×128 blockwise,并使用了 2 的幂次缩放因子。它们的目标相同,即提高 Float8 的精度以支持大规模训练。
因此,Float8 Rowwise 提供了类似的承诺,可以在超大规模训练中使用 Float8,但我们希望提供大规模稳定性和收敛性的证据,Crusoe H200 2K 集群上的训练为此提供了初步验证。
展示 Float8 Rowwise 损失收敛与 BF16 在 1600 和 1920 GPU 规模下的比较
为了验证可比的损失收敛性,我们使用 TorchTitan 和 Llama3 70B,在 1920 和 1600 (1.6k) GPU 规模下分别运行了两次。1.6K GPU 运行设置为 2.5k 迭代,使用 TorchTitans 的 HSDP2 和 Context Parallel 来实现 2D 并行性。
损失收敛测试使用 Titan 的确定性模式运行——这种模式有效地冻结了每次运行之间大多数潜在的变异源,从而有助于确保唯一实质性的变化是我们想要测试的,即 BF16 与 Float8 Rowwise 的损失收敛和损失曲线。
请注意,确定性模式也会降低训练速度,因为各种内核不会自动调优以最大化吞吐量(否则我们可能会在不同运行之间使用不同的内核并引入方差)。
完成了两次运行,一次使用 BF16,另一次使用 Float8 Rowwise。
两次运行都完成了分配的 2.5k 迭代,没有出现问题,展示了 Crusoe 集群的稳定性,FP8 在 24 小时内完成,BF16 在 31 小时 19 分钟后完成。
| 数据类型 | 时间/迭代 | 损失 |
| BF16 | 24 小时 | 3.15453 |
| Float8 行式 | 24 小时 | 2.86386 |
| BF16 | 31 小时 19 分钟 / 2.5K | 2.88109 |
| Float8 行式 | 24 小时 / 2.5K | 2.86386 |
在 24 小时标记处,Float8 完成了 2.5K 迭代,展示了 Float8 训练的相对加速(即使在确定性模式下)。在 24 小时标记处,对于相同 24 小时的大规模训练时间,Float8 相对于 BF16 在损失方面实现了 +9.21% 的相对改进。
31 小时 19 分钟后,BF16 运行最终完成了 2.5k 迭代。
最终损失数据
BF16 = 2.88109 Float8 = 2.86386
从损失曲线来看,我们观察到在前三分之一和后三分之一部分曲线非常相似,中间部分则出现了一个动荡区域,两者都显示出类似的峰值,但峰值的相对时间略有偏差。
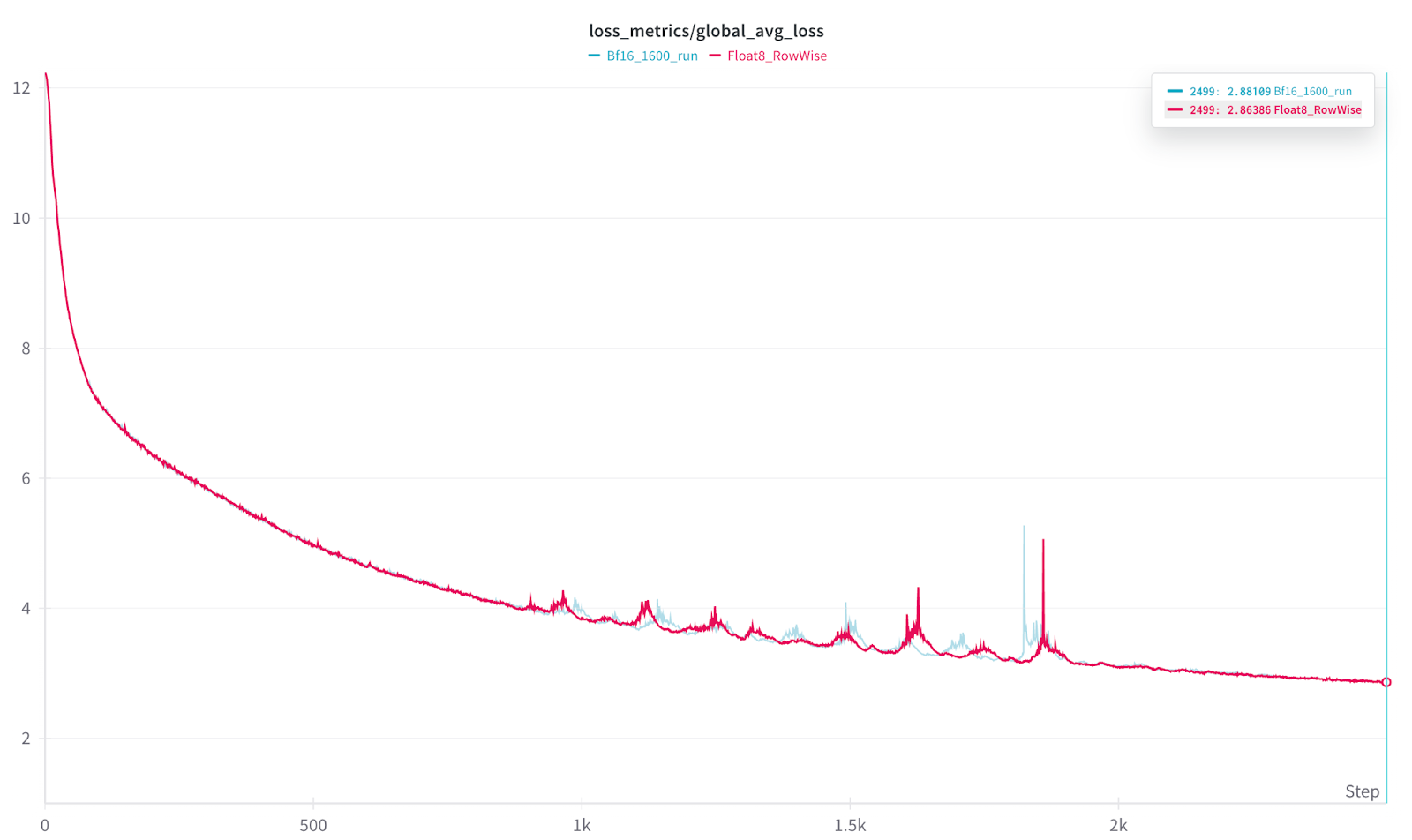 因此,我们可以看到 PyTorch 的 Float8 Rowwise 提供了相似的收敛性,但在相同的训练时间内,速度提高了 33% 以上。
因此,我们可以看到 PyTorch 的 Float8 Rowwise 提供了相似的收敛性,但在相同的训练时间内,速度提高了 33% 以上。
Float8 行式长期训练稳定性
除了展示可比的收敛性之外,我们还希望展示 Float8 的长期训练稳定性,因此我们启动了一个 4 天、15K 次运行,规模为 256。
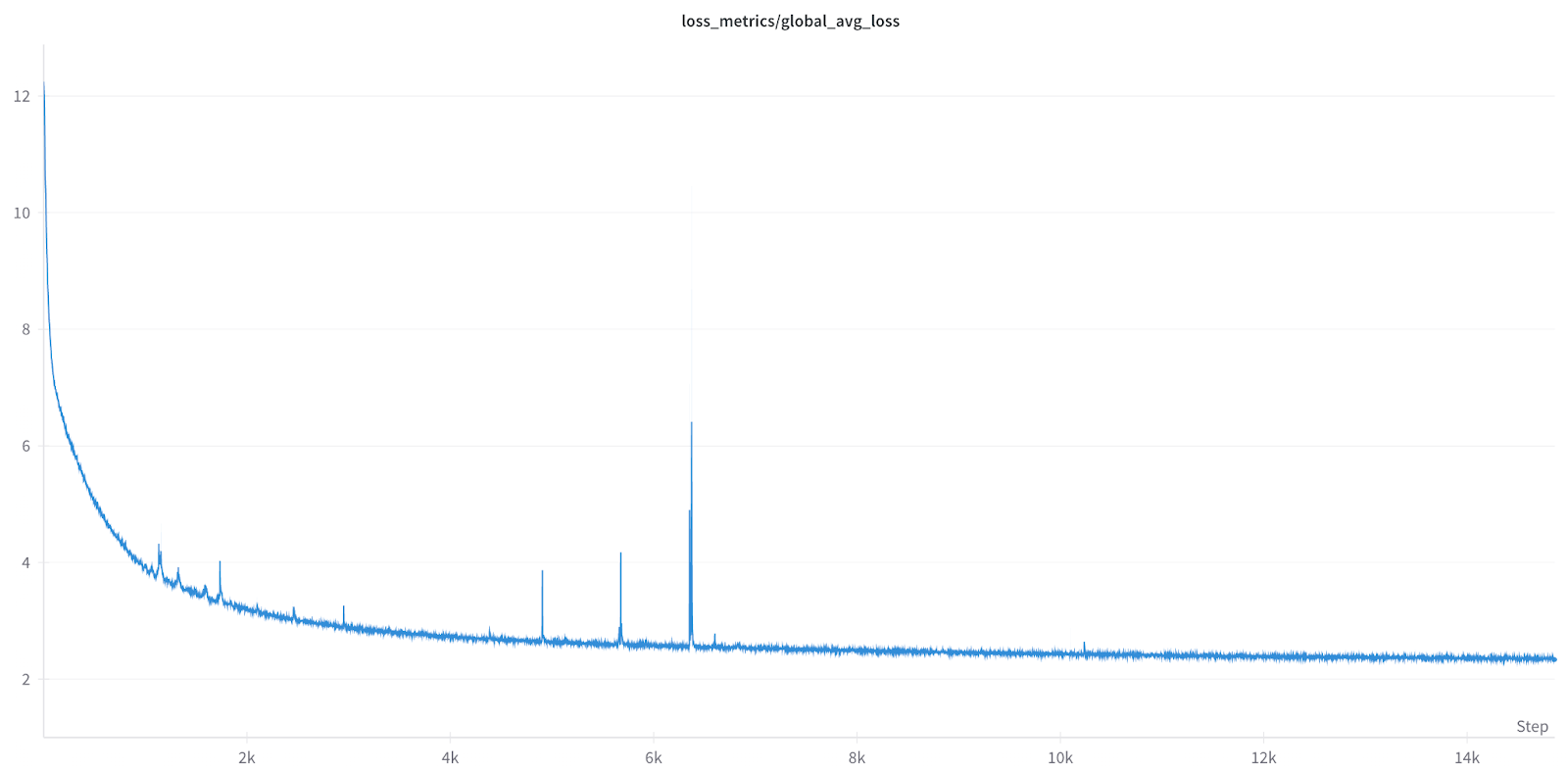 如上所示,Float8 训练运行了超过 100 小时,没有出现任何问题,突显了 Float8 Rowwise 的长期稳定性。
如上所示,Float8 训练运行了超过 100 小时,没有出现任何问题,突显了 Float8 Rowwise 的长期稳定性。
TorchTitan 中的确定性
为了验证确定性并查看较长时间运行中的尖峰是否来自规模,我们还进行了一次较小的运行,包括两次 BF16 运行和一次 Float8 运行,规模为 256,并且仅使用 HSDP2(即不使用 2D Context Parallel)。
在这种情况下,两次 BF16 运行都具有相同的曲线和最终损失,并且我们观察到所有三次运行都出现了类似的尖峰区域。
在 2K 迭代标记处,Float8 和 BF16 都结束在几乎相同的位置
BF16 *2 = 3.28538
Float8 行式 = 3.28203
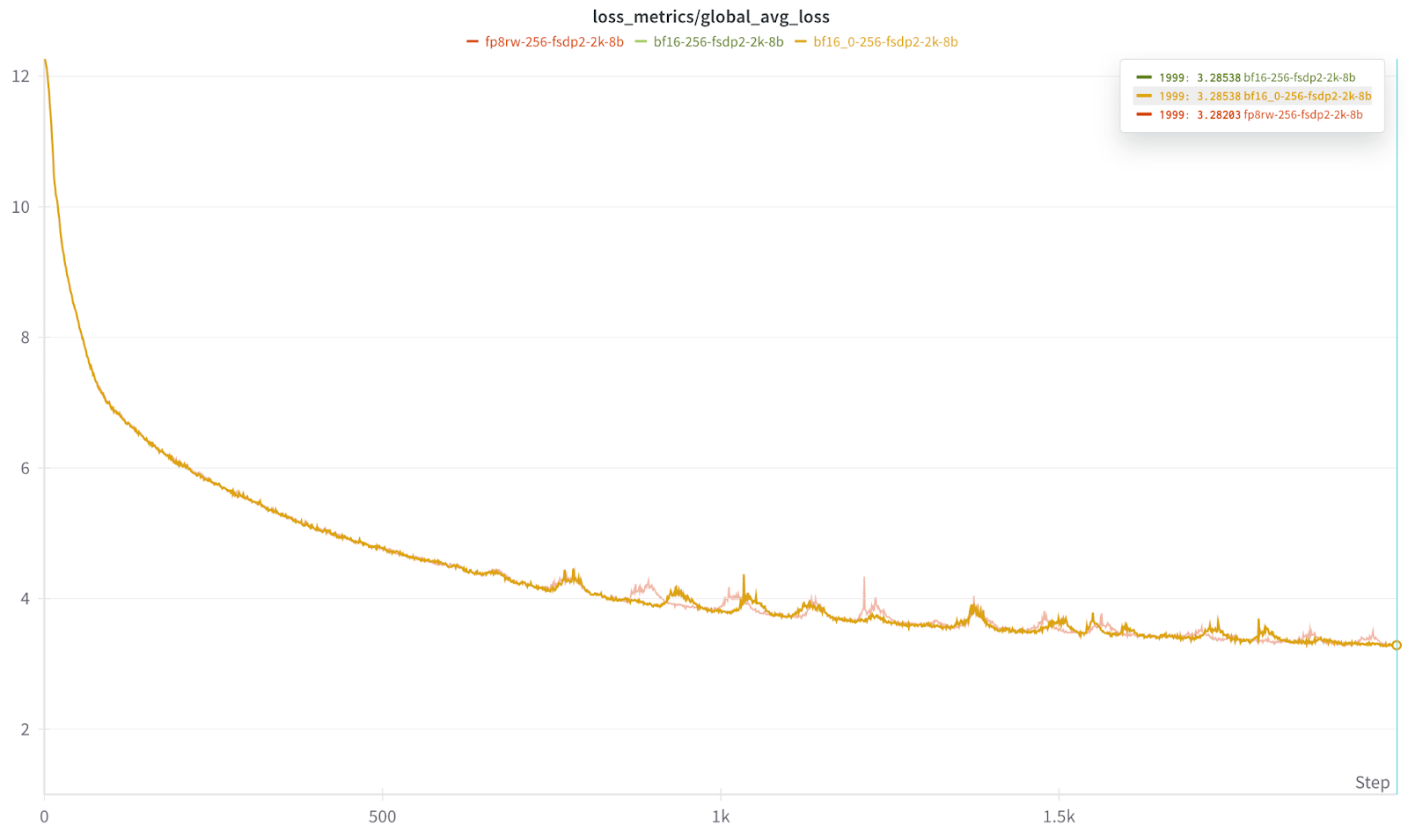 上述结果证实,损失中的尖峰既不是 CP 也不是规模(2k)造成的,因为我们在 256 规模下也看到了类似的效果。损失尖峰最可能的原因可能是数据集中内容的分布。
上述结果证实,损失中的尖峰既不是 CP 也不是规模(2k)造成的,因为我们在 256 规模下也看到了类似的效果。损失尖峰最可能的原因可能是数据集中内容的分布。
为了确定性,实验使用序列化的 C4 数据集(未打乱)运行,这意味着尖峰可能来自数据集中遇到的新内容。
Float8 Rowwise 在各种规模下的实际加速
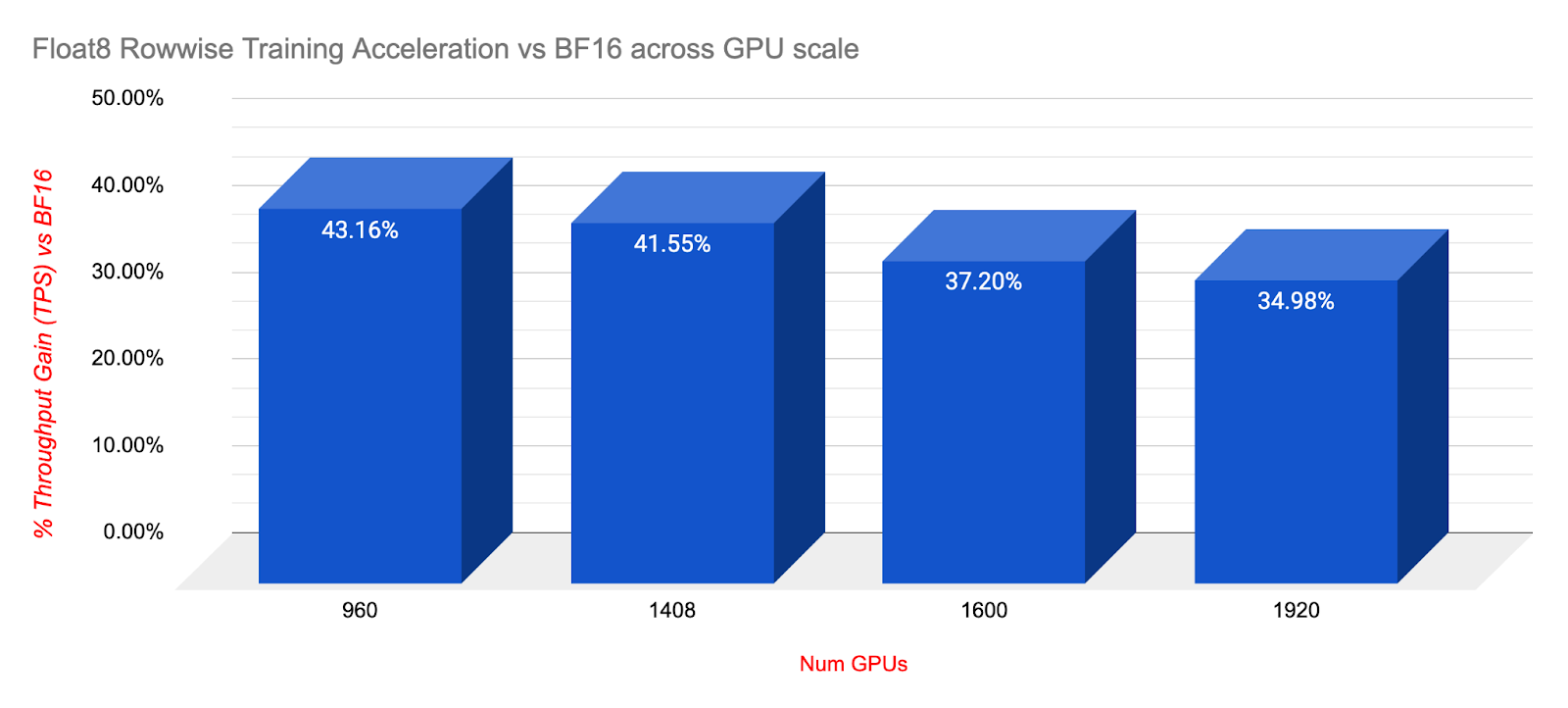
我们在不同的 GPU 规模下进行了较短的运行,以了解 Float8 Rowwise 在集群规模扩大时训练加速方面的表现。从 960 扩展到 1920,Float8 持续提供令人印象深刻的训练加速,与 BF16 相比,性能提升幅度在 34-43% 之间。我们还想指出,从 1k 扩展到 2k GPU 时,通信开销可能开始显现,我们观察到 BF16 的吞吐量下降了 4%。
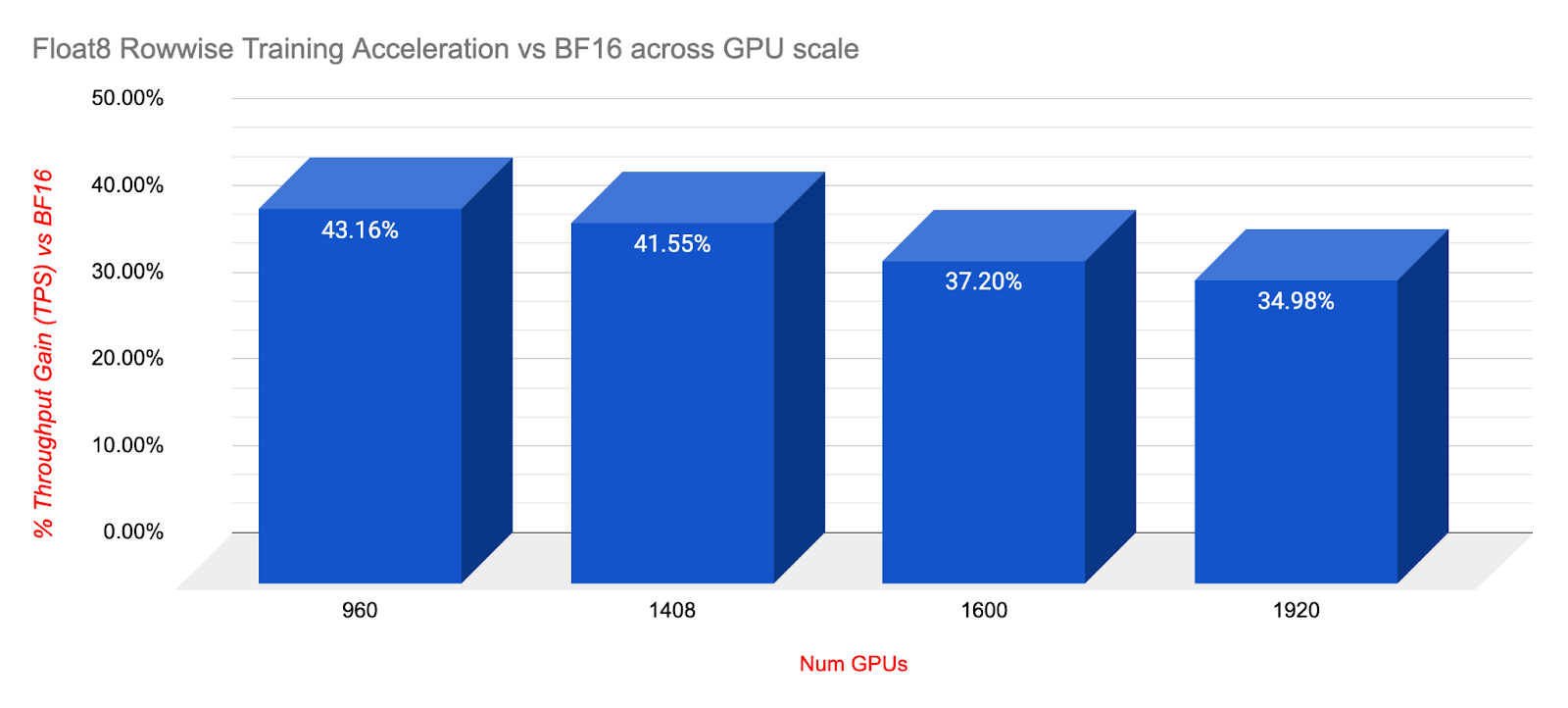 如上所述,在大规模更长的训练运行中,Float8 Rowwise 提供了显著的加速,并实现了相同甚至略有改进的损失终点,同时在 1920 (DeepSeek) 规模下实现了 34% 的加速。
如上所述,在大规模更长的训练运行中,Float8 Rowwise 提供了显著的加速,并实现了相同甚至略有改进的损失终点,同时在 1920 (DeepSeek) 规模下实现了 34% 的加速。
如何在训练中使用 Float8 Rowwise?
Float8 Rowwise 现已推出,可用于您的大规模训练。它打包在 TorchAO 的最新构建(0.9 及更高版本)中,如果您想快速启动并运行,它已原生集成到 TorchTitan 中。
在 TorchTitan 中激活 Float8 Rowwise
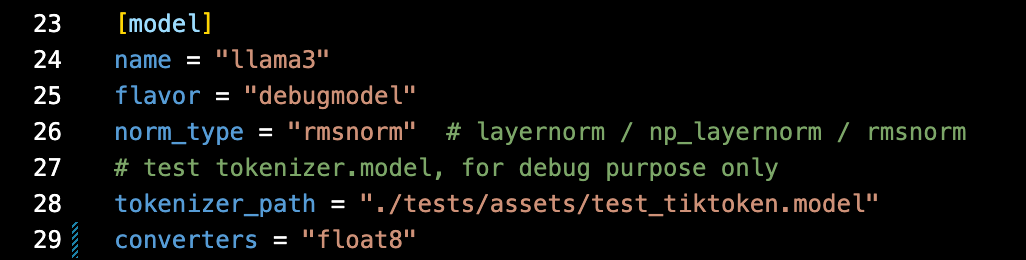
首先在模型的 .toml 文件中启用模型转换器,将 nn.linears 热插拔为 float8 线性层 – 参见第 29 行
其次,指定“rowwise”float8 配方 – 参见第 72 行
 请注意,“recipe_name”有三种选择。
请注意,“recipe_name”有三种选择。
- rowwise,这是推荐的默认值,
- tensorwise(旧版 float8)和
- rowwise_with_gw_hp。
gw_hp 行式选项在反向传播过程中将权重的梯度保持在 BF16 精度,这可以进一步提高 Float8 对极其敏感的工作负载的精度。但是,如果模型中大多数矩阵乘法的大小较小(在 H100 上估计临界点约为 13-16K 维度),它反而可能比通用行式更具性能。
因此,虽然我们推荐将行式作为默认选项,但值得将其与 gw_hp 在您的模型上进行比较,以验证哪种提供最佳性能,并有可能获得更高的精度。
通过切换模型转换器的开/关(使用 # ),您可以直接比较 BF16 和 Float8 Rowwise 之间的训练加速,从而了解您自己训练的潜在加速。
未来更新
我们将推出一项额外更新,展示管道并行和异步分布式检查点的多项改进,敬请期待。