TLDR:使用 MXFP8 训练加速 1.22 倍 – 1.28 倍,与 BF16 相比收敛性相当。
我们最近与一个 Crusoe B200 集群合作,该集群拥有 1856 个 GPU,首次体验到使用新的 MX-FP8 数据类型与 TorchAO 的实现和 TorchTitan(Llama3-70B,HSDP2,上下文并行=2)带来的训练速度提升。 这项工作与我们之前在 Crusoe H200s 上的大规模训练在精神上相似。
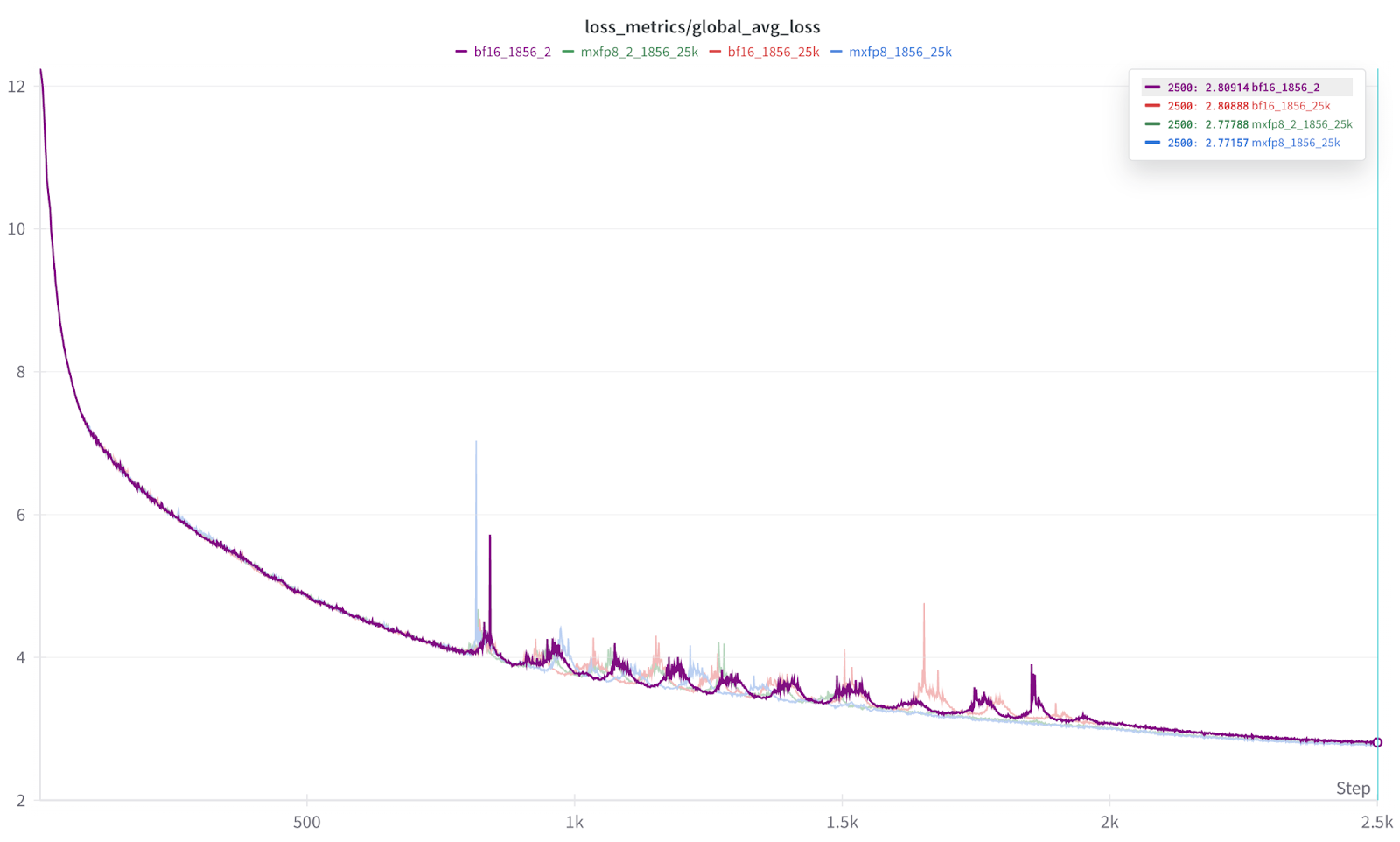
我们的测试表明,即使在全部 1856 个 GPU 规模下,与 BF16 训练相比,损失曲线等效且加速了 1.22 倍到 1.28 倍。
- 请注意,这些结果是使用早期 [v0.10,2025 年 4 月] 版本的 TorchAO 获得的,并且相关内核一直在改进,因此如果再次运行,将产生更快的结果。
值得注意的是,当从 4 个节点扩展到 188 个节点时,我们观察到的性能差异仅约为 5%,总世界规模增加了 47 倍。
背景 – 通过缩放精度实现 Float8 进展
我们之前使用过各种 Float8 实现,其缩放精度水平不断提高。缩放因子范围从 张量级(即整个张量一个缩放因子)到 行级(即每行一个缩放因子),现在到 MX 样式(即每 32 个元素一个缩放因子)。
在此基础上,DeepSeek 推广了一种更细粒度的 Float8 实现,其中输入(A 矩阵)以 1×128 缩放进行量化,权重(B 矩阵)以 128×128 块级缩放。
大约在同一时间,TorchAO 发布了 Float8 行级,其中每行都有一个单一的缩放因子。我们之前在 Crusoe H200 集群上测试了这一点,展示了损失收敛。
这就引出了目前最细粒度的缩放,MXFP8。
最初由微软开创, MX 已成为 OCP 标准。对于 Nvidia Blackwell 上的 MXFP8,我们有硬件支持的 mxfp8,其中张量的 32 个元素(1×32)块使用一个缩放因子进行量化。
直观地看,1×32 的缩放应该比 1×128 等提供更高的精度,而且通过 Blackwell,我们可以要求硬件进行量化,条件是 K % 32 == 0(基本上,张量必须能被 32 整除,这样我们就不会遇到填充要求)。
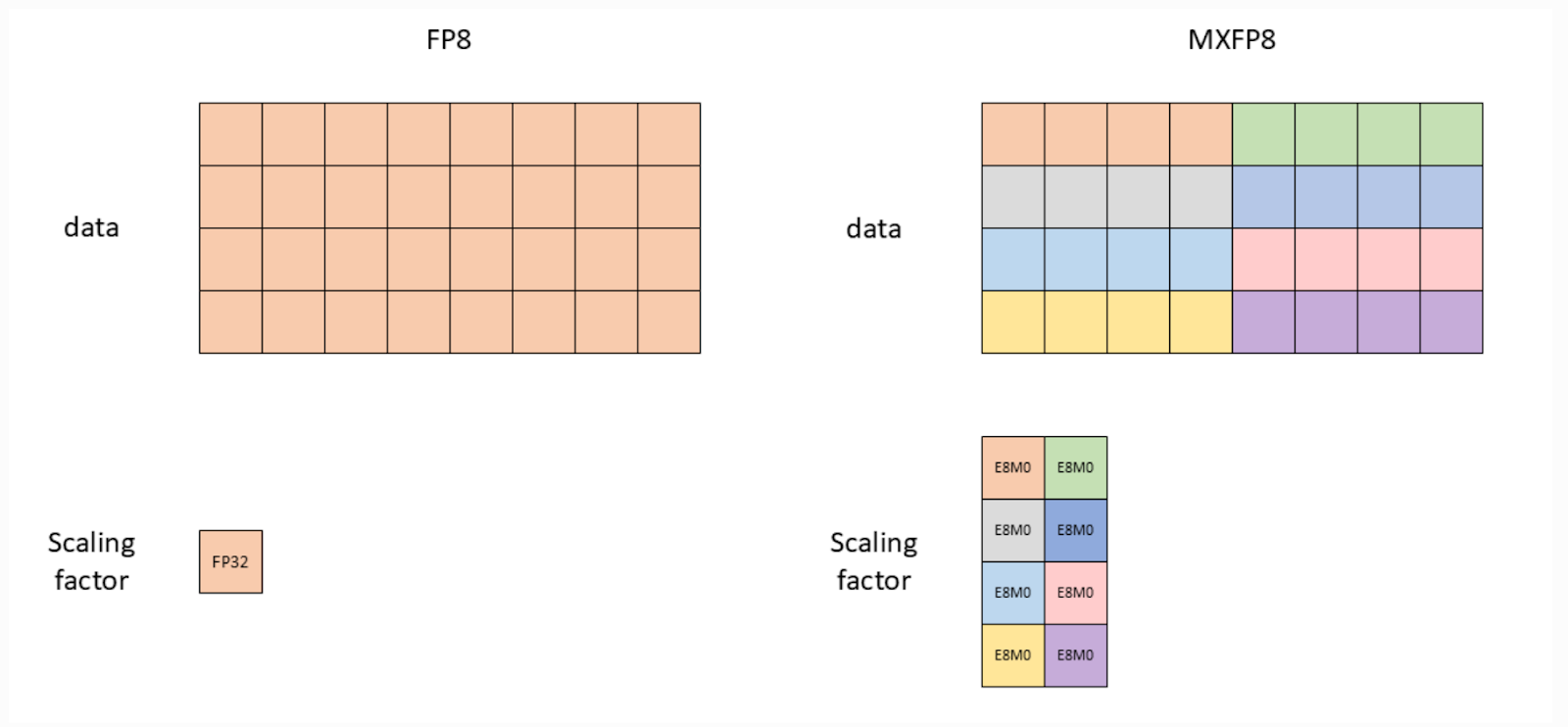
图 1:Float8 张量级(左)与 MXFP8(右)的视觉比较(图片来源:NVIDIA 文档)
另一个变化是缩放因子精度从 FP32 变为 E8M0(实际上是 2 的幂次缩放)

图 2:缩放因子 dtype 比较(图片来源:NVIDIA 文档)
MXFP8 训练加速结果:
接下来,我们可以回顾与 BF16 运行 TorchTitan(Llama3-70B 模型大小、HSDP2 和上下文并行=2)相比的加速情况。
我们看到加速范围从 1504 GPU 规模下的 1.22 倍到 32 GPU 规模下的 1.285 倍
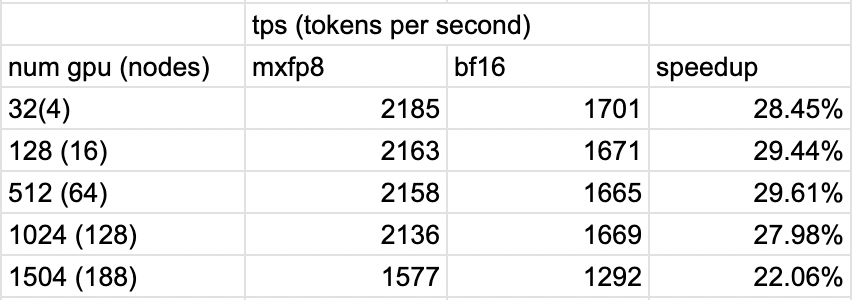
图 3:MXFP8 在不同 GPU 规模下训练的加速效果
MXFP8 收敛结果:
更重要的是,在 1856 规模下,我们还看到损失曲线的收敛性几乎相同(MXFP8 略占优势)
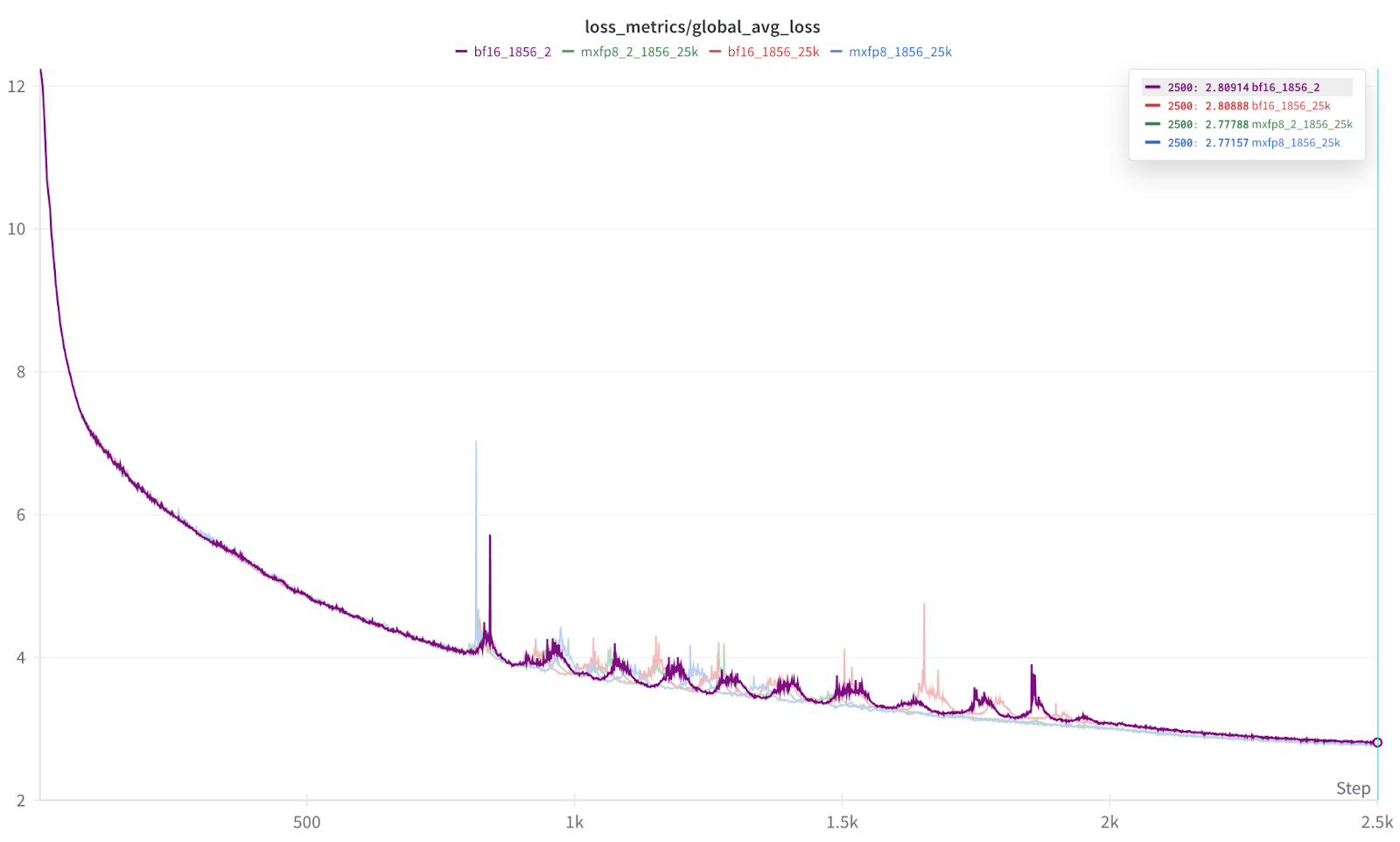
图 4:多次训练运行的损失曲线叠加
结果的放大图。 每次运行重复 2 次,以帮助证明结果的一致性。
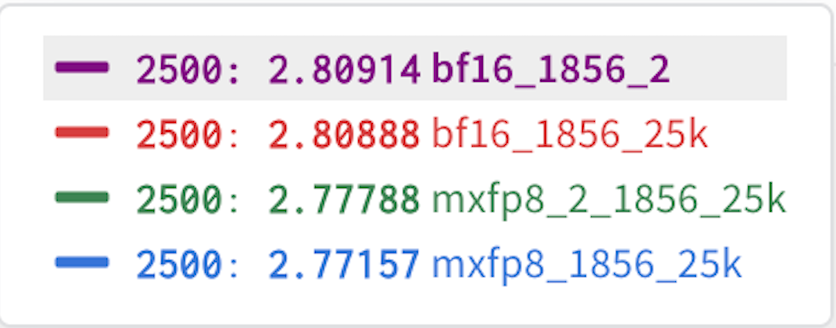
图 5:每次 2500 次迭代运行的最终结果。
从图 5 的结果可以看出,每种数据类型(BF16、MXFP8)的运行结果几乎无法区分,而且我们还发现 MXFP8 的结果始终略微领先。 因此,在我们的初步测试中,我们发现 MXFP8 既提供了训练加速,又提供了与 BF16 相同或略好的收敛性/准确性。
未来工作
这些大规模运行的目的是建立初始性能指标和损失收敛方面的数值等效性,将 TorchAO 的 MXFP8 与 BF16 进行比较。
我们已经改进了相关内核,例如
dim1
此外,我们计划基于 Quartet 论文探索未来的 MXFP4 和 NVFP4 训练。