故事梗概
- 尽管 PyTorch* Inductor C++/OpenMP* 后端已使用户能够利用现代 CPU 架构和并行处理,但它一直缺乏优化,导致该后端在端到端性能方面不如 eager 模式。
- 英特尔采用混合策略优化了 Inductor 后端,将操作分为两类:Conv/GEMM 和非 Conv/GEMM 元素级及归约操作。
- 对于流行的深度学习模型,与 eager 模式相比,这种混合策略展示了有希望的性能提升,并提高了 C++/OpenMP 后端对 PyTorch 模型的效率和可靠性。
Inductor 后端面临的挑战
PyTorch Inductor C++/OpenMP 后端使用户能够利用现代 CPU 架构和并行处理来加速计算。
然而,在其开发的早期阶段,该后端缺乏一些优化,这阻碍了它充分利用 CPU 的计算能力。结果是,对于大多数模型,C++/OpenMP 后端在端到端性能方面不如 eager 模式,其中 45% 的 TorchBench、100% 的 Hugging Face 和 75% 的 TIMM 模型表现不如 eager 模式。
在这篇文章中,我们将重点介绍英特尔对 Inductor CPU 后端的优化,包括所用的技术和取得的成果。
我们通过采用混合策略对后端进行了优化,该策略将操作分为两类:Conv/GEMM 和非 Conv/GEMM 元素级及归约操作。利用 oneDNN 性能库进行后处理融合和权重预打包来优化前者,而使用 C++ 代码生成中的显式向量化来优化后者。
这种混合策略与 eager 模式相比,展示了有希望的性能提升,尤其是在流行的深度学习模型上,例如 Inductor Hugging Face、Inductor TorchBench 和 Inductor TIMM。总体而言,英特尔的优化提高了 C++/OpenMP 后端对 PyTorch 模型的效率和可靠性。
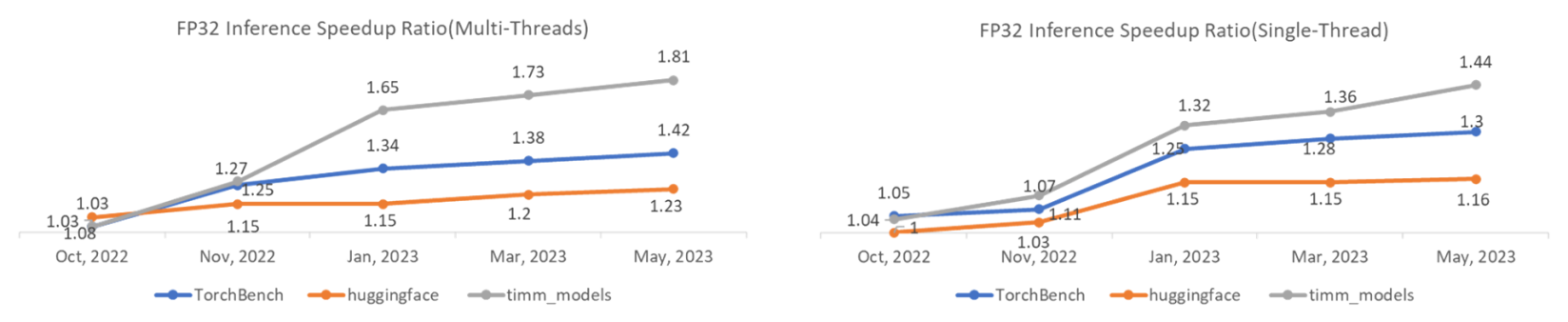
图 1:性能加速比趋势
英特尔混合优化的性能状态
与采用混合优化的 eager 模式相比,C++/OpenMP 后端显示出有希望的性能改进。我们测量了三个 Inductor 基准套件——TorchBench、Hugging Face 和 TIMM 的性能,结果如下。(注意:我们每周两次在 GitHub 上发布性能数据。)
总体而言,这些优化有助于确保 C++/OpenMP 后端为 PyTorch 模型提供高效可靠的支持。
通过率
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 93%, 56/60 | 96%, 44/46 | 100%, 61/61 |
+----------+------------+-------------+-------------+
几何平均加速(单插槽多线程)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.39x | 1.20x | 1.73x |
+----------+------------+-------------+-------------+
单个模型性能
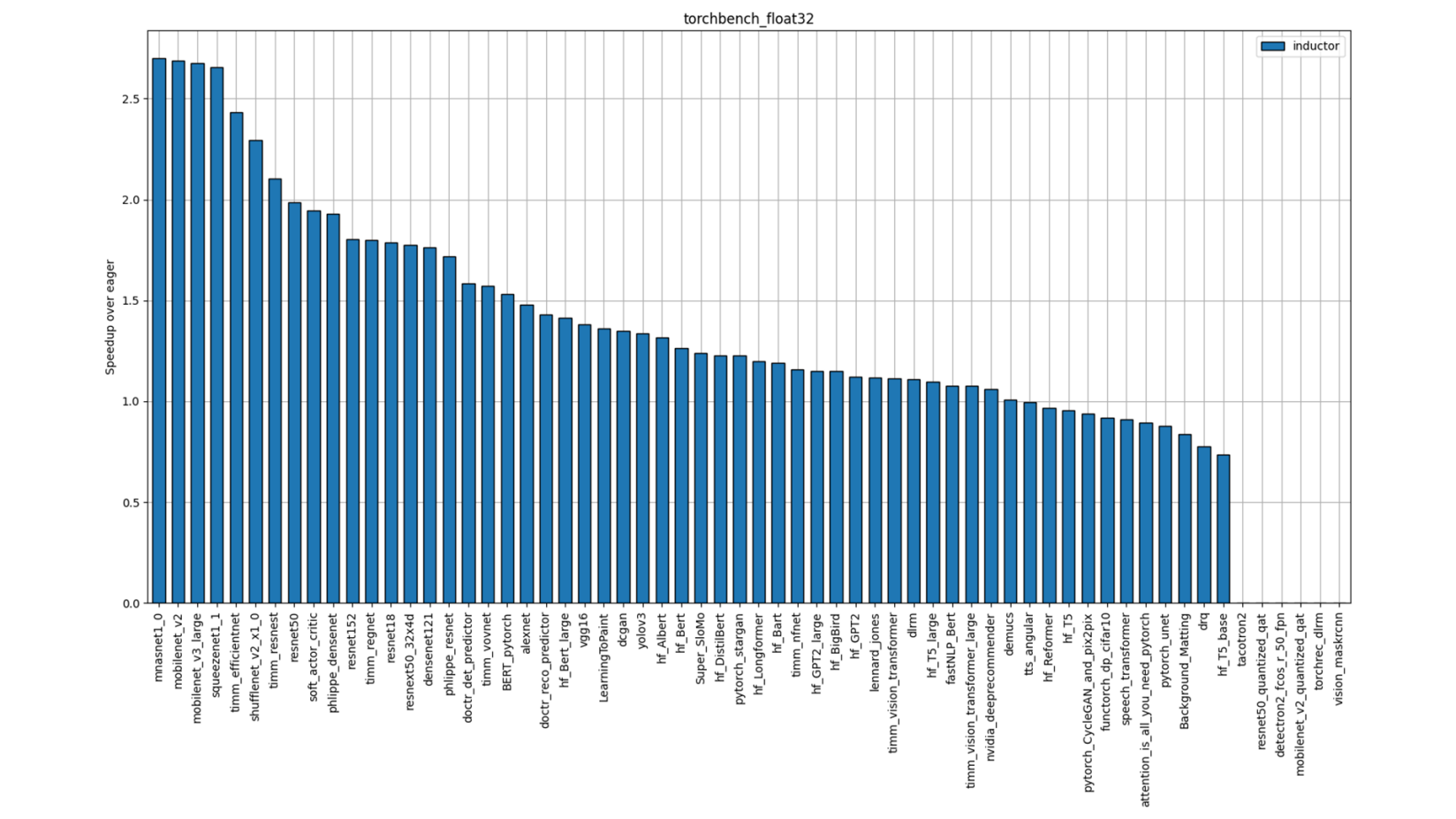
图 2:TorchBench FP32 性能(单插槽多线程)
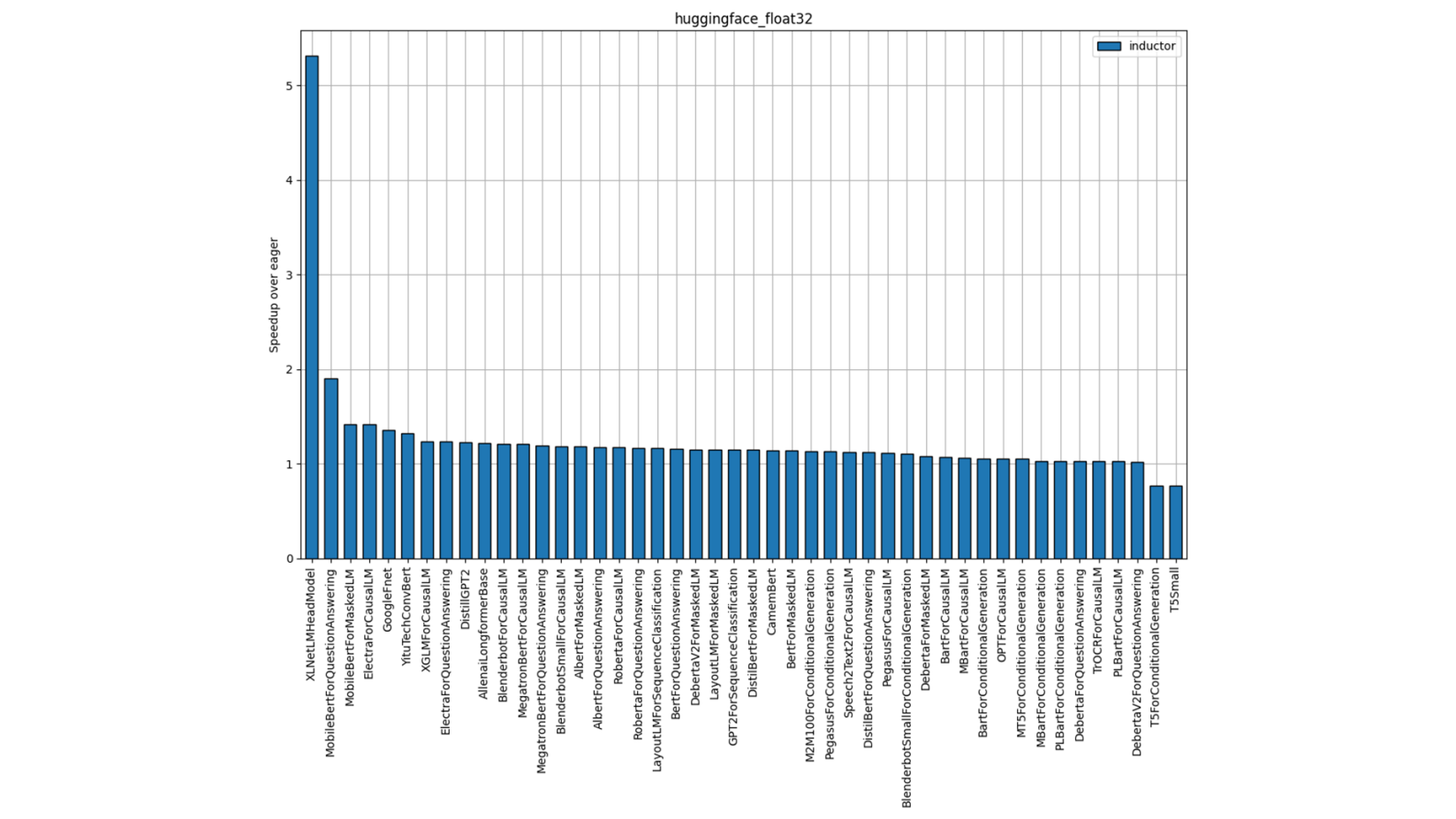
图 3:Hugging Face FP32 性能(单插槽多线程)
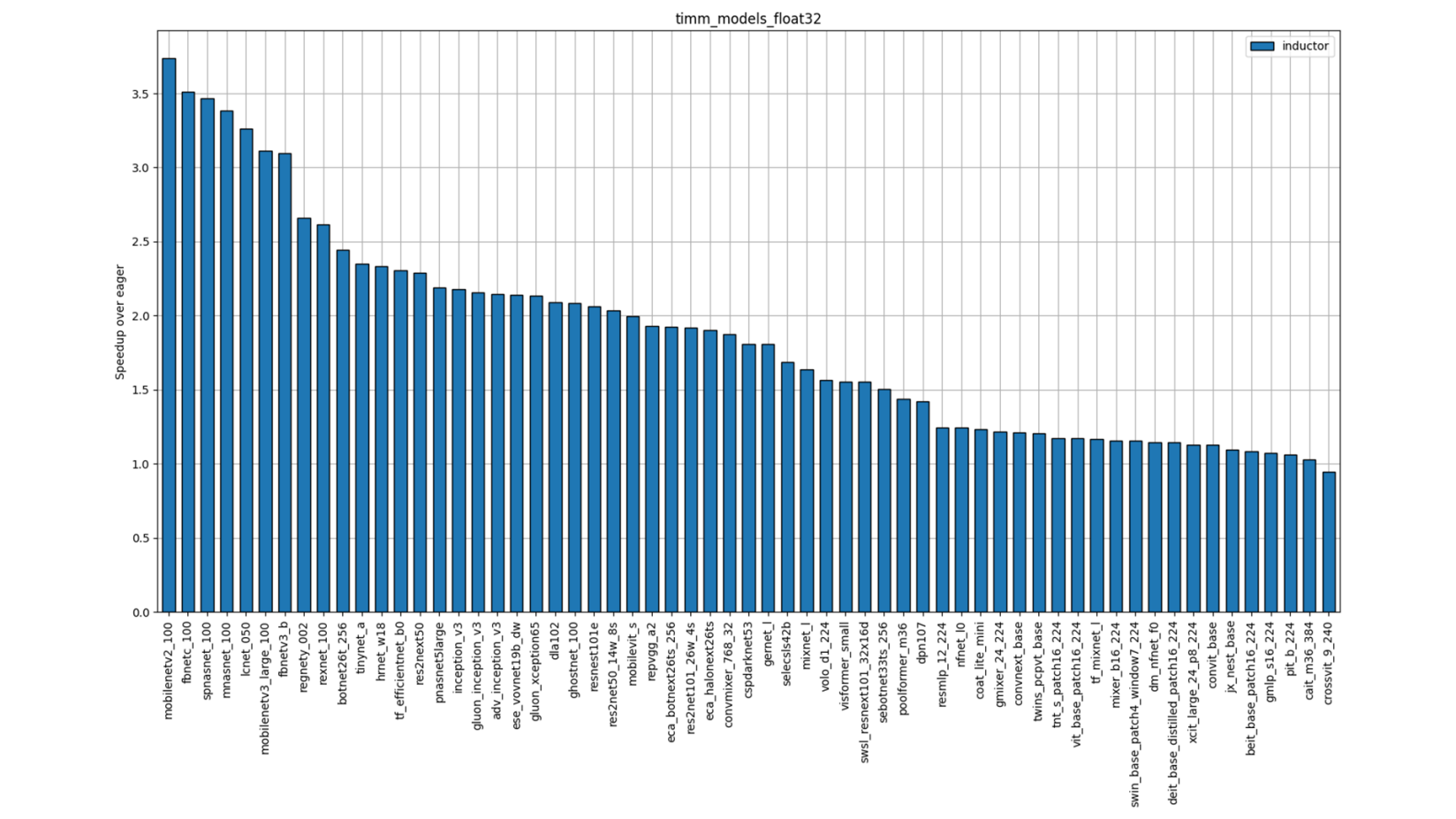
图 4:TIMM FP32 性能(单插槽多线程)
几何平均加速(单核单线程)
+----------+------------+-------------+-------------+
| Compiler | torchbench | huggingface | timm_models |
+----------+------------+-------------+-------------+
| inductor | 1.29x | 1.15x | 1.37x |
+----------+------------+-------------+-------------+
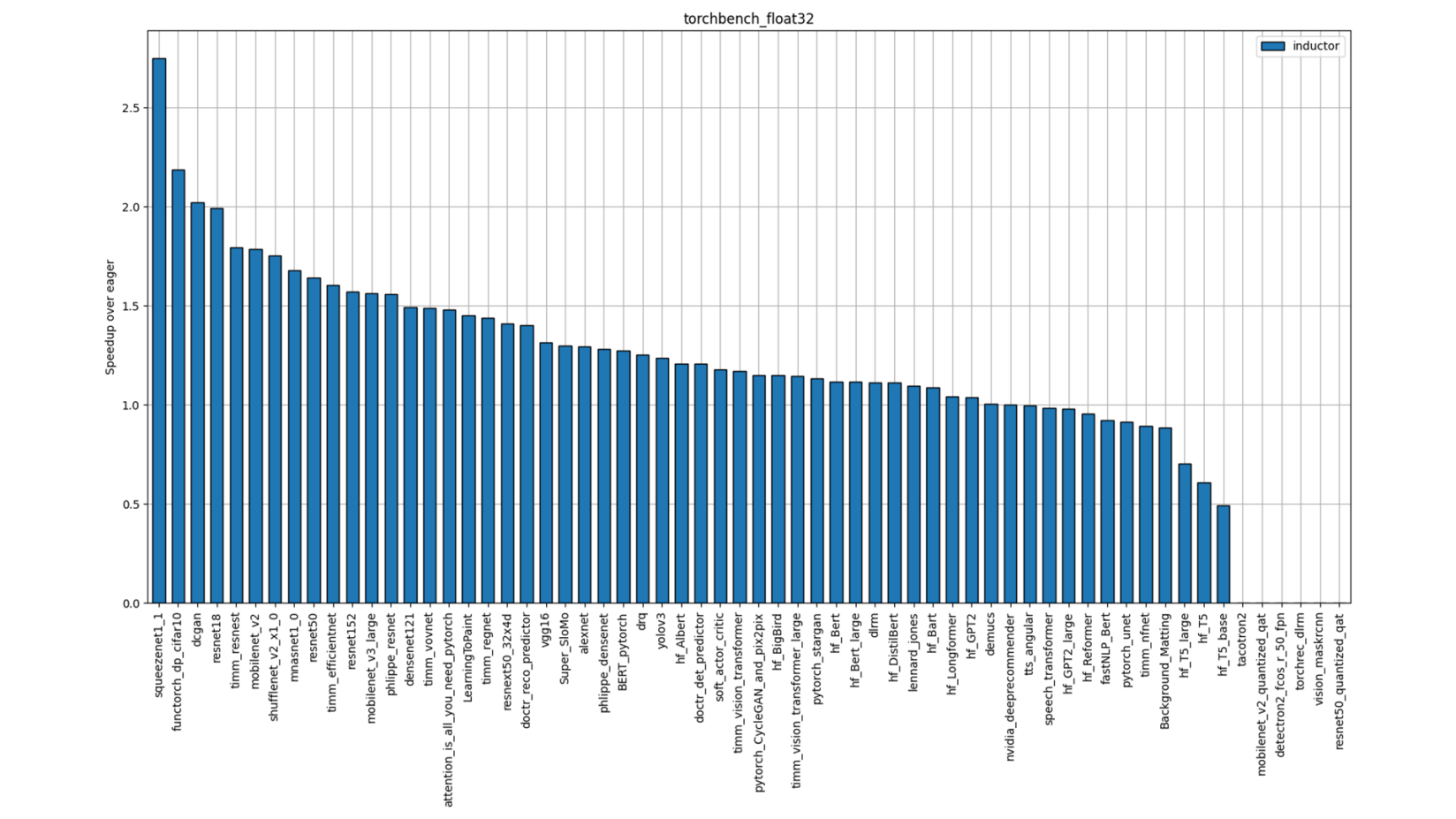
图 5:TorchBench FP32 性能(单插槽单线程)
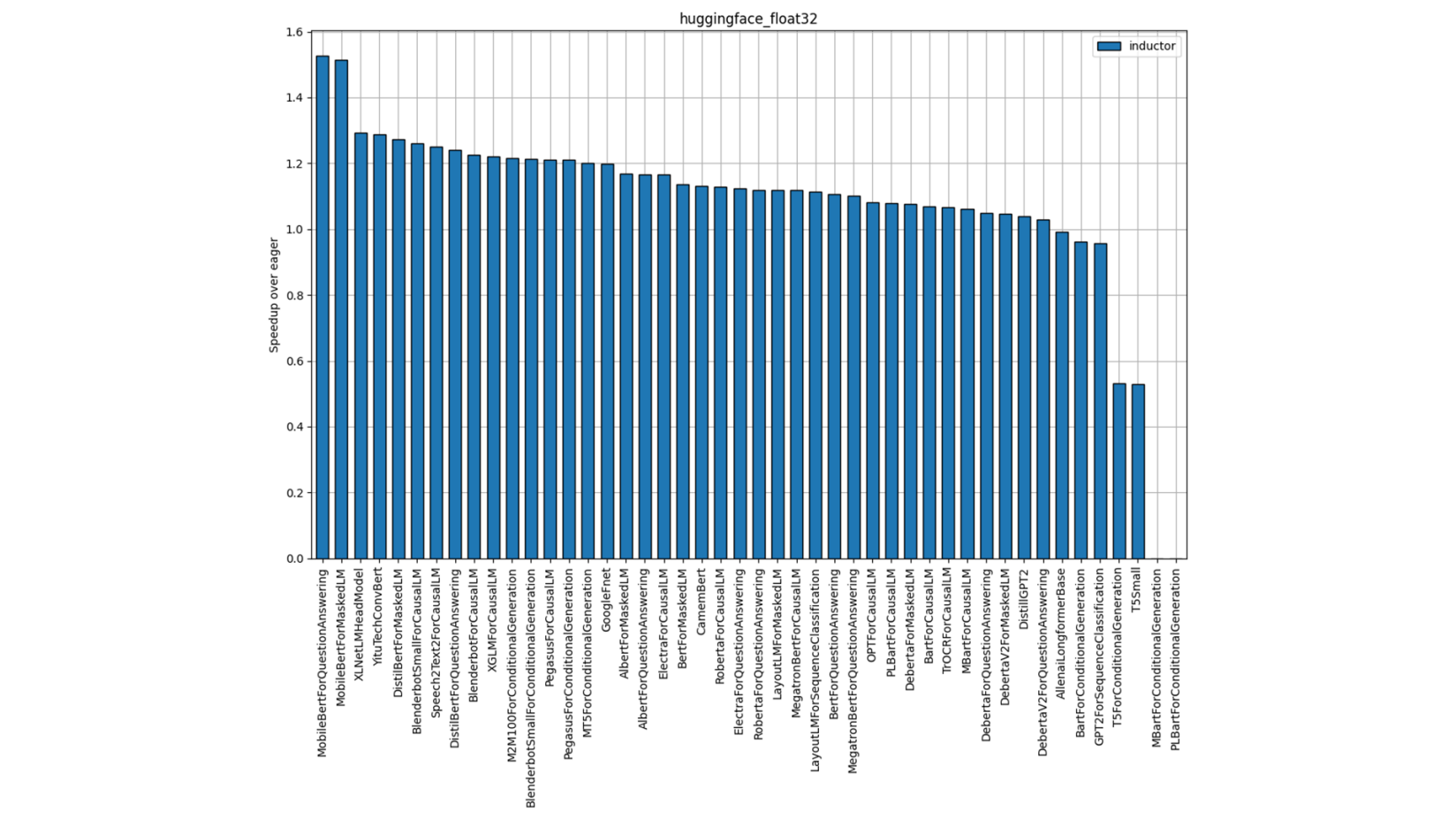
图 6:Hugging Face FP32 性能(单插槽单线程)
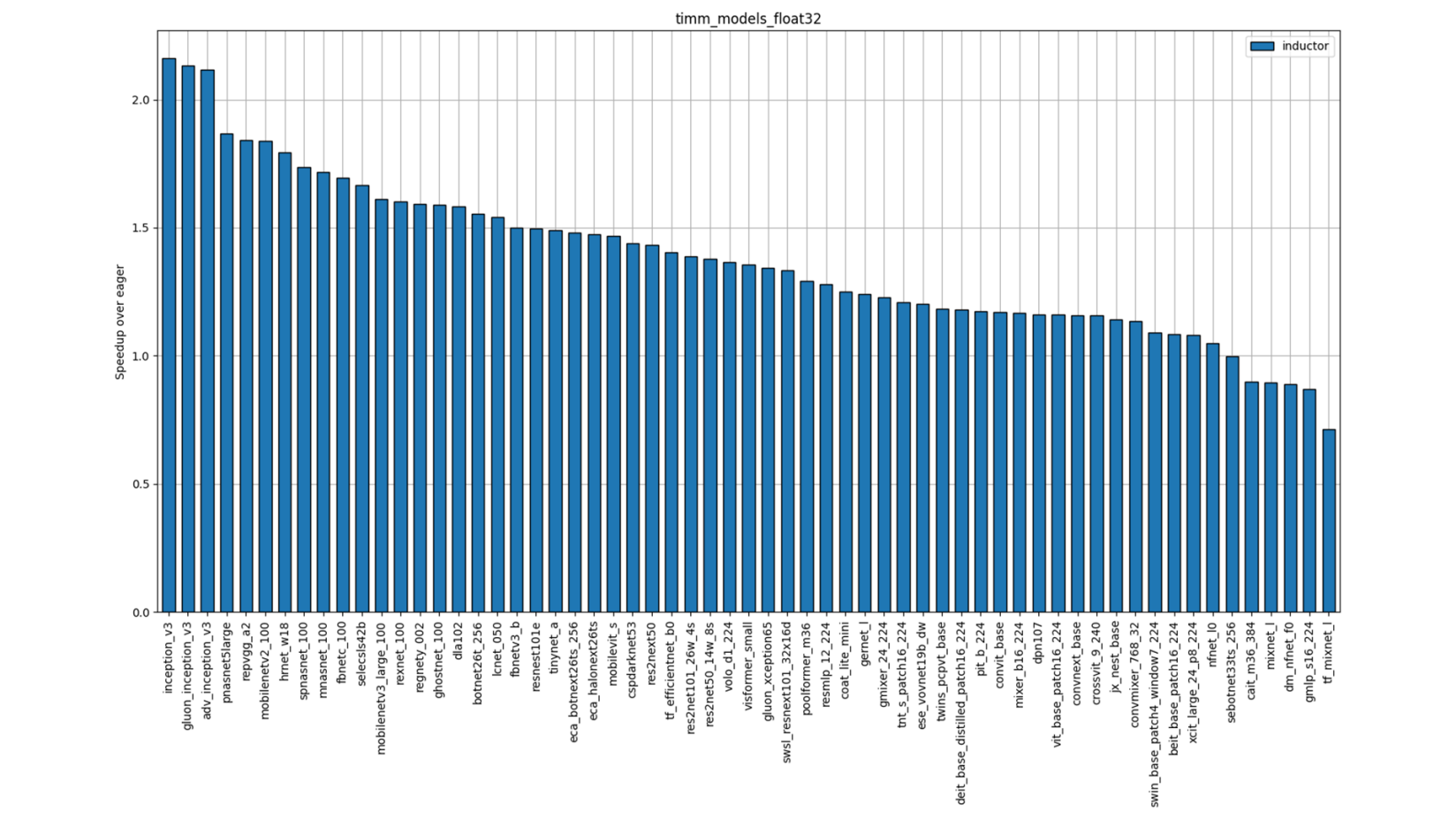
图 7:TIMM FP32 性能(单插槽单线程)
技术深入探讨
现在,让我们仔细看看 Inductor C++/OpenMP 后端中使用的两个主要优化:
- 通过 oneDNN 库进行权重预打包和后操作融合
- Inductor C++ 代码生成中的显式向量化
通过 oneDNN 进行权重预打包和后处理融合
oneDNN 库是 Intel® oneAPI 深度神经网络库的简称,它提供了一系列后处理融合(即,将卷积和矩阵乘法与其连续操作融合),这可以使流行模型受益。 Intel® Extension for PyTorch 已经实现了这些融合中的大部分,并取得了显著的性能提升。因此,我们将英特尔 PyTorch 扩展中应用的所有这些融合都上游到 Inductor,从而使更广泛的模型能够受益于这些优化。我们已将这些融合定义为 mkldnn 命名空间下的操作符。这允许 Python 模块直接调用这些 mkldnn 操作。
目前,已定义的融合操作如下。您可以在 RegisterMkldnnOpContextClass.cpp 中找到这些已定义的融合操作。
_linear_pointwise:融合线性及其后置一元元素级操作_linear_pointwise.binary:融合线性及其后置二元元素级操作_convolution_pointwise:融合卷积及其后置一元元素级操作_convolution_pointwise.binary:融合卷积及其后置二元元素级操作
详细的融合模式在 mkldnn.py 文件中定义:convolution/linear + sigmoid/hardsigmoid/tanh/hardtanh/hardswish/leaky_relu/gelu/relu/relu6/siluconvolution/linear + add/add_/iadd/sub/sub_
在 Inductor 方面,我们将这些融合应用于已降级的 FX 图。我们已将 mkldnn_fuse_fx 定义为应用所有融合的入口点。代码片段如下所示:
def mkldnn_fuse_fx(gm: torch.fx.GraphModule, example_inputs):
...
gm = fuse_unary(gm)
gm = fuse_binary(gm)
...
if config.cpp.weight_prepack:
gm = pack_module(gm)
return gm
在 mkldnn_fuse_fx 函数中,我们对尚未降级的 FX 图应用融合。为了融合卷积/线性及其连续的元素级操作,我们调用 fuse_unary 和 fuse_binary,如下所示:
gm = fuse_unary(gm)
gm = fuse_binary(gm)
除了后操作融合之外,我们还应用了权重预打包以进一步提高 Conv/GEMM 性能。
gm = pack_module(gm)
权重预打包涉及以块状布局重新排列权重张量,这
- 与 NCHW 或 NHWC 等简单格式相比,可以改善向量化和缓存重用;
- 有助于避免运行时权重重新排序,从而减少开销并提高性能;
- 权衡是增加了内存使用。
由于这些原因,我们在 Inductor 中提供了 config.cpp.weight_prepack 标志,为用户提供更多控制此优化,允许他们根据特定需求启用它。
Inductor C++ 代码生成中的显式向量化
向量化是一种关键的优化技术,可以显著提高数值计算的性能。通过利用 SIMD(单指令多数据)指令,向量化可以在单个处理器核心上同时执行多个计算,从而带来显著的性能提升。
在 Inductor C++/OpenMP 后端,我们利用 aten 向量化库来促进实现,使用 Intel® AVX2 和 Intel® AVX-512 ISA(指令集架构)选项进行向量化。Aten 向量化支持多个平台,包括 x86 和 Arm,以及多种数据类型。通过添加更多 VecISA 子类,可以轻松扩展以支持其他 ISA。这使得 Inductor 能够在未来轻松支持其他平台和数据类型。
由于平台差异,Inductor 的 C++/OpenMP 后端在代码生成开始时会首先检测 CPU 功能以确定向量化位宽。默认情况下,如果机器同时支持 AVX-512 和 AVX2,后端将选择 512 位向量化。
如果硬件支持向量化,C++/OpenMP 后端首先检测循环体是否可以向量化。主要有三种情况我们无法生成向量化内核:
- 循环体缺少向量内部函数支持,例如
rand和atomic_add。 - 循环体缺少高效的向量内部函数支持,例如非连续的
load/store。 - 尚未支持向量化但正在开发中的数据类型,例如整数、双精度浮点数、半精度浮点数和 bfloat16。
为了解决这个问题,C++/OpenMP 后端使用 CppVecKernelChecker 来检测特定循环体中的所有操作是否都可以向量化。通常,我们通过识别操作是否依赖于上下文将其分为两类。
对于大多数元素级操作,例如 add、sub、relu,向量化是直接的,它们的执行不依赖于上下文。
然而,对于某些其他操作,它们的语义更复杂,并且它们的执行通过静态分析依赖于上下文。
例如,让我们考虑 where 操作,它接受 mask、true_value 和 false_value,其中 mask 值从 uint8 张量加载。fx 图可以如下所示:
graph():
%ops : [#users=9] = placeholder[target=ops]
%get_index : [#users=1] = call_module[target=get_index](args = (index0,), kwargs = {})
%load : [#users=1] = call_method[target=load](args = (%ops, arg1_1, %get_index), kwargs = {})
%to_dtype : [#users=1] = call_method[target=to_dtype](args = (%ops, %load, torch.bool), kwargs = {})
...
%where : [#users=1] = call_method[target=where](args = (%ops, %to_dtype, %to_dtype_2, %to_dtype_3), kwargs = {})
关于 uint8,它是一种通用数据类型,可以用于计算,但不仅限于用作掩码的布尔值。因此,我们需要静态分析其上下文。特别是,CppVecKernelChecker 将检查 uint8 张量是否仅由 to_dtype 使用,以及 to_dtype 是否仅由 where 使用。如果满足,则可以向量化。否则,它将回退到标量版本。生成的代码可能如下所示:
标量版本
auto tmp0 = in_ptr0[i1 + (17*i0)];
auto tmp3 = in_ptr1[i1 + (17*i0)];
auto tmp1 = static_cast<bool>(tmp0);
auto tmp2 = static_cast<float>(-33.0);
auto tmp4 = tmp1 ? tmp2 : tmp3;
tmp5 = std::max(tmp5, tmp4);
向量化版本
float g_tmp_buffer_in_ptr0[16] = {0};
// Convert the flag to float for vectorization.
flag_to_float(in_ptr0 + (16*i1) + (17*i0), g_tmp_buffer_in_ptr0, 16);
auto tmp0 = at::vec::Vectorized<float>::loadu(g_tmp_buffer_in_ptr0);
auto tmp3 = at::vec::Vectorized<float>::loadu(in_ptr1 + (16*i1) + (17*i0));
auto tmp1 = (tmp0);
auto tmp2 = at::vec::Vectorized<float>(static_cast<float>(-33.0));
auto tmp4 = decltype(tmp2)::blendv(tmp3, tmp2, tmp1);
除了上下文分析之外,C++/OpenMP 后端还包含了其他几个与向量化相关的优化。这些包括:
- 用于支持转置加载的分块内核实现 – cpp.py
- 基于值范围的数据类型降级 – cpp.py
- 将 sleef 实现替换为 oneDNN/oneMKL 实现以优化 aten 向量化 – #94577、#92289、#91613
总而言之,我们研究了 Inductor C++ 后端在 FP32 训练和推理中的向量化优化,针对 150 个基准模型,其中 90% 的推理内核和 71% 的训练内核被向量化。
在推理方面,总共生成了 28,185 个 CPP 内核,其中 25,579 个(90%)被向量化,其余 10% 为标量。至于训练,生成了 103,084 个内核,其中 73,909 个(71%)被向量化,29% 未被向量化。
结果表明,推理内核的向量化令人印象深刻(由于我们刚开始进行训练方面的工作,训练内核仍有改进空间)。其余未向量化内核按不同类别进行分析,突出了提高向量化覆盖率的下一步措施:索引相关操作、int64 支持、垂直归约、带回退的向量化等等。
此外,我们还通过缓冲区复用和 CppWrapper 等其他优化对 C++/OpenMP 后端进行了优化。
未来工作
下一步,我们将继续优化 C++/OpenMP 后端,并将其扩展以支持更多数据类型。这包括:
- 提高向量化覆盖率
- 支持并优化低精度内核,包括 BF16、FP16、量化
- 训练优化
- 循环平铺
- 自动调优
- 进一步融合 Conv/GEMM 内核的优化。
- 探索替代代码生成路径:clang/llvm/triton
总结
Inductor C++/OpenMP 后端是一个灵活高效的 CPU 后端。本博客描述了 Inductor C++/OpenMP 后端在 TorchBench、Hugging Face 和 TIMM 三个基准套件的推理和训练中使用的优化。
主要优化包括通过 oneDNN 库进行权重预打包和后操作融合,以及在 Inductor C++ 代码生成中使用 AVX2 和 AVX-512 指令进行显式向量化。
结果显示,90% 的推理内核和 71% 的训练内核被向量化,这表明推理的向量化令人印象深刻,而训练仍有改进空间。此外,我们还应用了缓冲区复用和 CppWrapper 等其他优化。我们将持续关注上述未来工作,以进一步提高性能。
致谢
本博客文章中展示的结果是 Intel PyTorch 团队与 Meta 协作努力的结晶。我们衷心感谢 @jansel、@desertfire 和 @Chillee 在整个开发过程中提供的宝贵贡献和坚定支持。他们的专业知识和奉献精神对实现此处讨论的优化和性能改进至关重要。
配置详情
硬件详情
| 项目 | 值 |
| 制造商 | 亚马逊 EC2 |
| 产品名称 | c6i.16xlarge |
| CPU 型号 | 英特尔(R) 至强(R) 铂金 8375C CPU @ 2.90GHz |
| 已安装内存 | 128GB (1x128GB DDR4 3200 MT/s [未知]) |
| 操作系统 | Ubuntu 22.04.2 LTS |
| 内核 | 5.19.0-1022-aws |
| 微码 | 0xd000389 |
| GCC | gcc (Ubuntu 11.3.0-1ubuntu1~22.04) 11.3.0 |
| GLIBC | ldd (Ubuntu GLIBC 2.35-0ubuntu3.1) 2.35 |
| Binutils | GNU ld (GNU Binutils for Ubuntu) 2.38 |
| Python | Python 3.10.6 |
| OpenSSL | OpenSSL 3.0.2 2022年3月15日 (库: OpenSSL 3.0.2 2022年3月15日) |
软件详情
| 软件 | 每晚提交 | 主提交 |
| Pytorch | a977a12 | 0b1b063 |
| Torchbench | / | a0848e19 |
| torchaudio | 0a652f5 | d5b2996 |
| torchtext | c4ad5dd | 79100a6 |
| torchvision | f2009ab | b78d98b |
| torchdata | 5cb3e6d | f2bfd3d |
| dynamo_benchmarks | fea73cb | / |
配置
- 英特尔 OpenMP
- Jemalloc – oversize_threshold:1,background_thread:true,metadata_thp:auto,dirty_decay_ms:-1,muzzy_decay_ms:-1
- 单插槽多线程:实例数:1;每个实例核心数:32
- 单核单线程:实例数:1;每个实例核心数:1