使用Intel® Extension for PyTorch提升图像处理性能
PyTorch提供了出色的CPU性能,并且可以通过Intel® Extension for PyTorch进一步加速。我使用PyTorch 1.13.1(采用ResNet34 + UNet架构)训练了一个AI图像分割模型,用于从卫星图像中识别道路和限速,所有这些都在第四代英特尔®至强®可扩展处理器上完成。
我将引导您完成使用名为SpaceNet5的卫星图像数据集的步骤,以及我如何通过简单地切换几个关键设置来优化代码,从而使深度学习工作负载在CPU上可行。
在我们开始之前,一些准备工作……
本文随附的代码可在Intel Extension for PyTorch仓库的示例文件夹中找到。我大量借鉴了City-Scale Road Extraction from Satellite Imagery (CRESI)仓库。我将其改编用于第四代英特尔至强处理器,并进行了PyTorch优化和Intel Extension for PyTorch优化。特别是,我能够利用这里的笔记本拼凑出一个工作流程。
您可以在YouTube上找到我做过的相关演讲。
我还强烈推荐这些文章,它们详细解释了如何开始使用SpaceNet5数据。
- SpaceNet 5 基线 — 第一部分:图像和标签准备
- SpaceNet 5 基线 — 第二部分:训练道路速度分割模型
- SpaceNet 5 基线 — 第三部分:从卫星图像中提取道路速度向量
- SpaceNet 5 获奖模型发布:道路尽头
我引用了Julien Simon的两篇Hugging Face博客;他在AWS实例r7iz.metal-16xl上进行了测试。
在主要云服务提供商(CSP)上使用CPU实例而不是GPU实例可以显著节省潜在成本。最新的处理器仍在向CSP推出,因此我使用的是托管在Intel® Developer Cloud上的第四代英特尔至强处理器(您可以在此处注册Beta版:cloud.intel.com)。
在AWS上,注册预览版后(图1),您可以选择r7iz.* EC2实例此处。撰写本文时,新的AI加速引擎Intel® Advanced Matrix Extensions (Intel® AMX)仅在裸机上可用,但很快就会在虚拟机上启用。
图1。AWS EC2上的第四代至强实例列表(作者供图)
在Google Cloud* Platform上,您可以选择第四代至强可扩展处理器C3虚拟机(图2)。
图2。Google Cloud Platform上的第四代英特尔至强可扩展处理器实例列表(作者供图)
硬件介绍与优化
第四代英特尔至强处理器于2023年1月发布,我使用的裸机实例具有两个插槽(每个插槽有56个物理核心)、504 GB内存和英特尔AMX加速。我在后端安装了一些关键库,用于控制和监控CPU上我正在使用的插槽、内存和核心。
numactl(通过sudo apt-get install numactl安装)
libjemalloc-dev(通过sudo apt-get install libjemalloc安装)
intel-openmp(通过conda install intel-openmp安装)
gperftools(通过conda install gperftools -c conda-forge安装)
PyTorch和Intel Extension for PyTorch都有辅助脚本,因此无需显式使用intel-openmp和numactl,但它们确实需要在后端安装。如果您想为其他工作设置它们,以下是我为OpenMP*使用的…
export OMP_NUM_THREADS=36
export KMP_AFFINITY=granularity=fine,compact,1,0
export KMP_BLOCKTIME=1
…其中OMP_NUM_THREADS是分配给作业的线程数,KMP_AFFINITY影响线程亲和性设置(包括将线程紧密打包在一起、固定线程的状态),而KMP_BLOCKTIME设置了空闲线程在进入睡眠状态之前应等待的毫秒数。
以下是我为numactl使用的…
numactl -C 0-35 --membind=0 train.py
…其中-C指定要使用的核心,而--membind指示程序仅使用一个插槽(本例中为插槽0)。
SpaceNet数据
我正在使用来自SpaceNet 5挑战赛的卫星图像数据集。不同城市的数据可以从AWS S3存储桶免费下载。
aws s3 ls s3://spacenet-dataset/spacenet/SN5_roads/tarballs/ --human-readable
2019-09-03 20:59:32 5.8 GiB SN5_roads_test_public_AOI_7_Moscow.tar.gz
2019-09-24 08:43:02 3.2 GiB SN5_roads_test_public_AOI_8_Mumbai.tar.gz
2019-09-24 08:43:47 4.9 GiB SN5_roads_test_public_AOI_9_San_Juan.tar.gz
2019-09-14 13:13:26 35.0 GiB SN5_roads_train_AOI_7_Moscow.tar.gz
2019-09-14 13:13:34 18.5 GiB SN5_roads_train_AOI_8_Mumbai.tar.gz
您可以使用以下命令下载并解压文件
aws s3 cp s3://spacenet-dataset/spacenet/SN5_roads/tarballs/SN5_roads_train_AOI_7_Moscow.tar.gz .
tar -xvzf ~/spacenet5data/moscow/SN5_roads_train_AOI_7_Moscow.tar.gz
数据集准备
我使用了莫斯科卫星图像数据集,该数据集包含1,352张1,300 x 1,300像素的图像,以及单独文本文件中对应的街道标签。该数据集包含8波段多光谱图像和3波段RGB图像。图3显示了四张示例RGB卫星图像及其对应的生成的掩膜。我使用CRESI仓库中的speed_masks.py脚本生成分割掩膜。
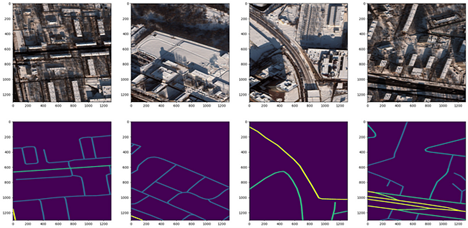
图3。来自莫斯科的卫星图像3通道RGB切片(顶行)和具有不同限速的相应像素分割掩膜(底行)(作者供图)
有一个JSON配置文件必须更新所有剩余组件:训练和验证拆分、训练和推理。此处可找到一个示例配置。我执行了80:20的训练/验证拆分,确保指向正确的卫星图像文件夹和用于训练的相应掩膜。配置参数在此处Intel Extension for PyTorch的GitHub示例中的笔记本中有更详细的解释。
训练ResNet34 + UNet模型
我对下面描述的cresi代码进行了一些更改,以便在CPU上运行并优化训练。要在CPU上原生运行,请在train.py脚本中将self.model = nn.DataParallel(model).cuda()替换为self.model = nn.DataParallel(model)。在01_train.py脚本中,删除torch.randn(10).cuda()。
为了优化训练,在train.py脚本的导入语句中添加import intel_extension_for_pytorch as ipex。在如下定义模型和优化器之后
self.model = nn.DataParallel(model)
self.optimizer = optimizer(self.model.parameters(), lr=config.lr)
添加ipex.optimize行以使用BF16精度,而不是FP32:\
self.model, self.optimizer = ipex.optimize(self.model,
optimizer=self.optimizer,dtype=torch.bfloat16)
在运行前向传播和计算损失函数之前,添加一行用于混合精度训练
with torch.cpu.amp.autocast():
if verbose:
print("input.shape, target.shape:", input.shape, target.shape)
output = self.model(input)
meter = self.calculate_loss_single_channel(output, target, meter, training, iter_size)
现在我们已经优化了训练代码,可以继续训练模型了。
像SpaceNet 5竞赛的获胜者一样,我训练了一个ResNet34编码器+UNet解码器模型。它使用ImageNet权重进行预训练,并且在训练过程中主干网络完全不冻结。训练可以使用01_train.py脚本运行,但为了控制硬件的使用,我使用了辅助脚本。实际上有两个辅助脚本:一个来自标准PyTorch,另一个来自Intel Extension for PyTorch。它们都完成相同的事情,但标准PyTorch的第一个是torch.backends.xeon.run_cpu,而Intel Extension for PyTorch的第二个是ipexrun。
以下是我在命令行中运行的命令:
python -m torch.backends.xeon.run_cpu --ninstances 1 \
--ncores_per_instance 32 \
--log_path /home/devcloud/spacenet5data/moscow/v10_xeon4_devcloud22.04/logs/run_cpu_logs \
/home/devcloud/cresi/cresi/01_train.py \
/home/devcloud/cresi/cresi/configs/ben/v10_xeon4_baseline_ben.json --fold=0
ipexrun --ninstances 1 \
--ncore_per_instance 32 \
/home/devcloud/cresi/cresi/01_train.py \
/home/devcloud/cresi/cresi/configs/ben/v10_xeon4_baseline_ben.json --fold=0
在这两种情况下,我都在要求PyTorch在一个具有32个核心的插槽上运行训练。运行后,我将获得一个打印输出,其中显示了在后端设置了哪些环境变量,以便了解PyTorch如何使用硬件。
INFO - Use TCMalloc memory allocator
INFO - OMP_NUM_THREADS=32
INFO - Using Intel OpenMP
INFO - KMP_AFFINITY=granularity=fine,compact,1,0
INFO - KMP_BLOCKTIME=1
INFO - LD_PRELOAD=/home/devcloud/.conda/envs/py39/lib/libiomp5.so:/home/devcloud/.conda/envs/py39/lib/libtcmalloc.so
INFO - numactl -C 0-31 -m 0 /home/devcloud/.conda/envs/py39/bin/python -u 01_train.py configs/ben/v10_xeon4_baseline_ben.json --fold=0
在训练期间,我确保我的总损失函数正在减少(即模型正在收敛到解决方案)。
推理
训练模型后,我们可以开始仅从卫星图像进行预测。在eval.py推理脚本中,将import intel_extension_for_pytorch as ipex添加到导入语句中。加载PyTorch模型后,使用Intel Extension for PyTorch优化模型以进行BF16推理
model = torch.load(os.path.join(path_model_weights,
'fold{}_best.pth'.format(fold)),
map_location = lambda storage,
loc: storage)
model.eval()
model = ipex.optimize(model, dtype = torch.bfloat16)
在运行预测之前,添加两行用于混合精度
with torch.no_grad():
with torch.cpu.amp.autocast():
for data in pbar:
samples = torch.autograd.Variable(data['image'], volatile=True)
predicted = predict(model, samples, flips=self.flips)
要运行推理,我们可以使用02_eval.py脚本。现在我们有了一个训练好的模型,我们可以在卫星图像上进行预测(图4)。我们可以看到它似乎将道路紧密地映射到图像上!

图4。莫斯科卫星图像和相应的道路预测(作者供图)
我意识到我训练的模型对莫斯科图像数据过度拟合,可能无法很好地推广到其他城市。然而,此挑战的获胜解决方案使用了来自六个城市(拉斯维加斯、巴黎、上海、喀土穆、莫斯科、孟买)的数据,并在新城市中表现良好。未来,值得测试的一件事是在所有六个城市上进行训练,并在另一个城市上运行推理以重现他们的结果。
关于后处理的说明
还可以执行进一步的后处理步骤,将掩膜作为图形特征添加到地图中。您可以在此处阅读有关后处理步骤的更多信息
SpaceNet 5 基线 — 第三部分:从卫星图像中提取道路速度向量
结论
总而言之,我们:
- 创建了1,352张图像训练掩膜(带有限速),以对应我们的训练卫星图像数据(来自.geojson文本文件标签)
- 定义了用于训练和推理的配置文件
- 将数据分为训练集和验证集
- 优化了CPU训练代码,包括使用Intel Extension for PyTorch和BF16
- 在第四代英特尔至强CPU上训练了一个高性能的ResNet34 + UNet模型
- 运行了初始推理以查看限速掩膜的预测
后续步骤
通过使用Intel Extension for PyTorch来扩展英特尔CPU上的优化
pip install intel-extension-for-pytorch
git clone https://github.com/intel/intel-extension-for-pytorch
如果您有任何其他问题,请在LinkedIn上联系我!
有关Intel Extension for PyTorch的更多信息可在此处找到。
获取软件
我鼓励您查看英特尔的其他AI工具和框架优化,并了解基于开放标准的多架构、多供应商编程模型oneAPI,它构成了英特尔AI软件组合的基础。
有关第四代英特尔至强可扩展处理器的更多详细信息,请访问AI平台,您可以在其中了解英特尔如何赋能开发者运行高性能、高效的端到端AI管道。