作为 PyTorch 2.0 中的 Beta 功能,oneDNN Graph 利用激进的融合模式来加速 x86-64 机器(特别是 Intel® Xeon® 可扩展处理器)上的推理。
oneDNN Graph API 扩展了 oneDNN,提供了一个灵活的图 API,以最大限度地优化 AI 硬件上高效代码的生成。它自动识别要通过融合加速的图分区。融合模式 侧重于融合卷积、矩阵乘法等计算密集型操作及其相邻操作,适用于推理和训练用例。
在 PyTorch 2.0 及更高版本中,oneDNN Graph 可以帮助加速 x86-64 CPU(主要是基于 Intel Xeon 处理器的机器)上的推理,支持 Float32 和 BFloat16(通过 PyTorch 的自动混合精度支持)数据类型。对于 BFloat16,加速仅限于支持 AVX512_BF16 ISA(指令集架构)的机器,以及同时支持 AMX_BF16 ISA 的机器。
oneDNN Graph 用法
从用户的角度来看,使用起来非常简单直观,代码中唯一的改动是 API 调用。要利用 oneDNN Graph 和 JIT 跟踪,需要使用示例输入对模型进行性能分析,如下图 1 所示。
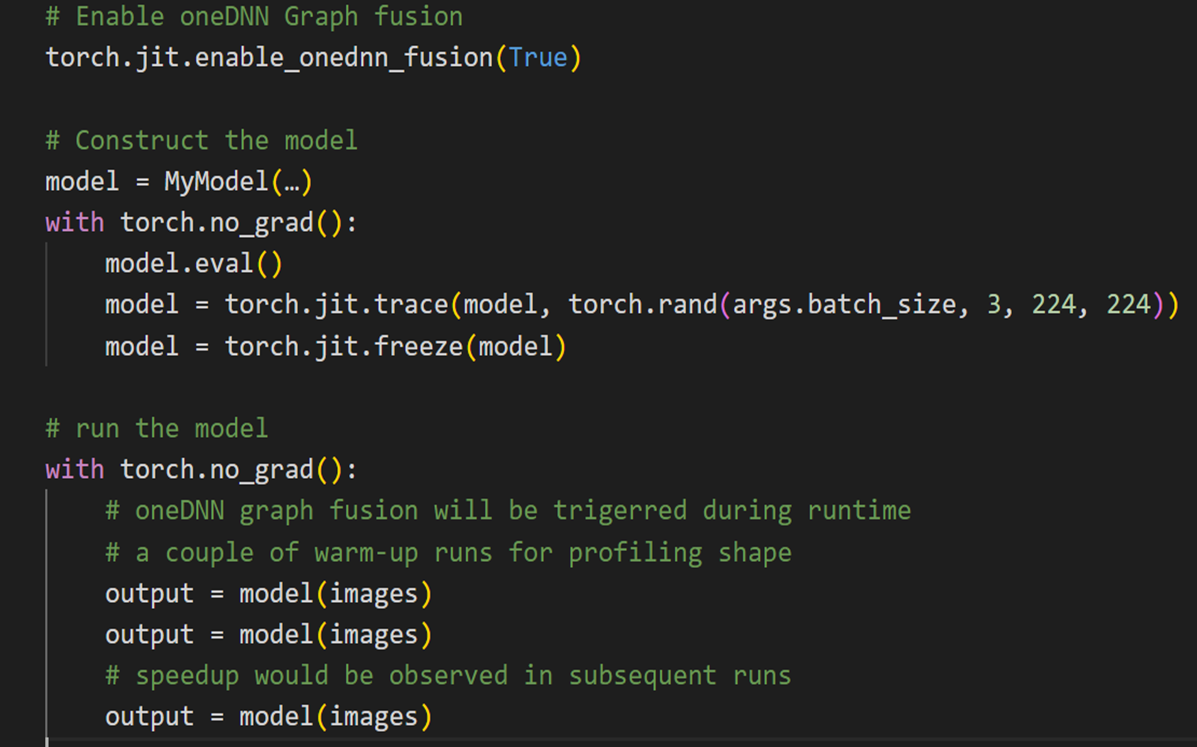
图 1:演示使用 oneDNN Graph 的代码片段
oneDNN Graph 接收模型的图,并根据示例输入的输入形状识别操作符融合的候选者。目前,仅支持静态形状。这意味着任何其他输入形状既不受支持,也无法获得任何性能优势。
测量结果
为确保结果的可复现性,我们使用了 TorchBench 的一个 分支,在 AWS m7i.16xlarge 实例(使用第四代 Intel® Xeon® 可扩展处理器)上测量了一些视觉模型的推理加速情况。
比较的基线是 torch.jit.optimize_for_inference,它只支持 Float32 数据类型。每个模型的批处理大小基于 TorchBench 中使用的相应批处理大小。
在图 2 中,我们描绘了使用 oneDNN Graph 相对于单独使用 PyTorch 的推理加速。oneDNN Graph 对于 Float32 数据类型的几何平均加速为 1.24 倍,对于 BFloat16 数据类型的几何平均加速为 3.31 倍1。
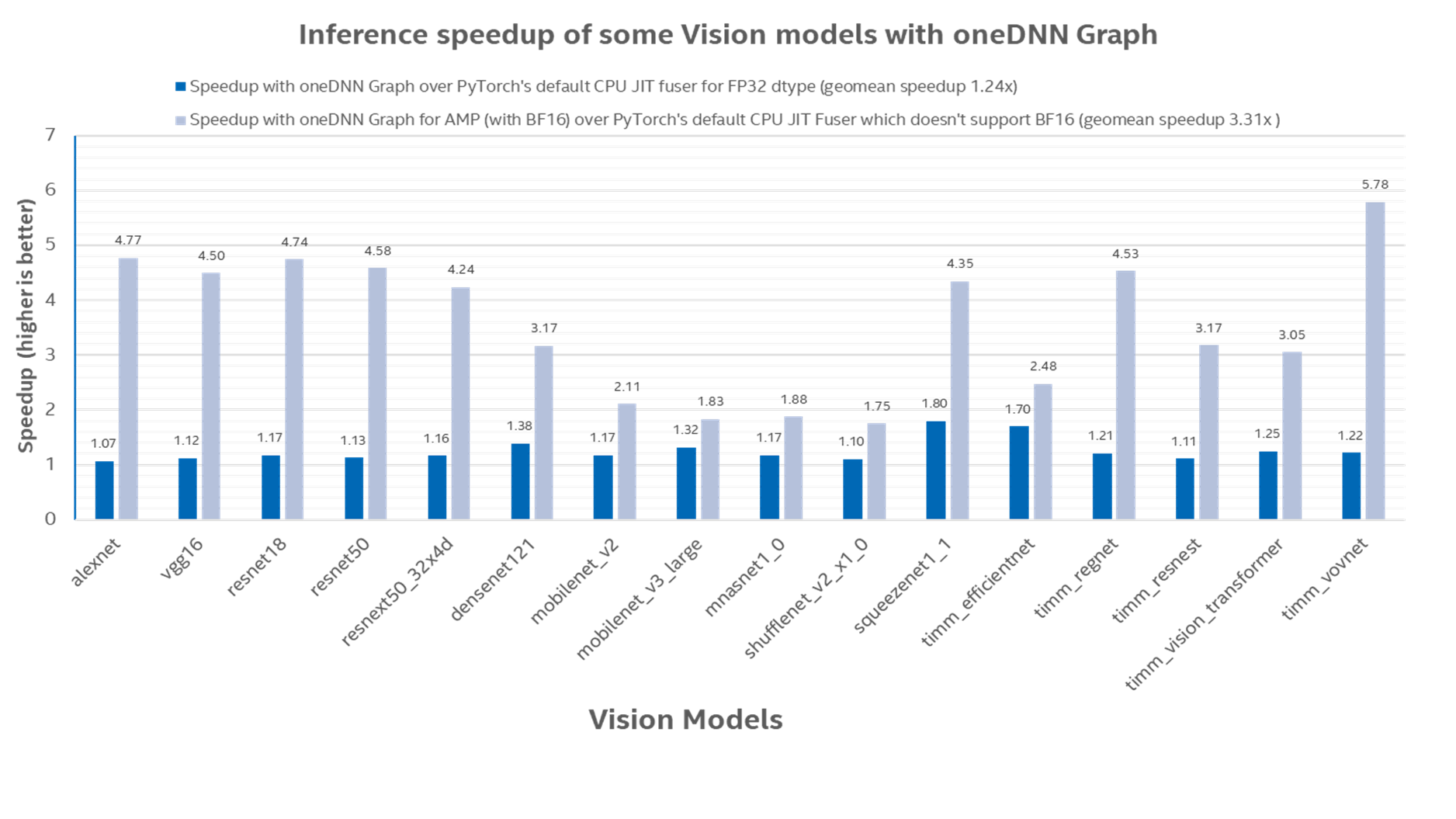
图 2:使用 oneDNN Graph 相对于默认 CPU JIT Fuser(仅使用 Float32 数据类型)的推理加速
未来工作
oneDNN Graph 目前通过 TorchScript 在 PyTorch 中得到支持,但英特尔已经在努力将其集成到 Inductor-CPU 后端,作为未来 PyTorch 版本中的原型功能。Dynamo 将使 PyTorch 支持动态形状更容易,我们希望在 Inductor-CPU 中引入动态形状支持。我们还计划添加 int8 量化支持。
致谢
本博客中呈现的结果是 Meta 和英特尔 PyTorch 团队共同努力的成果。特别感谢 Meta 的 Elias Ellison,他花费宝贵时间彻底审查了 PR 并提供了有益的反馈。