本篇文章是多系列博客的第四部分,主要关注如何使用纯原生 PyTorch 加速生成式 AI 模型。若要跳到代码部分,请查看我们的 GitHub (seamless_communication、fairseq2)。我们很高兴能分享一系列新发布的 PyTorch 性能特性,并结合实际示例,展示如何将 PyTorch 的原生性能推向极致。在第一部分中,我们展示了如何仅使用纯原生 PyTorch 将 Segment Anything 加速 8 倍以上。在第二部分中,我们展示了如何仅使用原生 PyTorch 优化将 Llama-7B 加速近 10 倍。在第三部分中,我们展示了如何仅使用原生 PyTorch 优化将 文本到图像扩散模型加速达 3 倍。
在本篇博客中,我们将重点关注如何加速 FAIR 的 Seamless M4T-v2 模型,通过使用 CUDA Graph 和原生 PyTorch 优化,在不损失准确性的前提下,实现文本解码器模块 2 倍加速,声码器模块 30 倍加速,从而使端到端推理速度提升 2.7 倍。
引言
Seamless M4T 是 FAIR 开发的开源基础语音/文本翻译和转录技术。Seamless M4T 是一个大规模多语言多模态机器翻译模型,其最新版本 (Seamless M4T-v2) 于 2023 年 11 月 30 日发布。Seamless M4T-v2 的高级模型架构如图 1 所示。
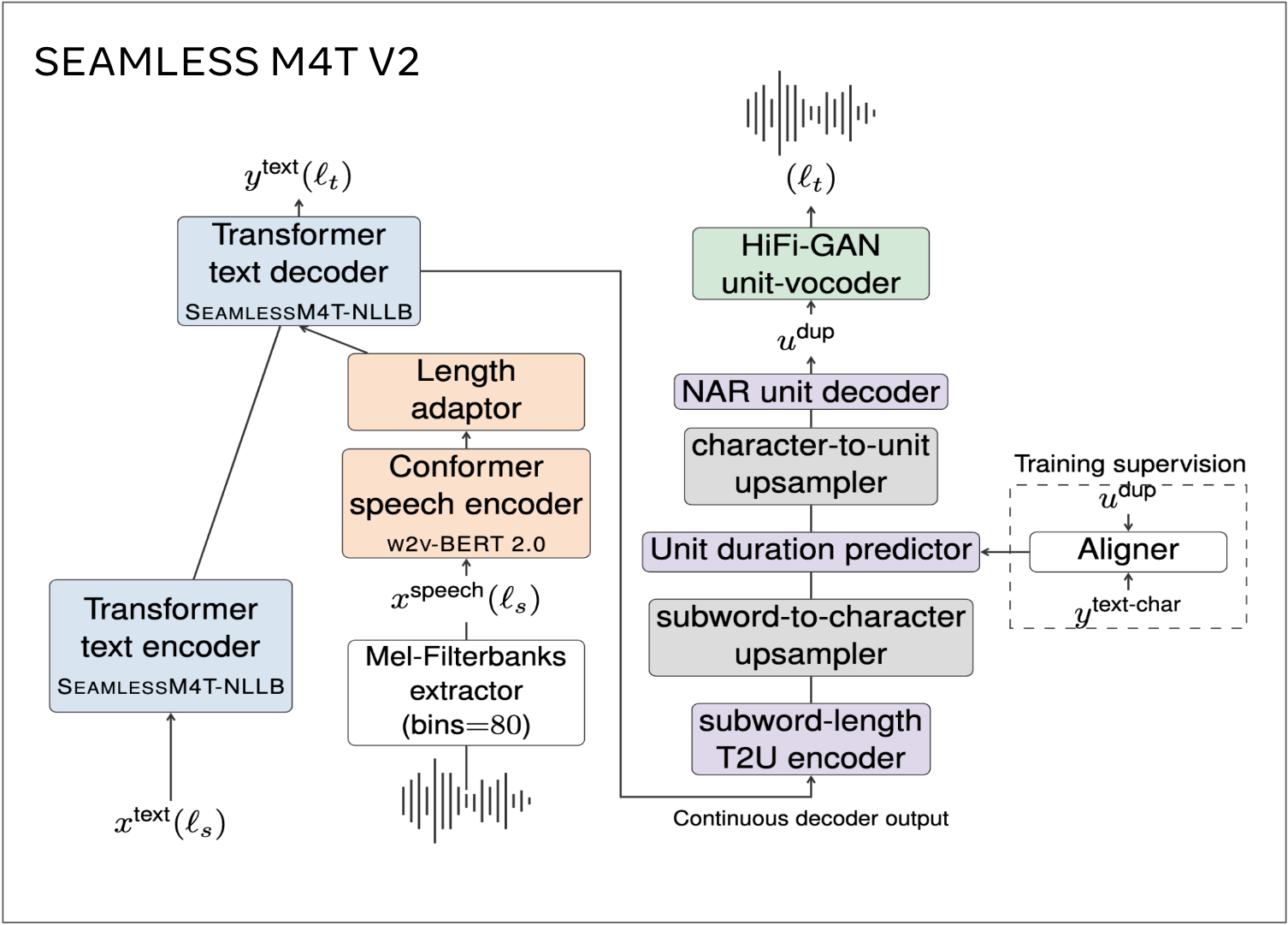
图 1. Seamless M4T-v2 的模型架构。
加速推理延迟对于翻译模型至关重要,它能通过更快的跨语言通信来改善用户体验。特别是,当延迟在聊天机器人、语音翻译和实时字幕等应用中至关重要时,通常使用 batch_size=1 进行快速翻译。因此,我们对 batch_size=1 的推理性能进行了分析,如图 2 所示,以了解阿姆达尔定律的瓶颈。结果表明,文本解码器和声码器是最耗时的模块,分别占推理时间的 61% 和 23%。
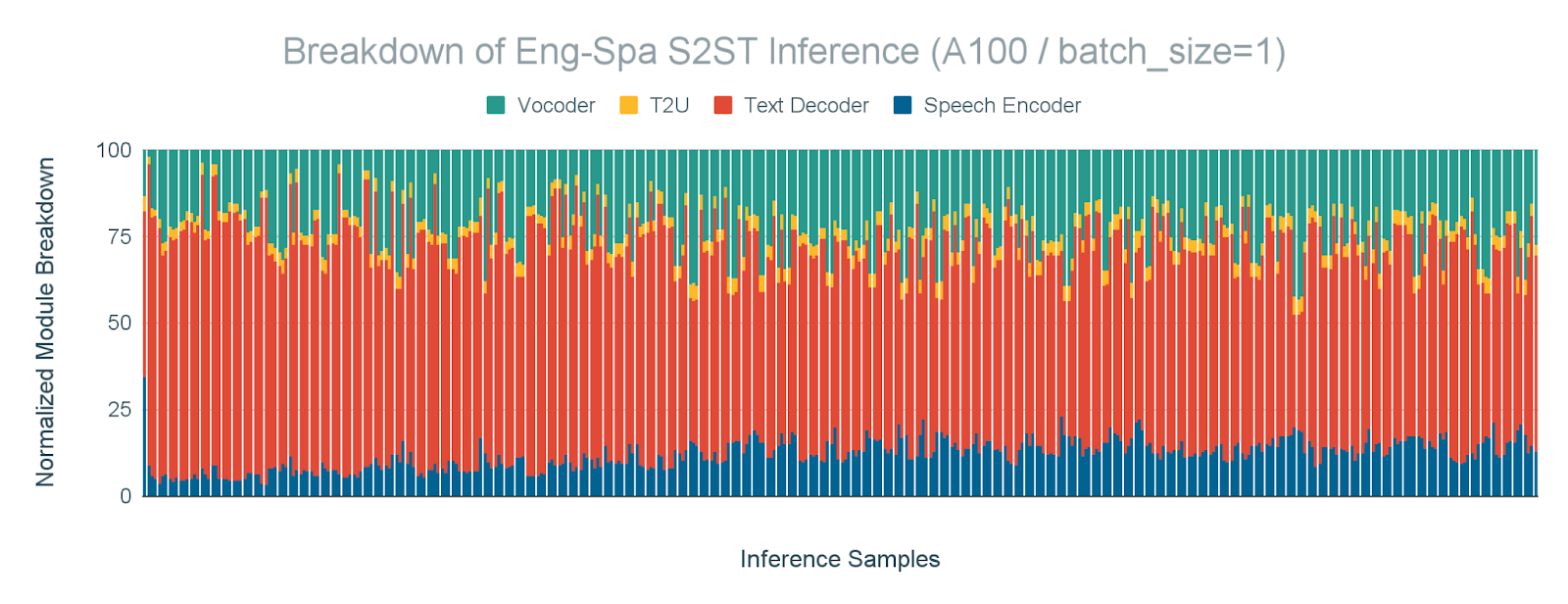
图 2. 文本解码器和声码器是最耗时的模块。在 A100 GPU 上,batch_size=1 的英语-西班牙语 S2ST(语音到语音文本)任务按模块划分的推理时间细分。
为了更深入地了解文本解码器和声码器的性能瓶颈,我们分析了 FLEURS 数据集英语-西班牙语翻译示例中第 8 个样本的文本解码器和声码器 GPU 跟踪,如图 3 所示。结果显示,文本解码器和声码器是严重受 CPU 限制的模块。我们观察到,由于 CPU 开销导致 GPU 内核启动延迟,从而显著增加了两个模块的执行时间。
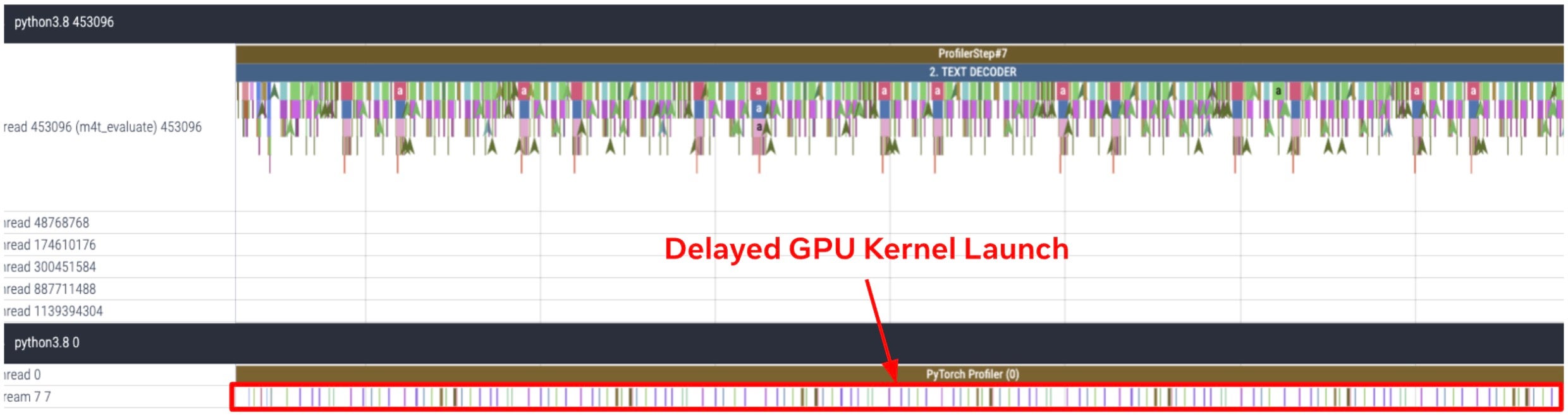
(a) 文本解码器的 CPU 和 GPU 跟踪
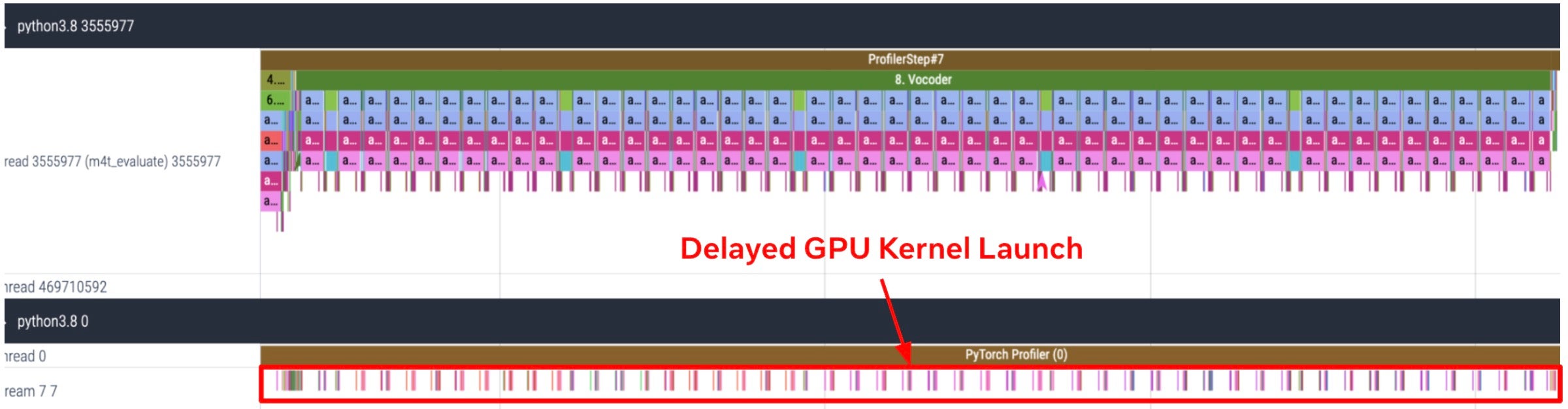
(b) 声码器的 CPU 和 GPU 跟踪
图 3. 文本解码器和声码器是严重受 CPU 限制的模块。(a) 文本解码器 (b) 声码器在 FLEURS 数据集英语-西班牙语翻译示例中第 8 个样本的 CPU 和 GPU 跟踪。该跟踪是在 A100 GPU 上以 batch_size=1 运行推理获得的。
基于对 Seamless M4T-v2 中文本解码器和声码器严重受 CPU 限制模块的真实系统性能分析结果,我们对这些模块启用了 torch.compile + CUDA Graph。在本篇文章中,我们将分享在 batch_size=1 推理场景下,对每个模块启用 torch.compile + CUDA Graph 所需的修改、对 CUDA Graph 的讨论以及下一步计划。
使用 CUDA Graph 进行 Torch.compile
torch.compile 是一个 PyTorch API,允许用户将 PyTorch 模型编译成独立的、可执行的脚本,通常用于通过消除不必要的开销来优化模型性能。
CUDA Graph 是 NVIDIA 提供的一项功能,用于优化 CUDA 应用程序中的内核启动。它创建了 CUDA 内核的执行图,可以在 GPU 上执行之前由驱动程序进行预处理和优化。使用 CUDA Graph 的主要优点是它减少了与启动单个内核相关的开销,因为该图可以作为一个整体启动,减少了主机和设备之间 API 调用和数据传输的数量。这可以显著提高性能,特别是对于包含大量小内核或多次重复相同内核集的应用程序。如果您对此感兴趣,请查阅这篇强调数据在加速计算中重要作用的论文:数据在哪里?为什么没有答案就无法辩论 CPU 与 GPU 的性能,作者是我们自己的 Kim Hazelwood!这正值 NVIDIA 大力投资通用 GPU (GPGPUs) 之前,深度学习彻底改变了计算行业!
然而,由于 CUDA Graph 在编译时记录 1) 固定内存指针和 2) 固定形状的张量,我们引入了以下改进,以便 CUDA Graph 可以在不同大小的输入之间重用,以防止每次迭代都生成 CUDA Graph,并让 CUDA Graph 内的数据在不同运行之间重用,以共享 KV Cache 用于多个解码步骤。
文本解码器
Seamless 中的文本解码器是 NLLB [1] 中的解码器,用于执行 T2TT(文本到文本翻译)。此外,该模块是一个 CPU 限制模型,因为 自回归生成的特性需要按顺序处理 token,这限制了 GPU 上可实现的并行度,导致 GPU 执行时间不足以掩盖 CPU 开销。基于这一观察,我们为文本解码器启用了 torch.compile + CUDA Graph,以减少主要的 CPU 开销,如图 4 所示。
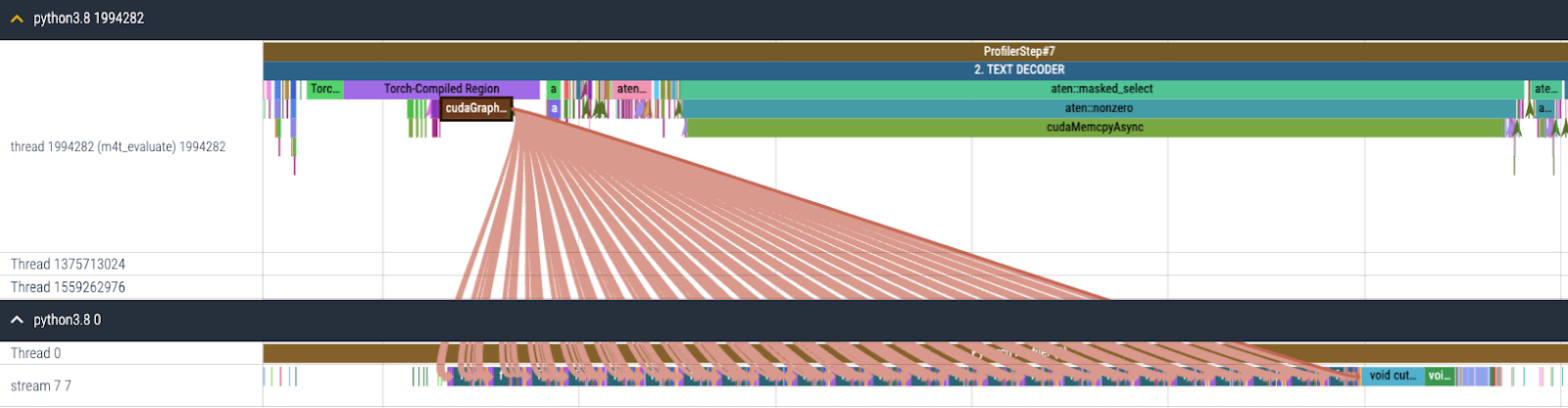
图 4. 启用 torch.compile + CUDA Graph 后文本解码器的 CPU 和 GPU 跟踪。
1. 更新和检索 KV 缓存
在推理过程中,文本解码器有两个计算阶段:一个消耗提示的预填充阶段和一个逐个生成输出 token 的增量生成阶段。如果批处理大小或输入长度足够大,预填充会并行处理足够多的 token — 此时 GPU 性能是瓶颈,CPU 开销对性能影响不大。另一方面,增量 token 生成总是以序列长度为 1 执行,并且通常以小批处理大小(甚至为 1)执行,例如用于交互式用例。因此,增量生成可能会受到 CPU 速度的限制,因此是 torch.compile + CUDA Graph 的理想选择。
然而,在增量 token 生成阶段,注意力计算中涉及的键和值的序列长度维度在每一步都会增加 1,而查询的序列长度始终保持为 1。具体而言,键/值是通过将新计算的序列长度为 1 的键/值附加到目前为止存储在 KV 缓存中的键/值来生成的。但如上所述,CUDA Graph 在编译期间记录所有张量的形状,并以记录的形状进行重播。因此,根据这里的优秀工作,我们进行了一些修改以解决此问题。
a) 我们修改了 KV 缓存处理,使其接受写入新值的索引,这些索引以 CUDA 张量 (即 valid_seq_pos) 而非 Python 整数的形式表示。
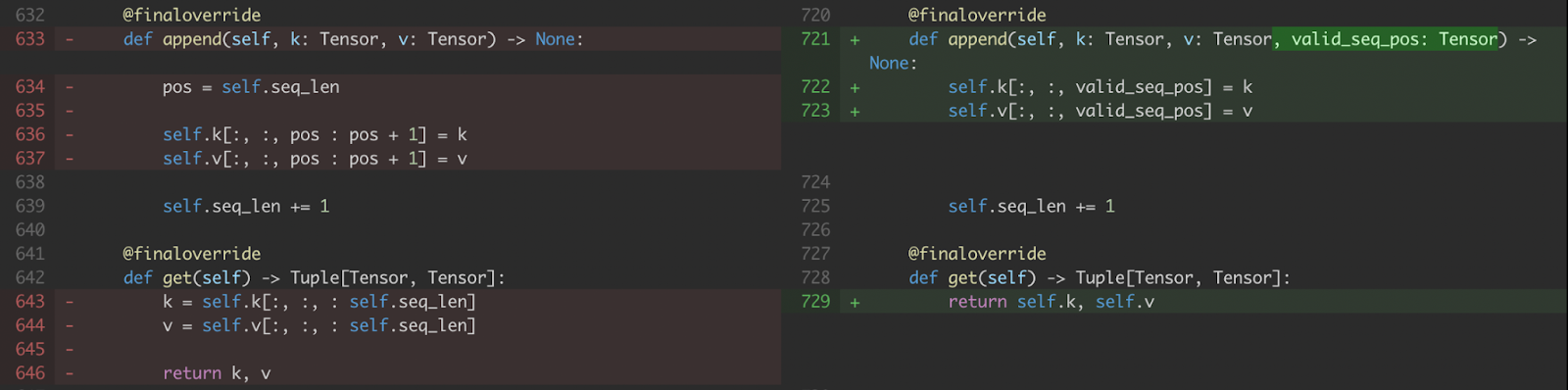
图 5. KV 缓存 append 和 get 的修改
b) 我们还将注意力机制修改为在 max_seq_length 范围内使用固定形状的键和值。我们仅计算到当前解码步骤(即 valid_seq_pos)的序列位置的 softmax。为了屏蔽掉大于当前解码步骤(即 valid_seq_pos)的序列位置,我们创建了一个布尔掩码张量(即 mask),其中大于 valid_seq_pos 的序列位置被设置为 False。
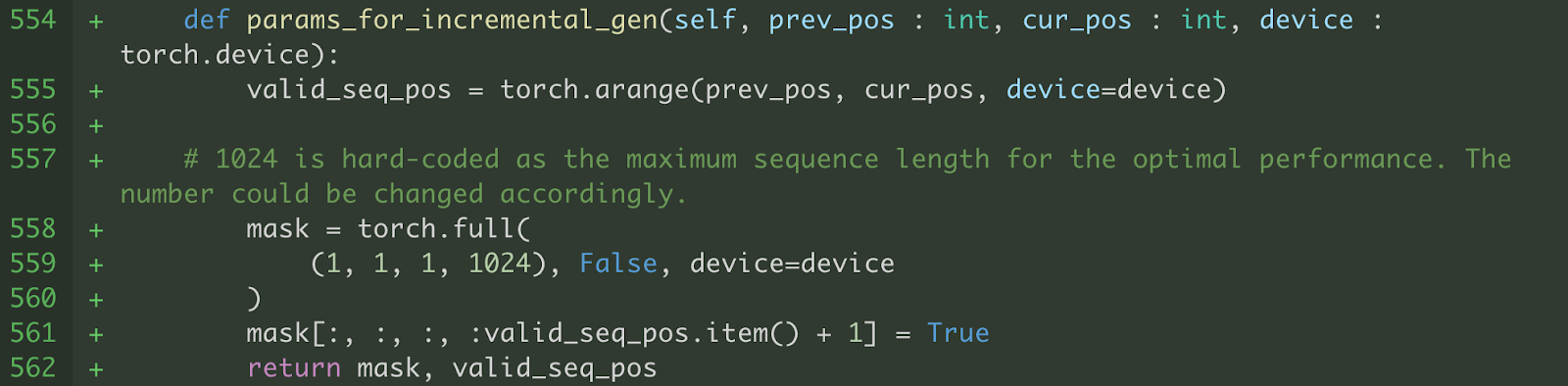
图 6. 生成 valid_seq_pos 和 mask 的辅助函数
需要指出的是,这些修改导致了所需的计算量增加,因为我们对比必要更多(高达 max_seq_length)的序列位置进行了注意力计算。然而,尽管存在这个缺点,我们的结果表明,与标准 PyTorch 代码相比,torch.compile + CUDA Graph 仍然提供了显著的性能优势。
c) 由于不同的推理样本具有不同的序列长度,这也生成了不同形状的输入,这些输入将被投影到交叉注意力层的键和值。因此,我们填充输入以使其具有静态形状,并生成一个填充掩码以屏蔽掉填充的输出。
2. 内存指针管理
由于 CUDA Graph 会记录内存指针以及张量的形状,因此重要的是使不同的推理样本正确引用已记录的内存指针(例如 KV 缓存),以避免为每个推理样本编译 CUDA Graph。然而,Seamless 代码库的某些部分使得不同的推理样本引用不同的内存地址,因此我们进行了修改以改善内存影响。
e) Seamless 采用束搜索作为文本解码策略。在束搜索过程中,我们需要为每个增量解码步骤对所有注意力层执行 KV 缓存重新排序,以确保每个选定的束都能使用相应的 KV 缓存,如下面代码片段所示。

图 8. 束搜索解码策略的 KV 缓存重新排序操作。
上述代码分配了新的内存空间并覆盖了 cache_k 和 cache_v 的原始内存指针。因此,我们修改了 KV 缓存重新排序,通过使用 copy_ 操作符,将每个缓存的内存指针保持在编译时记录的状态。

图 9. 使用 copy_ 操作符对 KV 缓存进行原地更新
f) 如上所述,通过修改代码为文本解码器启用 torch.compile + CUDA Graph 后,文本解码器的开销转移到 KV 缓存重新排序,如图 10 所示。KV 缓存重新排序重复调用 index_select 96 次(假设 24 个解码器层,每个层包含两种类型的注意力层,带有键和值的缓存)。
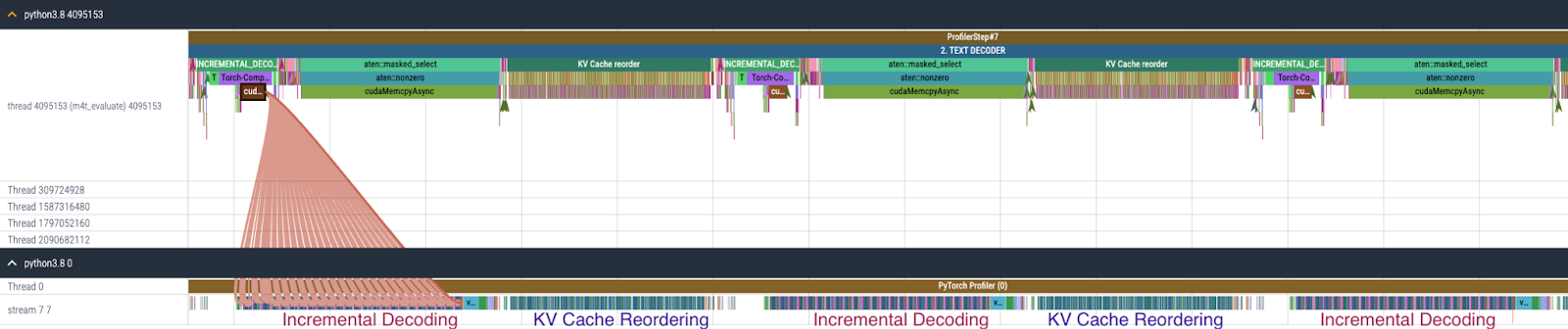
图 10. 启用 torch.compile + CUDA Graph 后文本解码器的 CPU 和 GPU 跟踪。
作为加速文本解码器的一部分,我们额外将 torch.compile 应用于 KV 缓存重排序,以受益于内核融合,如图 11 所示。请注意,我们不能在此处使用 CUDA Graph (mode='max-autotune'),因为 copy_ 操作会修改输入,这违反了 torch.compile 中 CUDA Graph 版本的静态输入要求。
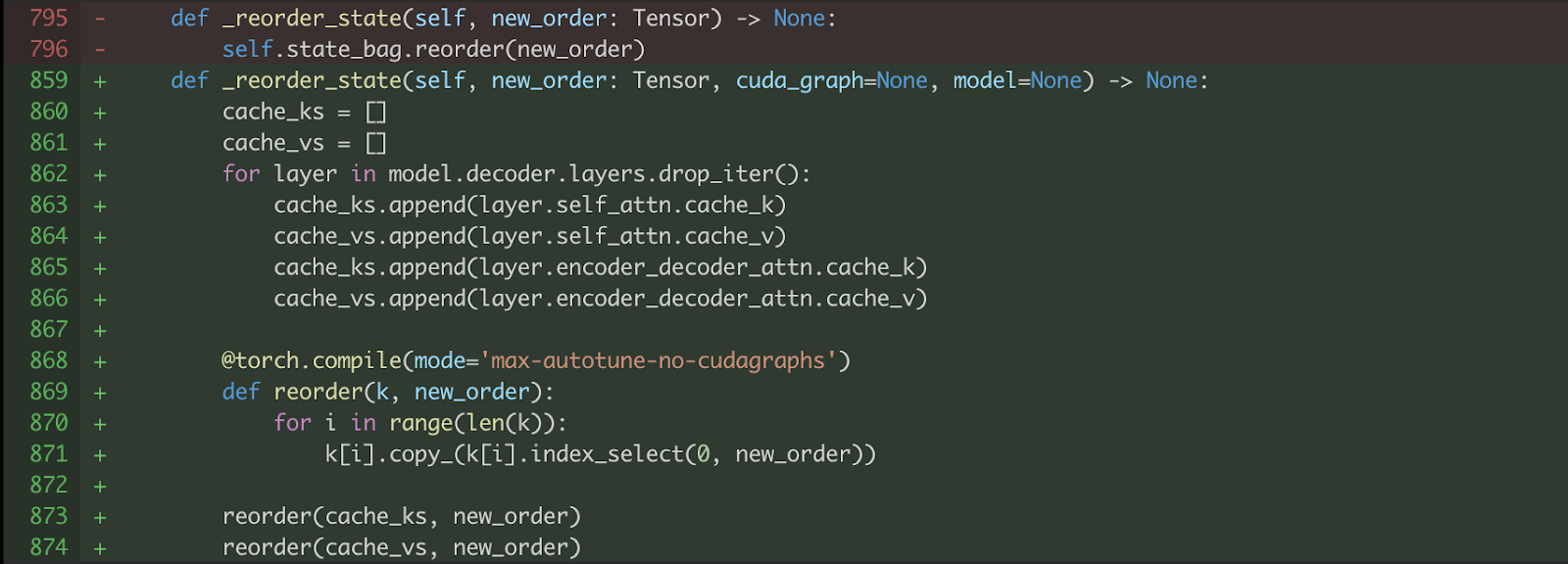
图 11. 将 torch.compile 应用于 KV 缓存重新排序。
将 torch.compile 应用于 KV 缓存重新排序的结果是,之前单独启动的 GPU 内核(图 12(a))现在被融合,因此启动的 GPU 内核数量大大减少(图 12(b))。
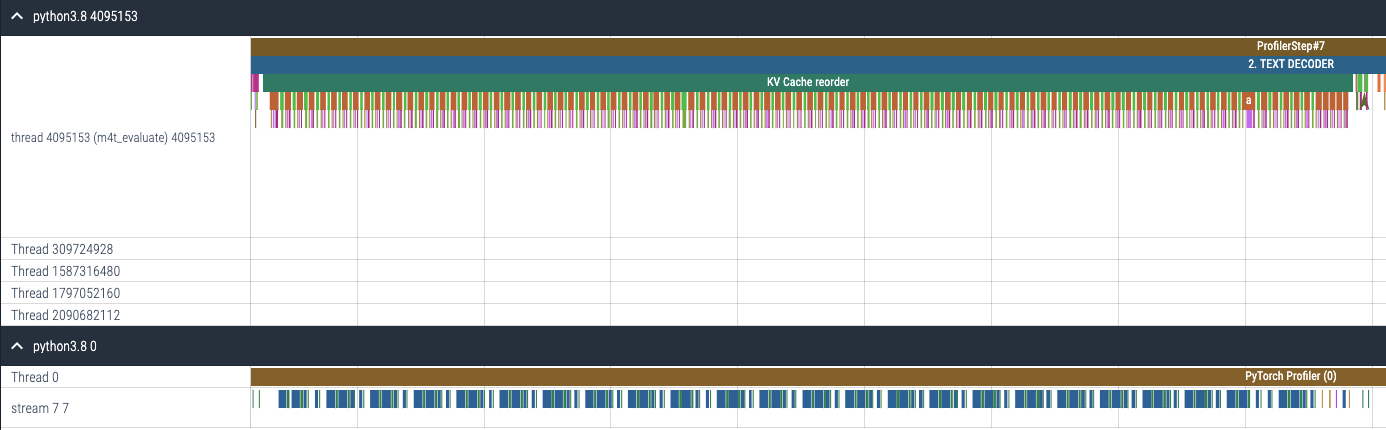
(a) 在启用 torch.compile 之前 KV 缓存重新排序的 CPU 和 GPU 跟踪
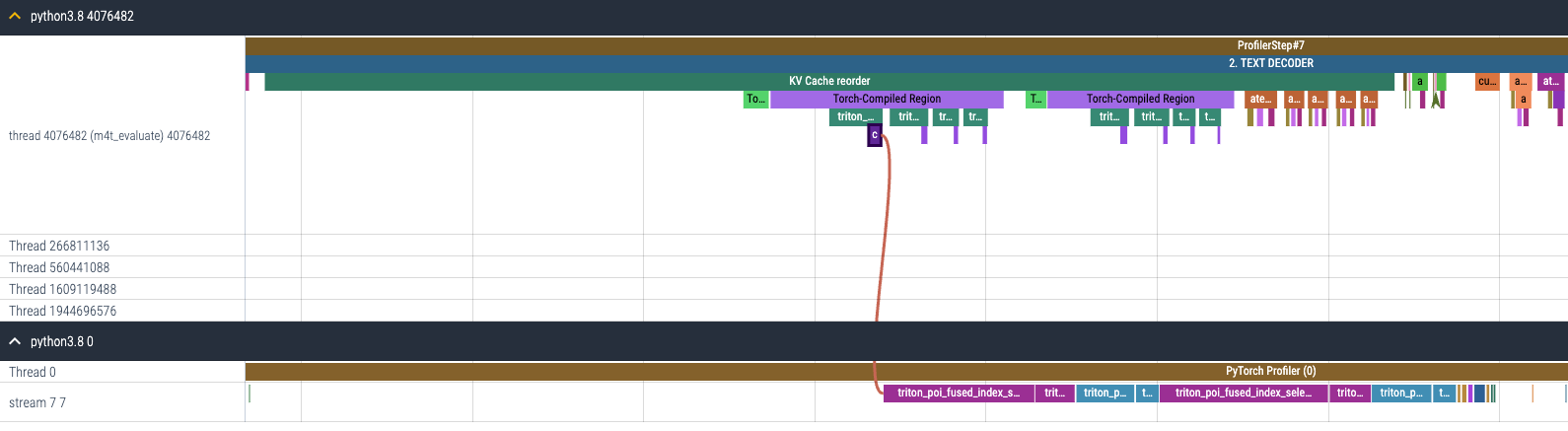
(b) 在启用 torch.compile 之后 KV 缓存重新排序的 CPU 和 GPU 跟踪
图 12. (a) 启用 torch.compile 之前和 (b) 启用 torch.compile 之后 KV 缓存重新排序的 CPU 和 GPU 跟踪
声码器
Seamless 中的声码器是一个 HiFi-GAN 单元声码器,它将生成的单元转换为波形输出,其中单元是语音的表示,结合了音素和音节等不同方面,可用于生成人类可听的声音。声码器是一个相对简单的模块,由 Conv1d 和 ConvTranspose1d 层组成,并且是一个 CPU 限制模块,如图 3 所示。基于此观察,我们决定为声码器启用 torch.compile + CUDA Graph,以减少不成比例的巨大 CPU 开销,如图 10 所示。但仍有几处需要修复。

图 13. 启用 torch.compile + CUDA Graph 后声码器的 CPU 和 GPU 跟踪。
a) 不同推理样本的声码器输入张量形状不同。但由于 CUDA Graph 会记录张量形状并进行回放,因此我们必须用零将输入填充到固定大小。由于声码器只包含 Conv1d 层,我们不需要额外的填充掩码,用零填充就足够了。
b) 声码器由用 torch.nn.utils.weight_norm 包裹的 conv1d 层组成(参见此处)。然而,直接将 torch.compile 应用于声码器会导致如下图所示的图中断,从而导致次优的性能提升。此图中断发生在 PyTorch weight_norm 代码中的 hook 处理部分。
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] Graph break: setattr(UserDefinedObjectVariable) <function Module.__setattr__ at 0x7fac8f483c10> from user code at:
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/vocoder.py", line 49, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return self.code_generator(x, dur_prediction) # type: ignore[no-any-return]1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1520, in _call_impl
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return forward_call(*args, **kwargs)
[2023-12-13 04:26:16,822] [1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/codehifigan.py", line 101, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] return super().forward(x)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/mnt/fsx-home/yejinlee/yejinlee/seamless_communication/src/seamless_communication/models/vocoder/hifigan.py", line 185, in forward
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] x = self.ups[i](x)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/modules/module.py", line 1550, in _call_impl
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] args_result = hook(self, args)
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] File "/data/home/yejinlee/mambaforge/envs/fairseq2_12.1/lib/python3.8/site-packages/torch/nn/utils/weight_norm.py", line 65, in __call__
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG] setattr(module, self.name, self.compute_weight(module))
[1/0_2] torch._dynamo.symbolic_convert.__graph_breaks: [DEBUG]
由于层权重在推理过程中不会改变,我们不需要权重归一化。因此,我们简单地为声码器移除了权重归一化,如图 14 所示,方法是利用 Seamless 代码库中已提供的 remove_weight_norm 函数(此处)。

图 14. 移除声码器的 weight_norm
性能评估 + CUDA Graph 的影响
图 15 展示了在文本解码器和声码器上启用 torch.compile(mode=”max-autotune”) + CUDA Graph 后的加速结果。我们实现了文本解码器 2 倍加速,声码器 30 倍加速,从而使端到端推理时间加快 2.7 倍。
 |  |
图 15. 应用 torch.compile 和 torch.compile + CUDA Graph 后文本解码器和声码器的推理时间加速
我们还报告了使用不带 CUDA Graph 的 torch.compile(由 torch.compile 的 API 支持,即 torch.compile(mode="max-autotune-no-cudagraphs"))的文本解码器和声码器加速比,以确定 CUDA Graph 对性能的影响。在没有 CUDA Graph 的情况下,文本解码器和声码器的加速比分别降低到 1.17 倍和 18.4 倍。虽然仍然相当显著,但这表明了 CUDA Graph 的重要作用。我们得出结论,Seamless M4T-v2 暴露在大量启动 CUDA 内核的时间开销下,特别是当我们使用小批量大小(例如 1)时,此时 GPU 内核执行时间不足以抵消 GPU 内核启动时间。
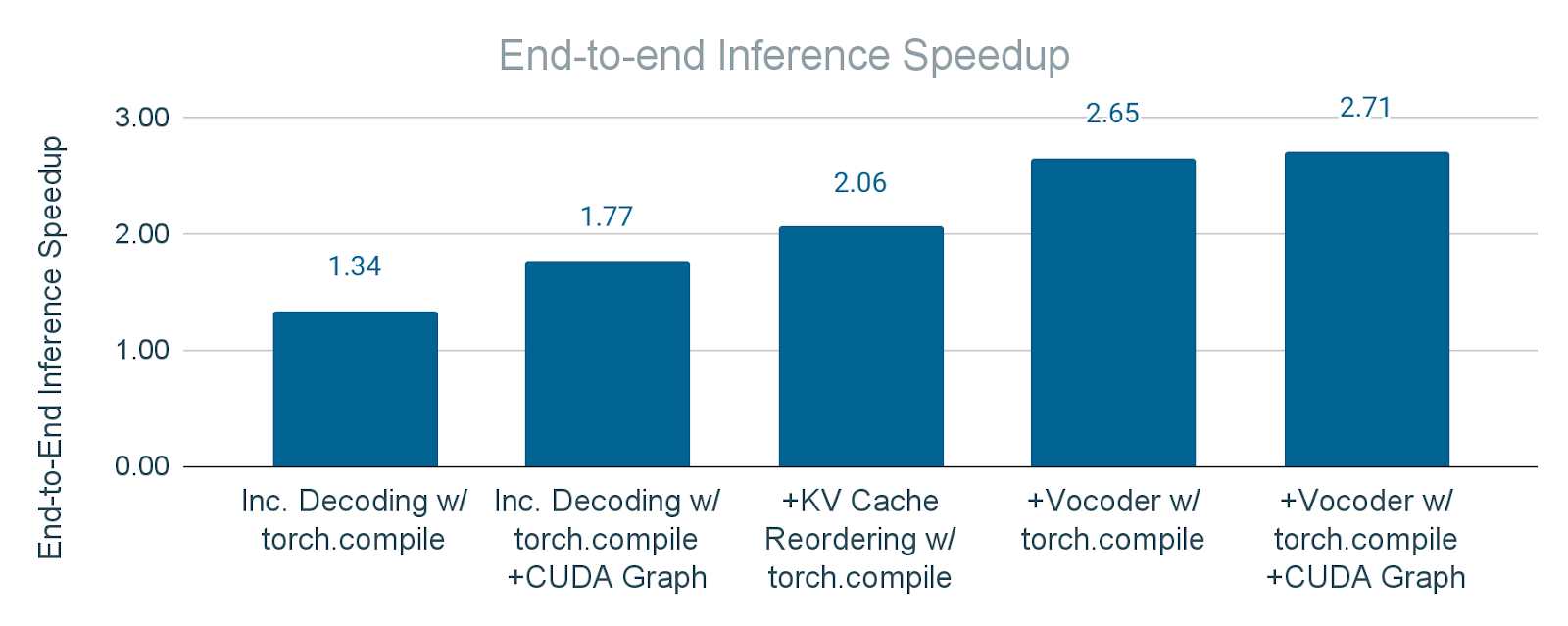
图 16. 逐步应用 torch.compile 和 CUDA Graph 的端到端推理加速。a) “增量解码”:仅将 torch.compile 应用于文本解码器。b) “带 CUDA Graph 的增量解码”:将 torch.compile + CUDA Graph 应用于文本解码器。c) “+KV 缓存重排序”:在 b) 的基础上额外将 torch.compile 应用于 KV 缓存重排序操作。d) “+声码器”:在 c) 的基础上额外将 torch.compile 应用于声码器。e) “+带 CUDA Graph 的声码器”:在 d) 的基础上额外将 torch.compile + CUDA Graph 应用于声码器。
图 16 展示了将 torch.compile(带和不带 CUDA Graph)应用于模块的累积效应。结果表明端到端推理速度显著提升,证明了这些技术在优化整体延迟方面的有效性。结果,Seamless M4T-v2 在 batch_size=1 的情况下,实现了2.7 倍的端到端推理加速。
致谢
我们感谢 PyTorch 团队和 Seamless 团队对这项工作的巨大支持。