今天是 PyTorch 公开发布一周年。这是一段疯狂的旅程——我们致力于构建一个灵活的深度学习研究平台。在过去的一年里,我们看到了一个由使用、贡献和推广 PyTorch 的人组成的惊人社区——感谢你们的厚爱。
回首过去,我们想总结一下 PyTorch 过去一年的情况:进展、新闻以及社区的亮点。
社区
我们很幸运地拥有一个由研究人员和工程师组成的强大而自然的社区,他们都爱上了 PyTorch。核心团队由来自多个国家、公司和大学的工程师和研究人员组成,没有每个人的贡献,PyTorch 不可能达到今天的成就。
研究论文、软件包和 GitHub
发布几天之内,社区用户就开始用 PyTorch 实现他们最喜欢的研究论文,并将代码发布到 GitHub 上。开源代码是当今研究人员的主要和基本工具。
大家齐心协力创建了 torchtext、torchvision 和 torchaudio 软件包,以帮助促进和普及不同领域的研究。
第一个基于 PyTorch 的社区软件包来自 Brandon Amos,名为 Block,它有助于更轻松地操作块矩阵。随后,CMU 的 Locus Lab 发布了 PyTorch 软件包以及他们大部分研究的实现。第一篇研究论文代码来自 Sergey Zagoruyko,标题是 Paying more attention to attention。
来自 U.C.Berkeley 的 Jun-Yan Zhu、Taesung Park、Phillip Isola、Alyosha Efros 和团队发布了广受欢迎的 Cycle-GAN 和 pix2pix,它们实现了图像到图像的转换。

HarvardNLP 和 Systran 的研究人员在 Facebook 的 Adam Lerer 最初重新实现 [Lua]Torch 代码的基础上,开始开发和改进 PyTorch 中的 OpenNMT。
Twitter 的 MagicPony 团队早期将其 超分辨率工作的实现贡献到了 PyTorch 的示例中。
Salesforce Research 发布了多个软件包,其中包括他们的亮点发布 PyTorch-QRNN,这是一种 RNN,比 CuDNN 优化的标准 LSTM 快 2 到 17 倍。James Bradbury 和团队是 PyTorch 社区中最活跃和最具吸引力的力量之一。
来自 Uber、Northeastern 和 Stanford 的研究人员齐聚一堂,围绕他们的软件包 Pyro 和 ProbTorch 形成了活跃的概率编程社区。他们正在积极开发 torch.distributions 核心软件包。这个社区非常活跃且发展迅速,我们在 NIPS 2017 举办了第一次 pytorch-probabilistic-programming 聚会,Fritz Obermeyer、Noah Goodman、Jan-Willem van de Meent、Brooks Paige、Dustin Tran 和其他 22 位与会者讨论了如何使世界变得贝叶斯。

NVIDIA 研究人员发布了三个高质量的代码库,实现了 pix2pix-HD、情感神经元 和 FlowNet2 论文。他们对 PyTorch 中不同 数据并行模型的可扩展性分析对社区很有帮助。
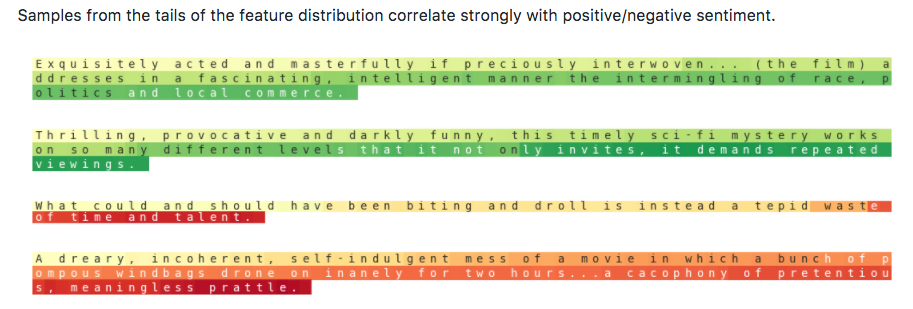
艾伦人工智能研究所发布了 AllenNLP,其中包含多个 NLP 领域的最新模型——参考实现和易于使用的 网络演示,用于标准 NLP 任务。
我们还在 7 月份迎来了第一个 Kaggle 获胜团队 grt123。他们赢得了 2017 年肺癌检测数据科学竞赛,并 随后发布了他们的 PyTorch 实现。
在可视化方面,Tzu-Wei Huang 实现了一个 TensorBoard-PyTorch 插件,Facebook AI Research 发布了他们的 visdom 可视化软件包的 PyTorch 兼容性。
最后,Facebook AI Research 发布了多个项目,例如 ParlAI、fairseq-py、VoiceLoop 和 FaderNetworks,它们实现了尖端模型并在多个领域对接了数据集。
由于篇幅所限,我们未能重点介绍无数优秀项目,您可以在 此处找到一份精选列表。
我们还要向那些积极在论坛上帮助他人的朋友们致以崇高的敬意,特别是 ptrblck、jpeg729、QuantScientist、albanD、Thomas Viehmann 和 chenyuntc。你们提供了宝贵的服务,非常感谢!
指标
从纯粹的数字来看,
- GitHub 上有 87,769 行 Python 代码 导入了 torch
- GitHub 上有 3,983 个代码库在其名称或描述中提到了 PyTorch
- PyTorch 二进制文件下载量超过 50 万次。确切地说是 651,916 次。
- 5,400 名用户在我们的论坛 discuss.pytorch.org (http://discuss.pytorch.org/) 上撰写了 21,500 篇帖子,讨论了 5,200 个主题
- 自发布之日起,Reddit 的 /r/machinelearning 板块提到了 PyTorch 131 次。同期,TensorFlow 被提及 255 次。
研究指标
PyTorch 是一个以研究为重点的框架。因此,一个值得关注的指标是 PyTorch 在机器学习研究论文中的使用情况。
- 在最近的 ICLR2018 会议投稿中,PyTorch 被提及 87 篇论文,相比之下,TensorFlow 为 228 篇,Keras 为 42 篇,Theano 和 Matlab 为 32 篇。
- arxiv.org 上框架的每月提及次数 显示 PyTorch 为 72 次,TensorFlow 为 273 次,Keras 为 100 次,Caffe 为 94 次,Theano 为 53 次。
课程、教程和书籍
当我们发布 PyTorch 时,我们有很好的 API 文档,但我们的教程仅限于几个 ipython 笔记本——有帮助,但还不够好。
Sasank Chilamkurthy 亲自负责将教程改版为如今 精美的网站。
Sean Robertson 和 Justin Johnson 编写了出色的新教程——包括 NLP 领域的教程,以及通过示例学习的教程。Yunjey Choi 编写了一个精美的教程,其中大多数模型都在 30 行或更少的代码中实现。每个新教程都以不同的学习方法帮助用户更快地找到自己的方向。
Goku Mohandas 和 Delip Rao 将他们正在创作的书籍的代码内容切换为使用 PyTorch。
我们看到不少大学机器学习课程以 PyTorch 作为主要工具进行教学,例如哈佛大学的 CS287。更进一步,为了普及学习,我们开设了三门使用 PyTorch 教学的在线课程。
- Fast.ai 的“面向程序员的深度学习”是一门广受欢迎的在线课程。9 月份,Jeremy 和 Rachel 宣布接下来的 fast.ai 课程将几乎完全基于 PyTorch。
- 与新加坡国立大学和清华大学有联系的研究员 Ritchie Ng 发布了 一门 Udemy 课程,名为“使用 PyTorch 进行实用深度学习”。
- 香港科技大学的 Sung Kim 在 YouTube 上发布了 一门面向大众的在线课程,名为:“PyTorch 从零到全”。
工程
在过去的一年里,我们实现了多项功能,全面提升了性能,并修复了大量错误。我们所做工作的完整列表可在我们的 发行说明中找到。以下是我们过去一年工作中的亮点:
高阶梯度
随着几篇实现梯度惩罚的论文发布以及正在进行的二阶梯度方法研究,这是一项必不可少且备受追捧的功能。8 月份,我们实现了一个通用的接口,可以进行 n 阶导数,并随着时间的推移增加了支持高阶梯度的函数的覆盖范围,以至于在撰写本文时,几乎所有操作都支持此功能。
分布式 PyTorch
8月,我们发布了一个小型分布式软件包,它遵循了广受欢迎的MPI-集体方法。该软件包拥有TCP、MPI、Gloo和NCCL2等多个后端,支持各种类型的CPU/GPU集体操作和用例,并集成了Infiniband和RoCE等分布式技术。分布式很难,我们在初始迭代中存在一些bug。在后续版本中,我们使软件包更加稳定并提升了性能。
更接近 NumPy
用户最大的需求之一是他们熟悉的 NumPy 功能。广播和高级索引等功能非常方便,可以为用户节省大量冗长代码。我们实现了这些功能,并开始调整我们的 API 以使其更接近 NumPy。随着时间的推移,我们希望在适当的时候越来越接近 NumPy 的 API。
稀疏张量
三月份,我们发布了一个支持稀疏张量的小型软件包;五月份,我们发布了稀疏软件包的 CUDA 支持。该软件包功能小而有限,用于实现深度学习中稀疏嵌入和常用稀疏范式。该软件包的范围仍然很小,并且有需求扩大它——如果您有兴趣扩展稀疏软件包,请在我们的 讨论区联系我们。
性能
性能始终是一场持续的战斗,特别是对于 PyTorch 这种旨在最大化灵活性的动态框架而言。在过去的一年里,我们全面提升了性能,从核心张量库到神经网络算子,全面编写了更快的微优化代码。
- 我们为张量操作添加了专门的 AVX 和 AVX2 指令
- 为常见的工作负载,如拼接和 Softmax(以及许多其他操作),编写了更快的 GPU 内核
- 重写了几个神经网络算子(太多无法一一列举)的代码,特别是 nn.Embedding 和分组卷积。
将框架开销全面降低 10 倍
由于 PyTorch 是一个动态图框架,我们在训练循环的每次迭代中都会即时创建一个新图。因此,框架开销必须很低,或者工作负载必须足够大,以至于框架开销被隐藏。8 月份,DyNet 的作者(Graham Neubig 和团队)展示了它在小型 NLP 模型上比 PyTorch 快得多。这是一个有趣的挑战,我们没有意识到正在训练如此规模的模型。经过数月(并且仍在进行中)的努力,我们着手对 PyTorch 内部进行了重大重写,将框架开销从每次算子执行的 10 微秒以上降低到低至 1 微秒。
ATen
在我们着手重新设计 PyTorch 内部时,我们构建了 ATen C++11 库,它现在为所有 PyTorch 后端提供支持。ATen 的 API 镜像了 PyTorch 的 Python API,这使其成为一个方便的 C++ 张量计算库。ATen 可以独立于 PyTorch 构建和使用。
将模型导出到生产环境 — ONNX 支持和 JIT 编译器
我们收到的常见请求之一是将 PyTorch 模型导出到另一个框架。用户在 PyTorch 中进行快速研究周期,完成之后,他们希望将其发布到只有 C++ 要求的更大项目中。
考虑到这一点,我们为 PyTorch 构建了一个追踪器——它可以将 PyTorch 模型导出到中间表示。随后的追踪可以用于更有效地运行当前的 PyTorch 模型(通过对其运行优化过程),或者转换为 ONNX 格式,以便发布到其他框架,如 Caffe2、MXNet、TensorFlow 等,或直接发布到 CoreML 或 TensorRT 等硬件加速库。在接下来的一年里,您将听到更多关于 JIT 编译器在性能改进方面的信息。
用户搞笑评论 🙂
我们的用户以有趣的方式表达了他们的支持,让我们开怀大笑,谢谢你们 🙂
PyTorch 给了我如此多的活力,我的皮肤变得清爽,成绩提高了,账单付清了,庄稼也浇灌了。— Adam Will ð️ð (@adam_will_do_it) 2017 年 5 月 26 日
我也是!但我的头发也更亮了,而且我瘦了。 @PyTorch 必胜! https://#/qgU4oIOB4K— Mariya (@thinkmariya) 2017 年 5 月 26 日