Float8 (FP8) 的2D块量化有望提高Float8量化的准确性,同时加速推理和训练的GEMM。在这篇博客中,我们将展示使用Triton在执行块量化Float8 GEMM的两个主要阶段所取得的进展。
对于将A和B张量从高精度(BFloat16)输入量化到Float8,我们展示了GridQuant,它利用了迷你网格步幅循环处理方式,与当前2D块量化内核相比,速度提升了近2倍(99.31%)。
对于Float8 GEMM,我们展示了Triton的3项新发展——Warp Specialization、TMA和持久化内核,以有效地创建协作式内核(Ping-Pong调度的替代方案)。因此,我们比去年表现最好的SplitK内核实现了约1.2倍的速度提升。
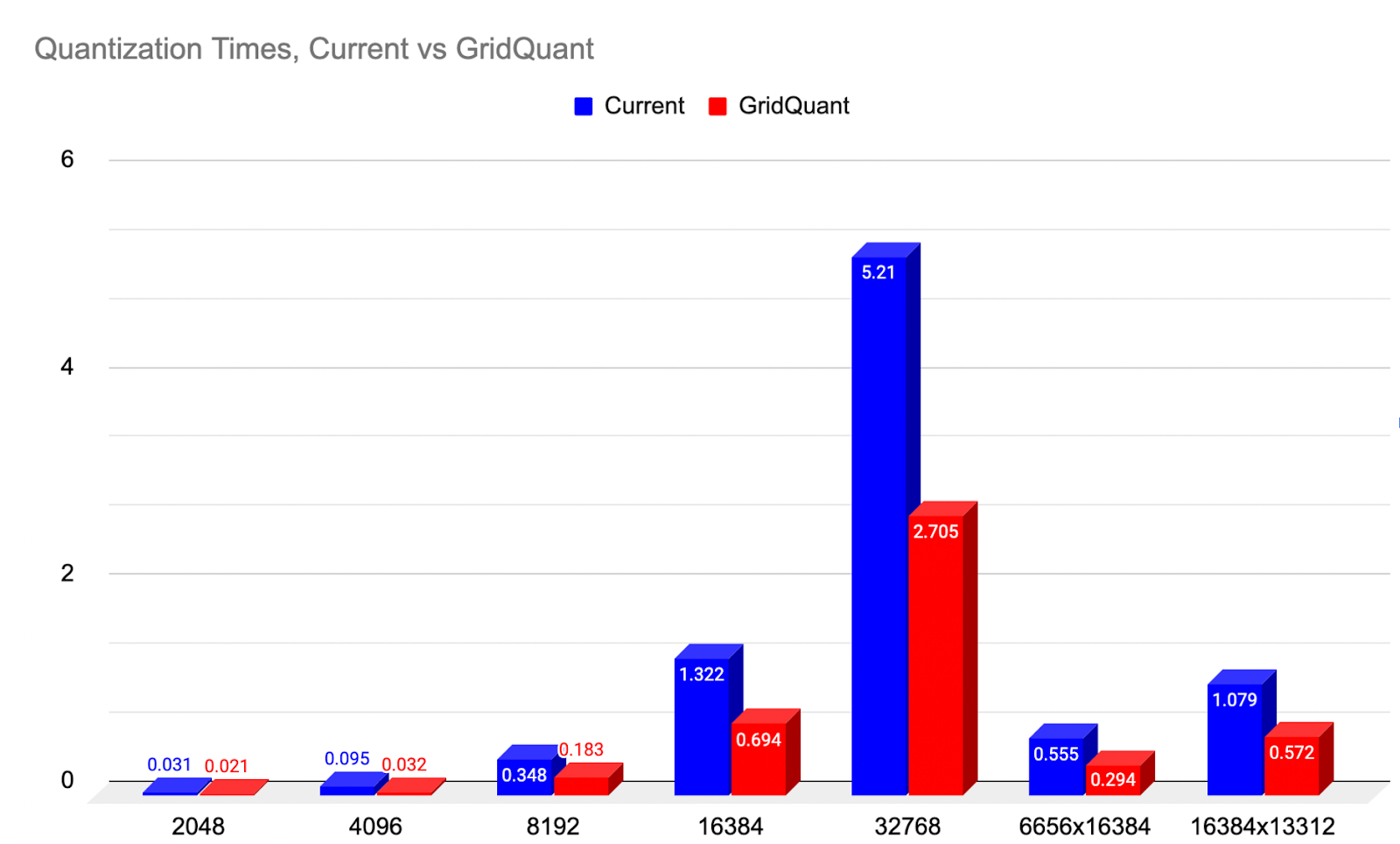
图1: 2D量化在不同尺寸下相对于当前基线的加速比较。(越低越好)
为什么选择FP8的2D块式量化?
一般来说,FP8量化的准确性随着我们从张量级缩放、行级缩放、2D块级缩放,最终到列级缩放而提高。这是因为给定token的特征存储在每列中,因此该张量中的每列都以更相似的方式进行缩放。
为了最小化给定数值集中的离群值数量,我们希望找到共性,以便数值以类似的方式进行缩放。对于transformer来说,这意味着基于列的量化可能是最优的……然而,由于数据在内存中以行式连续的方式布局,列式内存访问效率极低。因此,列式加载将需要涉及大内存步幅的内存访问来提取孤立值,这与高效内存访问的核心原则相悖。
然而,2D是次优选择,因为它包含了一些列式量化的方面,并且由于我们可以使用2D向量化进行矢量化加载,因此提取时内存效率更高。因此,我们希望找到提高2D块量化速度的方法,这就是我们开发GridQuant内核的原因。
对于量化过程,我们需要对传入的高精度BF16张量(A = 输入激活,B = 权重)进行2D块量化,然后使用量化后的张量及其2D块缩放值执行Float8矩阵乘法,并返回BF16格式的输出C张量。
GridQuant如何提高2D块量化效率?
GridQuant内核相对于最初的基线量化实现(一个标准的基于瓦片的实现)有几个改进。GridQuant内核对整个输入张量进行两次完整的遍历,其工作方式如下:
阶段1 – 从传入的高精度张量中确定每个256x256子块的最大绝对值。
1 – 我们将BF16张量划分为256 x 256的子块。此量化大小是可配置的,但256x256是默认值,因为它在量化精度和处理效率之间提供了平衡。
2 – 每个256x256子块被细分为64个子块,以8x8模式排列,每个子块处理一个32x32的元素块。一个warp(32个线程)处理其分配的32x32块内所有元素的计算。
3 – 我们在共享内存中声明一个32x32的max_vals数组。当2D向量块在整个256x256子块中移动时,它将存储每个位置i,j的当前最大值。
这是一个重要的改进,因为这意味着我们可以对max_vals评分系统进行矢量化而非标量更新,从而实现更高效的更新。
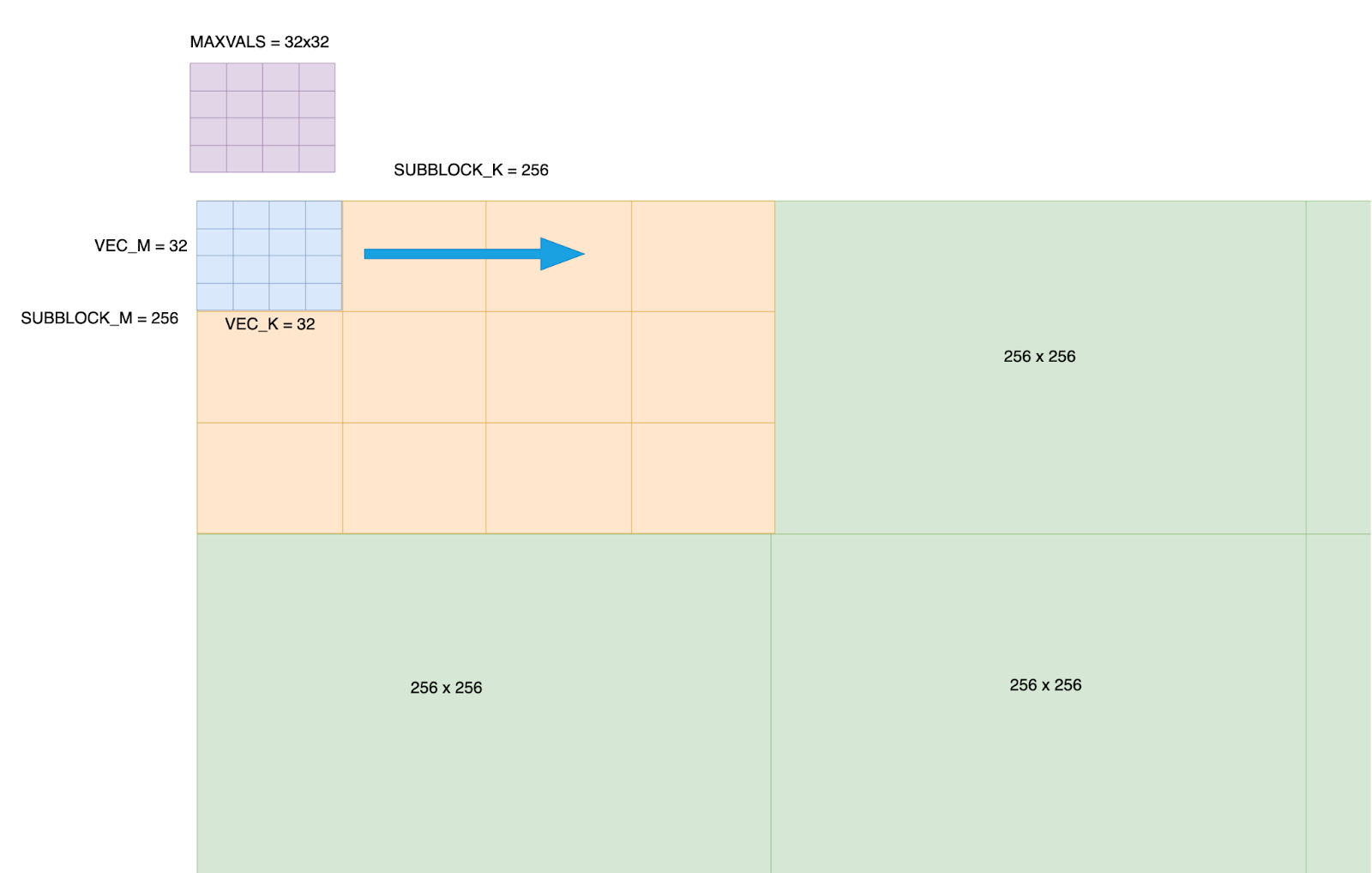
图2: 传入张量的分块布局——在张量上创建一个256x256的网格,并且在每个256x256块内,进一步细化为32x32子块。为每个256x256块创建一个32x32的max_vals。
4 – 每个warp处理一个32x32的块,由于我们使用4个warp,我们确保Triton编译器可以将下一个32x32块的内存加载与当前块的absmax计算的实际处理进行流水线操作。这确保了warp调度器能够切换加载数据的warp和进行处理的warp,从而使SM持续忙碌。
5 – 32x32 2D向量块处理以网格步幅循环的方式在整个256x256子块中移动,每个warp根据其当前的32x32子块更新共享内存中的32x32 max_vals。因此,max_vals[i,j]存储着每个子块处理后的最新最大值。
完成256x256块网格步幅循环后,maxvals矩阵本身会进行归约,以找出整个256块的绝对单一最大值。
这为我们的2D 256 x 256块提供了最终的缩放因子值。
阶段2 – 使用阶段1中找到的单一最大值缩放因子,将256x256块值量化为Float8。
接下来,我们对整个256x256块进行第二次遍历,使用阶段1中找到的最大值重新缩放所有数字,将它们转换为Float 8格式。
因为我们知道需要进行两次完整的遍历,所以在阶段1加载时,我们指示Triton编译器以更高的优先级(逐出策略=最后)将这些值保留在缓存中。
这意味着在第二次遍历期间,我们可以从L2缓存中获得很高的命中率,这比一直访问HBM提供了更快的内存访问速度。
当所有256x256块处理完毕,2D块量化处理完成后,我们可以返回新的Float8量化张量及其缩放因子矩阵,我们将在GEMM处理的下一阶段使用它们。此输入量化也对第二个输入张量重复进行,这意味着我们最终得到A_Float 8、A_scaling_matrix、B_Float8和B_scaling matrix。
GridQuant – GEMM内核
GridQuant-GEMM内核接收上述量化的四个输出进行处理。我们的高性能GEMM内核采用了Triton的几项新发展,以在解码阶段实现LLM推理相关的矩阵形状配置文件中的SOTA性能。
这些新特性常见于HPC优化的内核,如FlashAttention-3和Machete,它们都是使用CUTLASS 3.x构建的。在这里,我们讨论这些方法并展示在Triton中利用它们可以实现的性能优势。
张量内存加速器(TMA)
NVIDIA Hopper GPU上的TMA单元是一个专用的硬件单元,用于对AI工作负载中常见的多维张量执行加载/存储操作。这具有几个重要的优点。
从全局内存和共享内存传输数据可以在不涉及GPU SM上其他资源的情况下进行,从而释放寄存器和CUDA核心。此外,当在warp-specialized内核中使用时,轻量级TMA操作可以分配给生产者warp,从而实现内存传输和计算的高度重叠。
有关Triton中如何使用TMA的更多详细信息,请参阅我们的上一篇博客。
Warp-Specialization(协同持久化内核设计)
Warp Specialization 是一种利用GPU上流水线并行性的技术。这项实验性功能通过 tl.async_task API 实现了专门线程的表达,允许用户指定Triton程序中的操作应如何在warps之间“拆分”。协作式Triton内核执行不同类型的计算和加载,每种都在其专用的硬件上进行。为每个这些专门任务配备专用硬件使得对没有数据依赖的操作实现并行化成为可能。
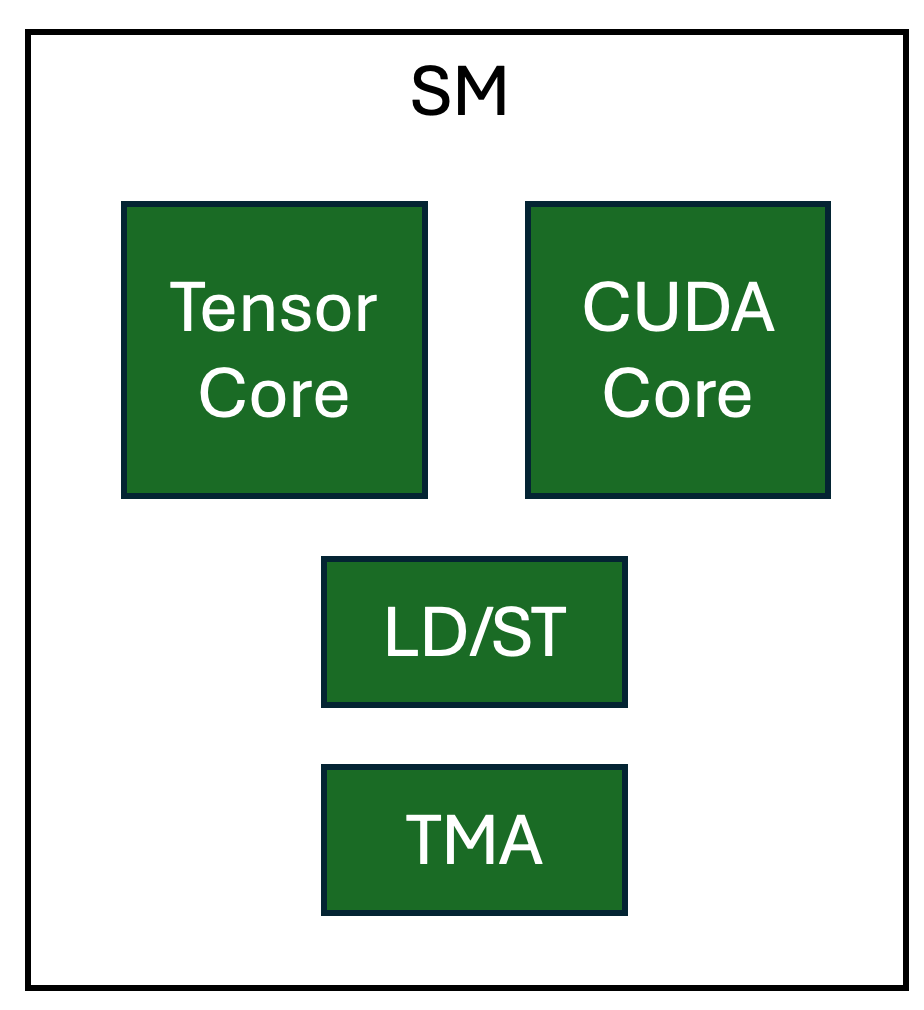
图3。 NVIDIA H100 SM中专用硬件单元的逻辑视图
在我们的内核中创建流水线的操作是
A – 将每个块的缩放因子从GMEM加载到SMEM (cp.async引擎)
B – 将激活(A)和权重(B)瓦片从GMEM加载到SMEM(TMA)
C – A瓦片和B瓦片的矩阵乘法 = C瓦片(Tensor Core)
D – 使用来自A的每个块缩放因子和来自B的每个块缩放因子对C瓦片进行缩放(CUDA核心)
这些步骤可以分配给由线程块中的专用warp组执行的“任务”。协作策略有三个warp组。一个生产者warp组负责向计算单元提供数据,两个消费者warp组执行计算。两个消费者warp组分别处理相同输出瓦片的一半。

图4。 Warp-Specialized持久化协同内核(来源:NVIDIA)
这与我们之前的博客中讨论的乒乓调度不同,在乒乓调度中,每个消费者warp组处理的是不同的输出瓦片。我们注意到Tensor Core操作不与尾声计算重叠。在计算的尾声阶段,Tensor Core流水线利用率的降低将减少消费者warp组的寄存器压力,这与始终保持Tensor Core忙碌的乒乓调度不同,从而允许使用更大的瓦片尺寸。
最后,当网格大小超过H100 GPU上可用计算单元的数量(132)时,我们的内核被设计为持久化。持久化内核在GPU上保持活动状态,并在其生命周期内计算多个输出瓦片。我们的内核利用TMA异步共享到全局内存存储,同时继续处理下一个输出瓦片,而不是承担调度多个线程块的成本。
微基准测试
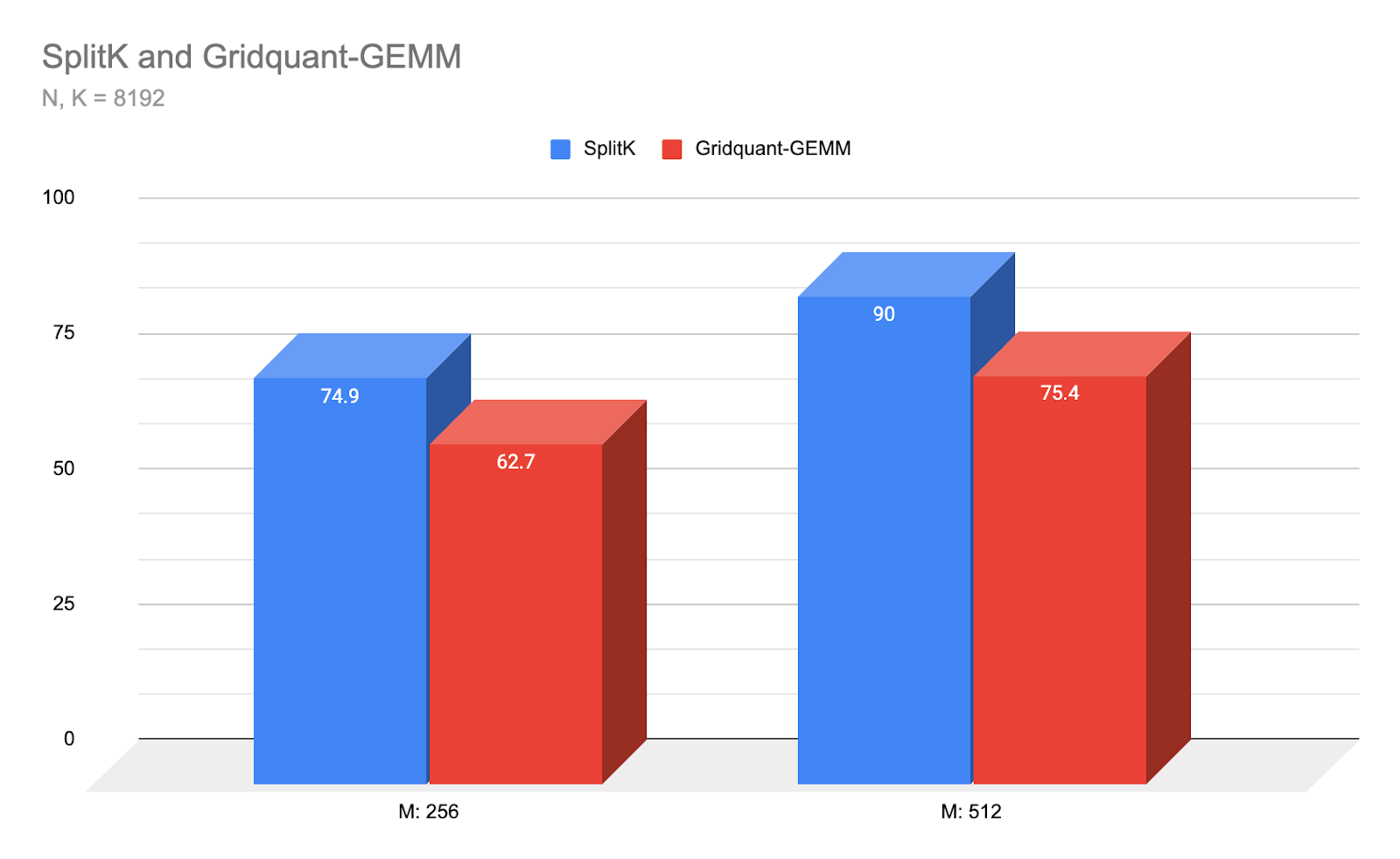
图5: Gridquant-GEMM与我们表现最好的SplitK内核在小批量和Llama3 8192 N,K尺寸下的延迟比较(us)。(越低越好)
Warp-Specialized Triton内核在上述小M和方阵形状下实现了SOTA性能,比SplitK Triton内核(以前在该低算术强度区域中Triton GEMM的最佳策略)实现了近1.2倍的速度提升。对于未来的工作,我们计划优化我们的内核性能,以适应中到大M区域和非方阵。
结论和未来工作
未来的工作包括在端到端工作流中对GridQuant进行基准测试。此外,我们计划对非方阵(矩形)矩阵以及中到大M尺寸进行更广泛的基准测试。最后,我们计划探索Triton中的乒乓式warp-specialization与当前协作实现。