大型语言模型 (LLM) 彻底改变了我们撰写和阅读文档的方式。在过去一年左右的时间里,我们发现它们的作用远不止是文档的改写:LLM 现在可以先思考再行动,它们可以规划,可以调用浏览器等工具,可以编写代码并检查其是否有效,以及更多功能——事实上,这份清单还在迅速增长!
所有这些技能有什么共同点?答案是它们都是在 LLM 训练的后训练阶段开发的。尽管后训练解锁了我们几年前看来如同魔法般的能力,但与 Transformer 架构和预训练的基础知识相比,它受到的关注却出奇地少。
本教程最初是为 Meta 基础设施团队编写的,目标受众是希望了解更多后训练知识以贡献力量的、没有 LLM 建模专业知识的基础设施工程师。我相信这涵盖了很大一部分工程师:随着强化学习成为主流,我们需要新的基础设施才能提高生产力,因此弥合这一差距至关重要!现在我将其广泛分享,希望 PyTorch Foundation 的更多人会有相似的背景和兴趣,并且会像我们的团队一样,觉得这很有帮助。
后训练入门
后训练(有时也称为“对齐”)是现代 LLM 的一个关键组成部分,也是“教导”模型如何以人类喜欢的方式回答问题以及如何进行推理的方法。
你可能会问,为什么后训练与预训练不同?后训练是为了让模型能够与用户进行对话,而对话遵循一系列基本规则,例如:
- 在对话中,不止一位说话者,他们轮流发言
- 在发言前,你应该倾听,才能说出相关内容
我们认为这些是显而易见的,但预训练只是在进行下一个词预测,以让模型了解世界,因此其中的数据是完全非结构化的,模型从未学习过这些基本规则。事实上,经过预训练的模型通常不擅长理解它应该在一段时间后停止说话,会像 Google 自动完成框一样喋喋不休。
此外,对模型施加一些绝对优先于其他一切的基本规则也很有用。这通过系统提示(和/或通过有监督微调(SFT)/奖励塑造,详见后文)在后训练中完成。
后训练数据格式
与这些模型聊天需要一些幕后底层连接。每次你在聊天窗口中与 ChatGPT 等服务交谈时,都会看到这样的用户界面:
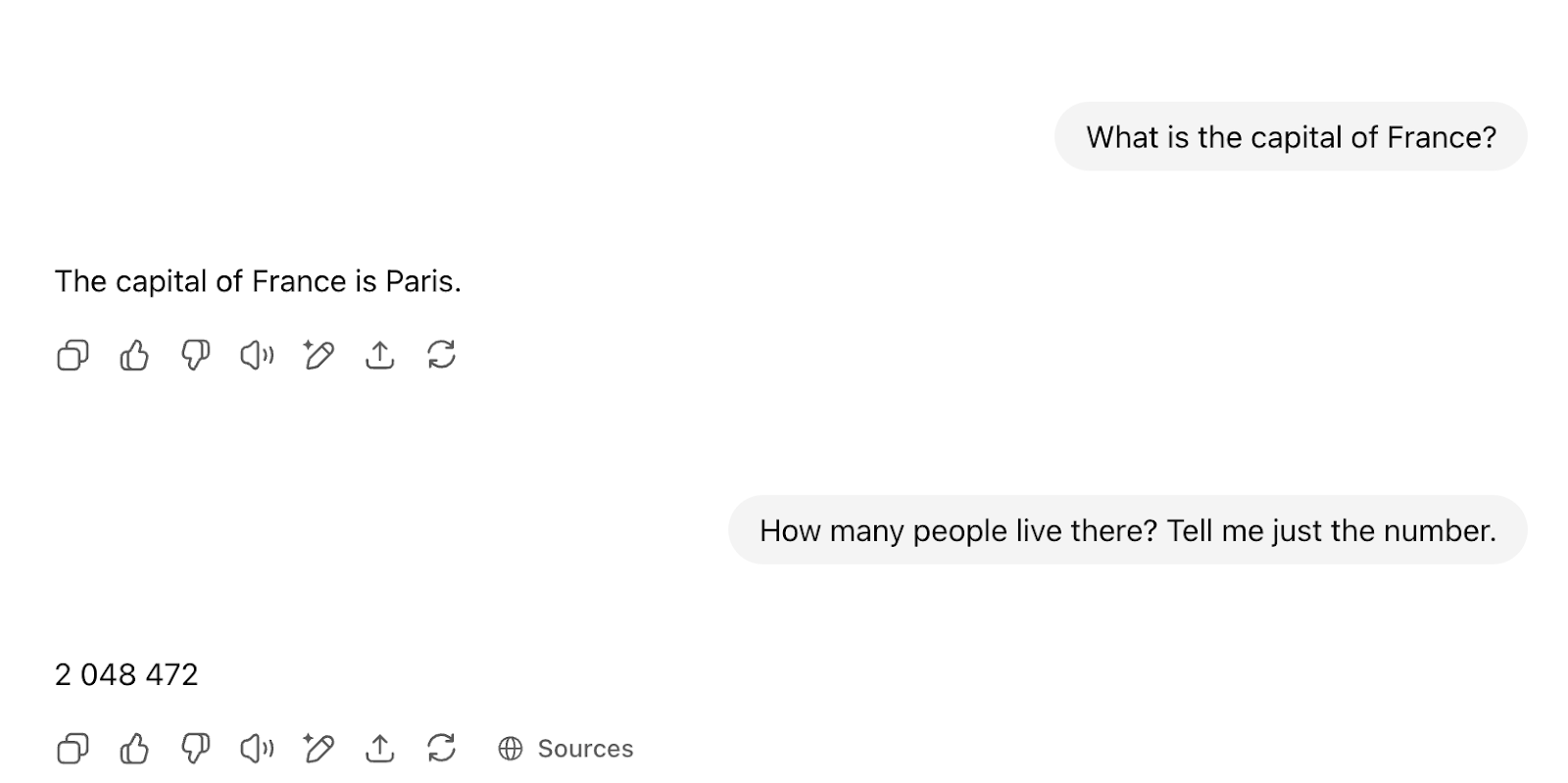
实际发生的情况是,后训练结构已经为你连接好,模型将看到类似以下内容(使用Llama 3的数据格式):
<|begin_of_text|> <|start_header_id|>system<|end_header_id|> … <|eot_id|> <|start_header_id|>user<|end_header_id|> What is the capital of France?<|eot_id|> <|start_header_id|>assistant<|end_header_id|> The capital of France is Paris <|start_header_id|>user<|end_header_id|> How many people live there? Tell me just the number<|eot_id|> <|start_header_id|>assistant<|end_header_id|> START FILLING FROM HERE
请注意,LLM 的基本接口未改变:你提供一些文本,它将无限地继续下去。
这种巧妙的底层连接确保模型收到所有元数据,知道之前的说话者已经说过话(它不应该模仿他们!!),并在助手说完话后停止。同样,模型会愉快地继续填充,但当我们看到<eot_id>令牌(“回合结束”)时,我们会阻止模型继续,并将其返回给用户。
请注意,模型不会做任何这些事情:尽管我们觉得它们很聪明,但它们仍然只是需要这种“手把手指导”的文本填充器。
这种格式有点难读,但你基本上可以将其概念化为类似以下内容:
<system> You are a helpful assistant bla bla </system> <user> What's the weather in Paris? </user> <assistant> ANSWER HERE
趣闻:模型会愉快地扮演任何一个角色!你完全可以扮演助手,让它扮演用户,只需向其提供正确的文本结构——模型无论你提供什么,都会简单地接管并完成文本。尝试使用本地模型或 API 进行操作(ChatGPT 等产品会为你处理这些底层连接,你无法覆盖它们)。显然,模型对其自己的格式非常敏感,因此请确保使用正确的格式。
后训练技术
后训练是一个快速变化的领域,不同的团队将采用不同的技术。
让我们看一下OLMo 2论文中描述的这个流程:

以下部分将逐一介绍每个方框。
SFT:有监督微调
SFT 的重点是模仿。其概念很简单:你教模型一步一步地强制学习一个答案。
如果这是下棋,你可以通过训练马格努斯·卡尔森的棋局来进行 SFT,你将强制教导模型在每一步都遵循马格努斯的下法。你可以看到 SFT 的局限性:你可以达到马格努斯的能力,但他将是你的上限,你无法超越他(与强化学习(RL)不同,强化学习可以不断尝试直到你变得非常出色,详见后文)。
在 LLM 的情况下,你逐字逐句地学习理想答案,因此你的损失函数就是针对输出层的交叉熵,其中理想的“类别”是“正确”单词的 ID。我们常被问到的一个问题是:这和预训练不是一样的吗?它确实非常相似,只有一个关键区别:你只基于提示进行条件训练;你不会学习提示。为什么?因为你想要学习如何回答这个问题,而不是学习问题本身。
记住:与预训练不同,在后训练中,我们有这种包含系统提示和用户提示的结构(参见上面后训练数据格式)。这些是输入中我们希望作为条件但不想从中学习的部分。我们通过馈入整个序列(包括系统提示、用户提示以及任何特殊字符)而不进行任何掩码来完成此操作,但当我们计算损失时,我们会掩码除实际响应之外的每个标记的损失。我们不会掩码输入中的提示,因为我们确实希望它对输入条件产生贡献。我们在反向传播步骤中掩码它,以防止它对损失产生贡献)。
它们非常相似,以至于在实践中,SFT 可以利用预训练已经构建的所有基础设施:事实上,像 Megatron 这样的训练平台使用与预训练步骤相同的数据加载器和训练器类,只需设置一个参数来掩码提示上的损失。
话虽如此,这些的规模远不及预训练——你最多只能进行几百万个样本的 SFT,所以只有几 B 个 token,而预训练会处理数万亿个 token。
谁来写回复?
SFT 逐字逐句地学习,这在两个重要方面限制了它:
- 你的上限由编写答案的人决定(见上一段)
- 关键在于,你严重依赖数据质量。实际上,你的上限最终由你最差的答案而不是最好的答案决定。当你从人们那里获取答案时,你不能指望所有答案都具有相同的高质量。其中一些不会很出色,它们会对模型质量产生巨大影响。
那么,我们该怎么办?我们无法对抗人性,所以想法是让 LLM 生成它将用来训练自己的回答。这乍一看似乎不合常理,但这种想法被称为拒绝采样(更多信息请参见Llama 2 论文)。它之所以有效,是因为我们不只生成一个答案(那样它就不会自我提升),而是生成许多(通常是 10 个)答案,这些答案来自多个不同的检查点、随机种子、系统提示等,以激发多样性。然后,我们保留最佳答案(由流程排名,通常包括人类偏好奖励模型等其他模型),并将其添加到数据库中。如果你有机器学习(ML)背景,你可以将这种方法视为一种从某种程度上讲,从某种程度上讲,从集成模型中提炼出单个模型的方法(我知道这很笼统!)。
你可以通过多次迭代来循环执行此操作。如果操作得当,你可以攀登高峰,变得越来越好。
强化学习入门
强化学习(RL)是一个广阔的领域,其中包含了著名的人类反馈强化学习(RLHF),但它并不仅限于此。
总的来说,RL 背后的核心思想是你现在是一个代理,可以针对环境采取行动,并观察发生的事情,并从中获得奖励。你可以将这些奖励视为生成一个“标签”,然后你可以根据它进行训练——尽管反向传播会看起来有所不同(稍后会详细介绍)。
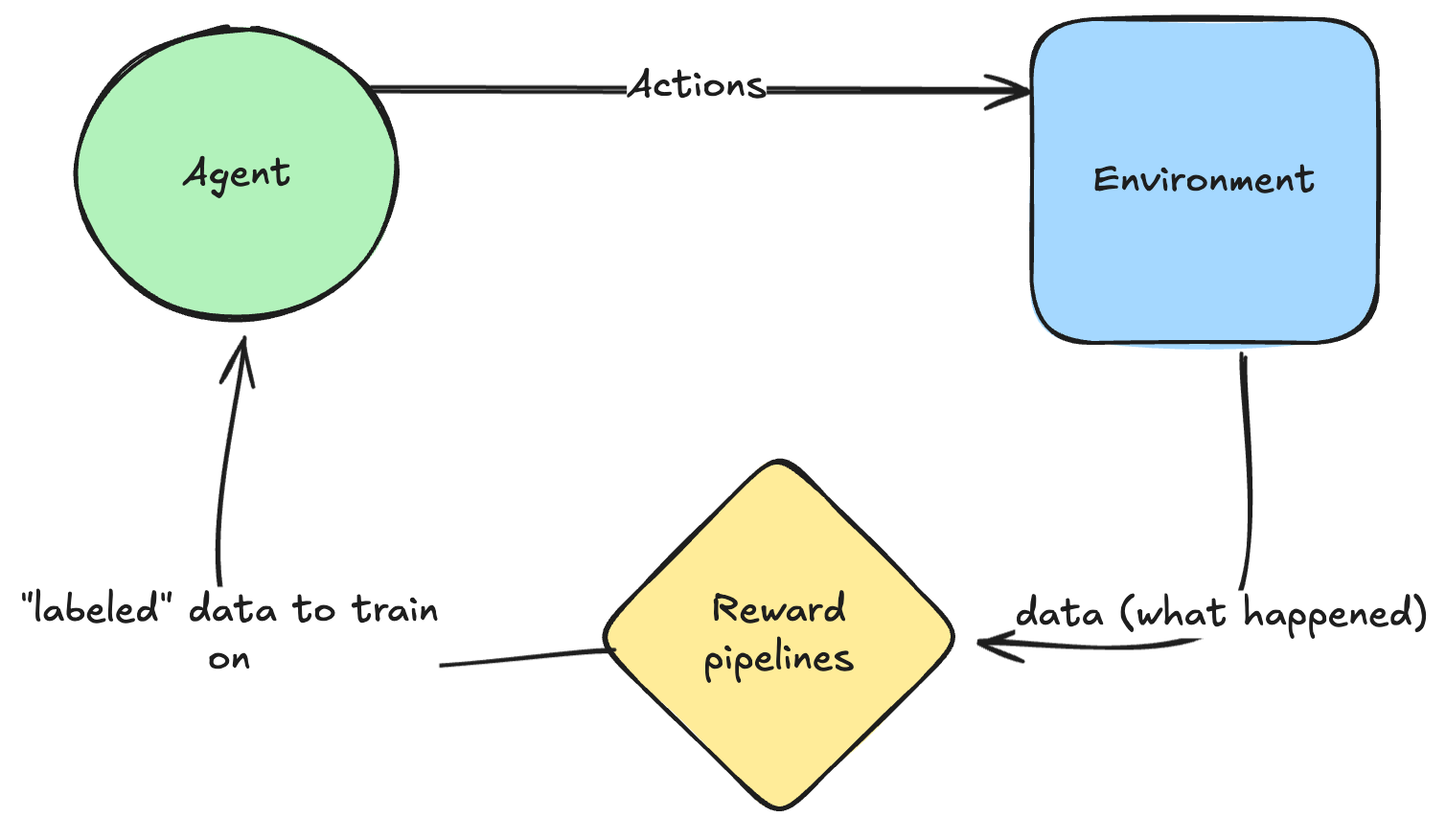
如何训练?
反向传播确实发生在强化学习中,但与我们在监督学习中享受的整洁的前向-后向循环有关键区别。
关键的区别在于,在强化学习中,我们不幸没有一个可微分的成本函数,例如交叉熵或均方误差 (MSE)。奖励(以及浏览器等工具)是不可微分的,因此你无法直接通过它们进行反向传播——这非常不幸。
因此,我们采取的替代方法是一种非常粗糙的近似:我们只是对模型输出中的对数概率进行操作,如果行动良好,就使其更大,如果不好,就使其更小——然后,我们反向传播到模型中,调整所有前面的层以实现这一点。请注意,这远不如优化像 MSE 和交叉熵这样的监督成本函数高效:监督成本函数返回一个密集的梯度向量,而在这里我们只从整个情节中得到一个标量,这效率低得多,因为每次交互我们获得的“学习动力”更少。
强化学习过程还有更多的细枝末节,不同的算法在如何解决主要问题(梯度消失/爆炸、样本效率、基础设施优化等)上做出了不同的选择,但这就是大致的要点。附录详细地逐步推导了近端策略优化(PPO)。
让我们从基础设施的角度来看:与“标准”监督学习相比,你需要对模型进行大量的推理,这更昂贵(自回归、逐个 token 生成,而不是在单个前向传递中馈入整个现有序列),需要更多的基础设施(KV 缓存等),更难以批量处理等等。
尽管训练目标如此粗糙,但在存在稀疏或长期奖励的情况下,它实际上运行得非常好,而 SFT 需要奖励是密集的(你会知道每个 token 应该是什么)。
延续国际象棋的类比
- SFT 逐步教模型复制
- 在强化学习中,模型在赢得比赛时(可能在 20 步之后)会获得奖励。训练算法会倾向于那些能更频繁地获得更多奖励的模型配置(给定一些探索/利用的权衡)。
虽然你一开始会弱得多,但最终,通过玩足够多的游戏,你可以达到马格努斯的水平,甚至远远超越他——换句话说,你能够达到的上限要高得多。
从某种意义上说,你可以将强化学习视为一台神奇的机器,它弥合了判断与行动之间的差距:这是一个非常大的差距!我能认出 F1 赛车手何时失误,但我却无法做到即使是最差的 F1 赛车手也能做到的事情。强化学习可以将任何“键盘车神”变成真正的赛车手🏎️
如果你想用一句话来概括,“如果你能判断它,你就能学会它!”。
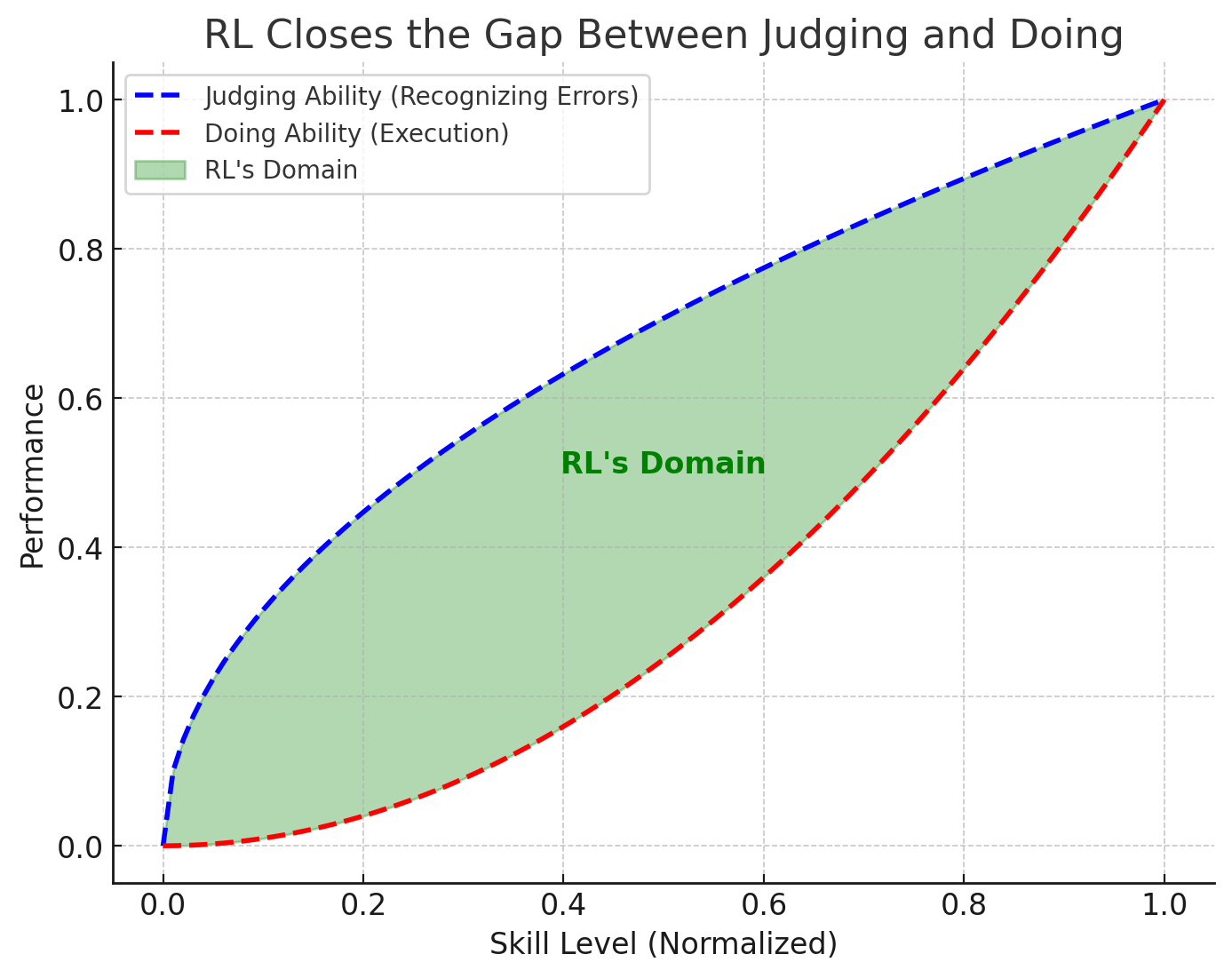
奖励黑客攻击
注意一件事:你的上限仍然由你的判断能力(蓝色曲线)决定,而你的判断能力又由你的奖励有多好决定:对于游戏之类的东西,奖励非常清晰(你知道你何时以 100% 的精确度和召回率获胜),所以天空才是极限。你确实可以将强化学习应用于任何事物,但如果你判断得不好,你的代理将只会学习到噪音。
强化学习受限于你的判断能力的一个推论是,它可能会学到你没有意图的行为:强化学习会竭尽所能最大化你给予它的奖励,因此模型会完全按照你要求的去做,而不是你想要的。我们称之为奖励黑客攻击,即使模型对此不负责,而是我们在设计激励机制时造成的!
举个例子来证明这一点:强化学习发现《超级马里奥 1》在 30 多年来一直存在一个 bug,即跳跃后转身,你会有一个帧的无敌时间。鉴于其奖励是最大化得分,并且如果你更快通关,你的得分会提高,它就会利用这个 bug 来获得更高的得分(从而获得更高的奖励)。
开发者想要什么
- 最大化得分
- 仍然像人类一样玩
- 不利用漏洞
开发者要求什么
- 最大化得分
注意:这在人类身上也会发生!我们只是称之为反常激励,但它们实际上是同一回事。英国政府担心德里眼镜蛇数量过多,悬赏每条死去的眼镜蛇。最初,这是一个成功的策略;大量蛇被杀死以换取奖励。然而,最终人们开始饲养眼镜蛇以获取收入。
LLM 的应用
与国际象棋的例子类似,强化学习可以比 SFT 具有更高的上限,因此它是教导模型如何以我们喜欢的方式与人类对话(RLHF)、如何推理等的首选方法。
正如我们刚刚看到的,你能够达到的上限取决于你的奖励有多好:如果你使用分类器来提供奖励,你的上限将是该分类器的准确性。
RLHF
其中一个分类器是人类偏好。很难为如何以人类喜欢的方式写作制定规则,因此我们采取的方法是训练一个分类器来给这些写作打分。我们通过准确率和 PR AUC 来监控其性能(如果你需要一个连续的分数进行排名,则只需要 PR AUC;否则,像 F1 或准确率这样的点估计就足够了)。一旦有了这个分类器,你所需要做的就是针对它运行强化学习并根据其反馈进行优化。
DPO:直接偏好优化
现在让我们看看 LLM 后训练流程中的第二个方框。DPO 是一种专门用于 LLM 的 RLHF 的算法,它不是一种通用的强化学习算法(与 PPO 及其同类不同,PPO 可以用于训练机器人以及任何你想要的东西)。
事实上,严格来说,DPO 甚至不是一个真正的强化学习算法;它只是假装是!DPO 的核心思想是,如果你做一些合理的假设,你就能在仍然为 RLHF 进行训练的同时拥有一个可微分的损失函数。
更准确地说,DPO 允许我们在某些假设下(详见后文)为马尔可夫决策过程提供一个监督学习解决方案,这是一件大事,因为通常解决 MDP 的唯一通用方法是通过强化学习(及其低效的成本函数)。
DPO 的核心思想是:与其有一个单独的奖励模型,你可以将你的 LLM 回收利用,使其既是你的策略模型又是你的奖励模型。为什么?因为你的 LLM 会给出给定问题的一个答案的概率。因此,如果你有一个偏好对,你就可以简单地说,对于同一个问题,你希望首选答案的概率高,而拒绝答案的概率低。换句话说,你希望最大化,这会导出一个非常好的可微分函数!
与 PPO 和其他需要通过大量推理采样多个答案的强化学习算法相比,DPO 的运行成本极其低廉。缺点是DPO 不进行探索,因此你的表现也有一个上限。下面是对“真实”强化学习算法(如 PPO,我们将在后面更详细地介绍)的更详细比较。
| 特性 | DPO(直接偏好优化) | PPO(近端策略优化) |
|---|---|---|
| 优化 | 监督学习 | 强化学习 (RL) |
| 所需数据 | (提示,首选,拒绝) 对的固定数据集 | Rollouts + 奖励模型 |
| 损失函数 | 类似二分类的损失 | 裁剪策略梯度损失 |
| 探索 | ❌ 否(固定数据集,无探索 - 完全离线) | ✅ 是(策略可以探索新的响应 - 在线算法) |
| 同策略? | ❌ 异策略(从固定数据中学习) | ✅ 同策略(需要新的 rollouts) |
| 计算成本 | ✅ 低(每对只需一次前向传播) | ❌ 高(rollouts + PPO 训练) |
| 训练稳定性 | ✅ 稳定(类似微调) | ❌ 不稳定(RL 方差) |
| 收敛速度 | ✅ 快 | ❌ 慢(需要多次 rollouts) |
| 性能受限于 | ❌ 数据 | ✅ 计算(更好的选择) |
| 最适用于 | 利用人类偏好进行廉价对齐 | 更灵活但昂贵的微调 |
在线强化学习
我们 LLM 后训练流程中的第三个也是最后一个方框是在线强化学习。“标准”算法是 PPO(近端策略梯度),由 OpenAI 于 2017 年创建。另一个被广泛采用的算法是GRPO(Group Relative Policy Optimization,由DeepSeek引入)。
关键概念:同策略与异策略
一个策略就是你正在训练的 LLM。同策略意味着与环境的每次交互都直接来自正在训练的模型。这最有意义,因为我们就是这样向私人导师学习的:我们尝试一些东西,犯一些错误,立即得到反馈,然后带着这些知识再次尝试。这比异策略学习要好得多,异策略学习是向你展示别人在这种情况下做了什么,你可以从中学习——这个“别人”可以是(而且通常是)你过去的版本,所以通常会保留你过去所做的记忆在一个回放缓冲区中以备后用。
强化学习算法属于这两个家族中的一个,PPO 属于同策略一方,而 Q 学习(如 DQN)则属于异策略阵营。
| 特性 | 同策略强化学习(例如 PPO) | 异策略强化学习(例如 DQN、DPO) |
|---|---|---|
| 定义 | 从当前策略收集的数据中学习 | 从先前收集的数据(即使来自旧策略)中学习 |
| 探索 | ✅ 是(持续生成新的 rollouts,探索-利用权衡已经内置到策略网络的 logits 中——自然地开始大量探索,并逐渐转向利用) | ❌ 当离线运行时,你永远不会探索,因为你只是重复使用你之前生成的旧数据(例如 DPO)。
你可以在线运行并探索,但探索策略由你定义(例如 epsilon-greedy) |
| 基础设施效率 | ❌ 低(需要始终在线生成数据) | ✅ 高(重用过去的生成) |
| 训练稳定性 | ❌ 不稳定(策略不断变化) | ✅ 更稳定(固定数据集或重放缓冲区) |
| 计算成本 | ❌ 高(需要频繁的 rollout)
成本主要由于训练循环的同步性质(收集 → 训练 → 收集 → 训练) |
✅ 低(在存储数据上训练) |
| 算法示例 | PPO、A2C、TRPO | DQN、DDPG、SAC、DPO |
| 最适用于 | 需要持续探索的情况 | 当你能够存储和重用过去的经验时 |
从基础设施角度看:在线 vs 离线强化学习
同策略与异策略是从模型训练动态的角度来看待事物。如果从基础设施的角度来看待事物,我们应该考虑离线(使用静态数据,我们在训练时简单地重新加载)与在线(我们实时生成数据)。这两个概念与异策略和同策略很好地对应,因此有时可以互换使用,尽管严格来说它们仍然有点不同:
- 如果你是离线学习,你只能进行异策略学习(因为数据是由另一个模型生成并保存的)。拒绝采样和 DPO 是异策略的离线算法。这对于基础设施来说是最简单的事情。
- 如果你是在线学习,那么一旦你开始考虑使用多台机器和同步,同策略还是异策略实际上更像是一个范围。如果你想严格同策略,这意味着你以批量大小 = 1 进行训练,然后从该模型中采样,并在整个过程中引入障碍,以便模型不断更新,并且在我们将所有权重重新分散到所有节点之前,不会采样新的轨迹。
在代码中
# Idealized PPO training loop collector = CollectorClass(model) for i in range(num_collection): collector.sync_weights_() # align weights across all workers # resume collection and put trainer node on hold <- this is bad! data = next(collector) # collect data # Put collector nodes on hold <- this is bad! for j in range(num_epochs): for batch in split_data_randomly(data): loss_val = loss_fn(data) loss_val.backward() optim.step() optim.zero_grad()
因此,某种程度的“异策略性”是可取和可接受的。这伴随着许多问题:这种情况在多大程度上成立?你应该多久更新一次收集权重?如何才能重叠权重同步、收集过程和模型训练以最大化吞吐量?
我不希望你带着异策略和离线算法必然是糟糕且在所有情况下都应避免的想法离开本节。事实上,Llama 管道的前两个部分(SFT 和 DPO)本质上是通过监督成本函数解决对齐马尔可夫决策过程的一种方式。这些作为“某种”离线、异策略强化学习:
- 我们的 SFT 数据来自拒绝采样,这意味着我们用模型本身生成它。虽然我们不使用真正的异策略 RL 算法,如 DQN,但以这种方式进行的拒绝采样是一种离线策略优化形式。
- 同样,我们已经看到 DPO 也是一种离线策略优化形式,它也避免了进行实际的强化学习梯度更新,而这些更新是缓慢且不稳定的。
不同的团队在如何利用所有这些技术以及如何组合它们方面找到了不同的方法,但并非所有团队都公布了这些信息。
超越 RLHF:一种通用范式
没有什么能限制我们只停留在人类反馈上——事实上,我们也没有。如果你想学习如何写好代码,你可以提供一个测试工具,并根据通过的测试数量给予相应的奖励。如果你想学习求解积分,你可以使用 Wolfram 来检查你的方程是否正确。
简而言之,你可以通过混合 Software 1.0 和 Software 2.0 来构建奖励管道。常见的模式是:
1. 奖励模型。 一个分类器,给出从 0 到 1 的连续分数(有时甚至是无界的)。适用于对许多答案进行排序(只需按分数排序),尤其是在你无法轻易表达所需内容(人类偏好、写作风格等)的领域。
a. 结果奖励模型。 ORM 根据思想链的最终结果提供反馈,且仅根据最终结果。这些是最常见的——事实上,如果有人只说“奖励模型”,指的就是这些。
b. 过程奖励模型。 在上面的例子(国际象棋)中,奖励是稀疏的:它只在游戏获胜或失败时发生。直观地说,拥有密集奖励可以帮助代理获得关于哪些行为是或不是可取的更精细的知识。这就是 PRM 所做的:它们不仅判断最终输出,还判断整个步骤序列。例如,PRM 将判断整个推理链条,并确保每个步骤都合理。这些并不常用(至少目前还没有),因为它们往往非常嘈杂。
2. 基于规则的奖励。你可以写下一系列规则,并为每个规则(或整体遵守这些规则)设置奖励。
a. 软件管道。这些运行“普通”软件 1.0,并根据其结果给你奖励。例如,通过编程的测试用例或通过 linting。
b. 判官。当你无法通过传统软件管道检查规则是否被遵守时,你可以使用 LLM 来为你验证规则是否被遵守。例如,你可以写下一组不得违反的安全规则,例如:“不得提及性相关内容”,判官可以问“所有规则都遵守了吗?”。注意:这与连续评分奖励模型不同,因为你只得到一个二元答案(规则遵守或不遵守)。你无法在此基础上对许多答案进行排名,因此这被用于在某些规则被违反时提供负面奖励。在实践中,你通常甚至不会训练这些模型,而是简单地提示一个基础模型为你进行判断。
这些是构成非常复杂的奖励塑造管道的组成部分。例如,你可以想象拥有一个由这些管道组成的复杂有向无环图(DAG),以提供非常精细的奖励。
编码的简单示例:
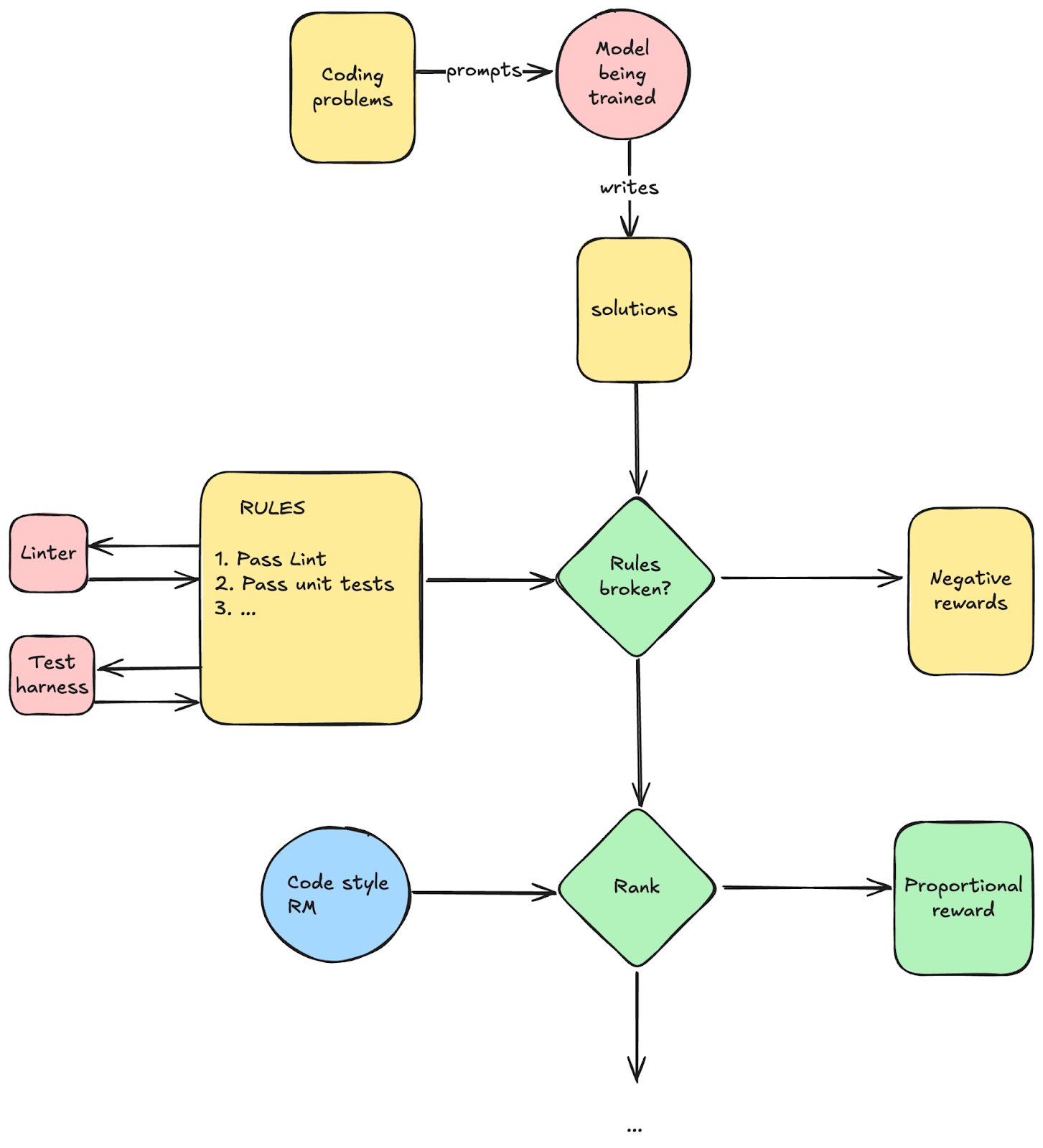
这有基础设施方面的影响
- 测试工具和其他需要运行的二进制文件的沙盒
- 我们把所有这些奖励模型部署在哪里?你可以有很多,而且它们可能很大(不要把它们想象成小的专用分类器!它们通常和你要训练的模型一样大!)。
- 我们应该期待越来越多的工程师开发越来越好的奖励管道(更精细,以塑造模型的行为)。这可以成为工程师贡献的主要场所。这些管道本身就可以成为一个有用的 Hub,并可以众包开发。
测试时计算和推理
测试时推理是过去一年由OpenAI提出的一个主要趋势,DeepSeek 在其DeepSeek R1 论文中也成功复现。
让我们深入了解这是什么。
简而言之,这建立在之前的工作(如思维链和ReAct循环)之上,这些工作发现让模型在给出答案之前“自言自语”可以大大提高其答案的质量,特别是在数学等特定领域。这种能力是自发产生的,从未为此训练过 LLM。因此,自然而然的下一步就是找出一种训练 LLM 的方法,使其更好地进行这种“思考步骤”。
我们不知道 OpenAI 采用了什么技术,但 DeepSeek R1 论文最令人惊讶的发现是,你不需要一个超级巧妙的设置来诱导这种学习。事实上,他们表明,只需为模型提供思考空间(通过简单地指示它在<think>标记和</think>标记之间填充文本,并且该文本不为空)。
这是他们使用的系统提示

一旦这些就绪,他们就进入了奖励建模。
论文摘录注释
我强烈建议阅读完整的DeepSeek R1 论文,因为它写得非常好。在这里,我们引用了论文的几个部分,并附上我的评论,以便为非该领域专业读者提供背景信息。
第 2.2.2 节:奖励建模
奖励是训练信号的来源,它决定了强化学习的优化方向。为了训练 DeepSeek-R1-Zero,我们采用了一种基于规则的奖励系统,主要包括两种奖励:
|
评论:这都是我们已经见过的相当标准的东西。概念上很简单。在实践中,这需要机器学习工程师的技艺,才能制作出好的奖励,这些奖励既没有噪音,又能推动强化学习过程朝着你想要的方向发展。
|
评论:聪明!!!这是一种促使模型开始利用思考过程的简单方法。否则,它可能不会始终如一地探索在这些<think>和</think>标签之间添加思考。当它不这样做时,施加强烈的负面奖励可以使其端正,并将探索限制在使用这些标签上。他们到 R1-Zero 就停止了,但实际上你可以继续进行更复杂的奖励建模。例如,R1-Zero 有时会混合使用英语和中文思考,所以你可以通过添加一个提示(然后是奖励)来解决这个问题,让它用英语思考。如果思考过程被判断为在某种程度上“不好”(不一致等),你还可以添加中间负面奖励,以进一步引导模型。你可以看到这是一个通用范式……
|
评论:也许社区中有人最终会找出如何让过程奖励模型起作用的方法……
其他观察
- “啊哈”时刻

这对我来说非常有趣,因为强化学习本质上是自己学习回溯。这非常酷,老实说我没想到会发生这种事。我想你可以通过搜索来改进这一点:波束搜索是最简单的,从那里你可以进入蒙特卡洛树搜索(MCTS)等树搜索算法。既然我们有了一个有效的基础,我认为我们将在所有这些更复杂的方法上看到更快的进展。在我看来,这是这项工作的一个被严重误解的部分:DeepSeek 并没有表明你不需要所有这些人工智能计算,恰恰相反!他们只是表明你不需要复杂的方法来开始,简单的规模方法就足够了——这是我们在人工智能中不断学习的教训。
自行增加思考时间(和测试时计算):
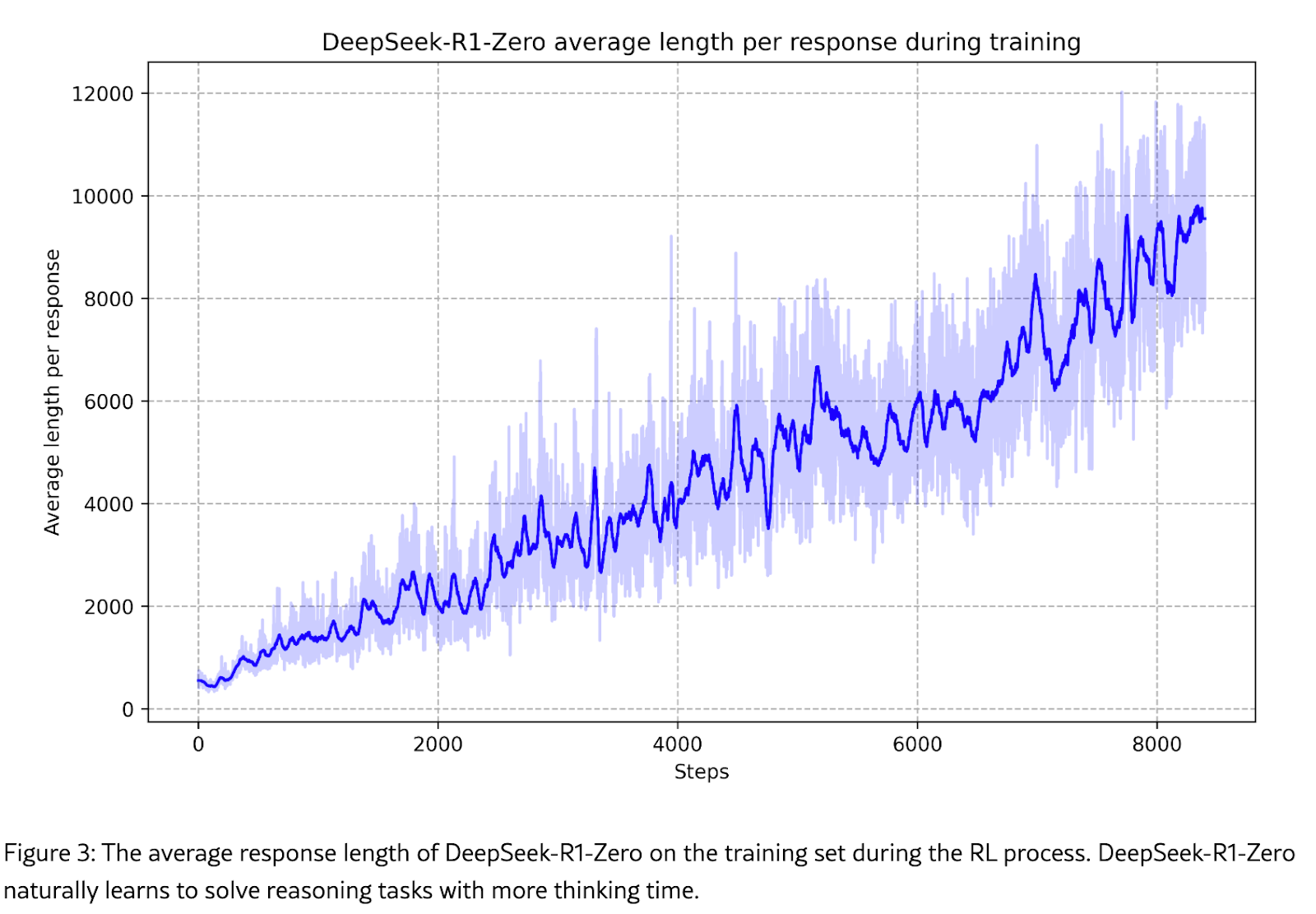
由于他们从未给模型任何思考时间过长的惩罚,强化学习发现思考更长时间没有任何坏处,并且随着每次迭代的进行,它只是不断朝着更长的思考轨迹方向发展。这是意料之中的。我想象,如果他们继续下去,模型也会自动学习在其最大序列长度处停止,因为那样它就无法记住其整个推理轨迹,所以继续下去将无济于事(甚至可能有害)。
模型再次学习到测试时计算是好的,因此我们应该预期计算需求会上升。
附录 A:深入了解 PPO
让我们更深入地了解强化学习中的反向传播。
让我们从监督机器学习(无强化学习)中的“基本训练循环”开始
loss_fn = nn.CrossEntropyLoss() for batch in dataset: x, y = batch y_hat = model(x) # One forward pass only loss = loss_fn(y, y_hat) loss.backward() # One backward pass
回想一下,在强化学习中,我们没有一个明确定义的成本函数,所以我们只是让一个行动如果好就更有可能,如果坏就更不可能。我们如何做到这一点?
我们的模型已经输出一个关于动作的概率分布,所以最后一层将对所有动作进行 Softmax。我们要做的是对好的动作给予正梯度,对坏的动作给予负梯度。
所以,基本上,我们想做这样的事情
model.weights.grad[good_actions] += delta model.weights.grad[bad_actions] -= delta
自动梯度可以为我们做到这一点:为了获得添加到梯度中的恒定增量,我们需要一个当被微分时能给我们这个增量的函数。答案是乘法。所以,我们的“成本函数”简单地是log_probs * per_token_reward。
让我们保持高层次并逐步开发(否则 PPO 损失看起来相当可怕)
for batch in dataloader: # Iterate over dataset (prompts) prompts = batch # Get input prompts: (bsz, prompt_lens). Can be ragged, or packed. responses, log_probs = model.generate(prompts) # Autoregressive generation! MANY forward calls, need KV cache etc. If this is not clear to you, read this appendix. # Also note: we NEED to return log_probs for all the intermediate generations and note that we are not detaching them from the graph as we are gonna need them later. # responses and log_probs are of size (bsz, response_lens). Also ragged/packed. sequence_rewards = get_feedback(responses) # Get rewards (e.g., human preference or heuristic). # Note that rewards CAN be negative, in that case this sign will be negative. # This is a tensor of size (bsz,). per_token_reward = discount(sequence_rewards) # This one is (bsz, response_lens). A simple way to discount is to multiply tokens by a factor gamma (eg 0.99). So the last token gets reward of 1, the second-to-last gets 1*gamma, then the previous gets 1*gamma*gamma and so on. You don't want to maximize only your reward at time t but the sum of rewards till the end of the episode optimizer.zero_grad() # Reset gradients # Manually nudge log-probs based on reward signal adjusted_log_probs = log_probs * per_token_reward # this is a stochastic estimator for the gradient of the reward expectation given your stochastic policy - in other words: on average, the gradient of that thing points to where the policy is doing good! loss = -adjusted_log_probs.sum() # Equivalent to maximizing probability of good actions loss.backward() # Still ONE backward call! PyTorch knows what to do. optimizer.step() # Update model parameters
请注意,尽管我们进行了多次前向传播(由于自回归生成),但我们只需要一次反向传播(好吧,假设我们保留了图。如果你使用 VLLM 或其他方式完成这些生成,那么我们将需要在这里多进行一次前向传播来具现化这边的图,这应该不会太糟糕……)。
现在让这更真实
以上是我们概念上所做的一切。但当你尝试它时,一切都会发散 😀
让我们进行这些更改
- 自适应增量。使用静态增量并非最优,因为更新的幅度应与选择的优劣成比例。与其手动调整对数概率,我们可以让反向传播为我们完成工作。如果你想增加概率,你可以简单地最大化对数概率。为了在梯度下降中做到这一点,我们最小化负对数概率。这就是策略梯度损失函数:
policy_gradient_loss = - (rewards * log_probs).sum(dim=-1).mean() policy_gradient_loss.backward()
- 减少方差。如果我们仅用以上方法进行训练,一些响应会获得巨大奖励,而另一些则会获得零奖励,导致训练不稳定。一种缓解方法是引入一个基线,即平均移动的预期累积奖励:不太糟,但也不太好。这背后的直觉是,一个移动的好坏总是取决于可用的替代方案:例如,获得 100 万美元似乎很棒,直到你意识到你有机会获得 1 亿美元。
这种相对于基线的移动的“优良性”被称为优势,这是强化学习中的一个核心概念。
我们如何预测基线分数(也称为状态的价值)?有两种方法:
- 价值网络。训练一个模型为你做这件事:你可以训练一个价值网络来估计这个基线应该是什么。
- 蒙特卡洛。简单地运行一批生成(通常 4-5 次就足够了),所有生成的平均累积奖励就是你对价值的估计。
现在我们的代码会是这样的
for batch in dataloader: prompts = batch responses, log_probs = model.generate(prompts) rewards = discount(get_feedback(responses)) # Already discounted for n in range(epochs): for _prompts, _log_probs, _rewards in make_minibatches( prompts, log_probs, rewards, ): values = value_network(_prompts) # Predict baseline V(s) optimizer.zero_grad() # REINFORCE with baseline advantages = _rewards - values # Compute advantage estimate loss = - (advantages * _log_probs).sum(dim=-1).mean() loss += advantages.pow(2).mean() loss.backward() optimizer.step()
信不信由你,那仍然不稳定!强化学习就是极度不稳定且难以捉摸(尽管与其它领域相比,它对 LLM 来说表现出人意料地好)。一个原因是奖励的分布可能有一个很长的尾部,也就是说,你的梯度行为不佳。因此,在实践中,我们确实需要确保更新受到良好约束,以便训练表现良好。
PPO 基本上通过强制执行四个不同的约束来确保稳定性
1. 标准化优势
上面的代码乘以原始优势,尽管我们尽力进行基线化,但仍然可能导致巨大的更新,从而破坏训练的稳定性。一种使其行为良好的方法是简单地将其平移到零均值并缩放到单位方差。
advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8)
2. 重要性采样
这仍然不够。为了进一步改进,我们将强制更新保持在信任区域内。PPO 通过防止更新相对于旧策略过大来做到这一点(所以是的,它需要保留 t-1 时刻的模型):
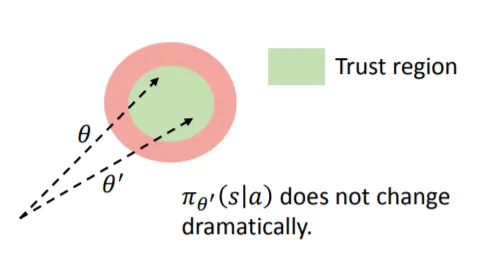
所以现在我们这样做
old_log_probs = get_old_log_probs(prompts, responses).detach() # Log probs from previous policy importance_sampling_ratio = torch.exp(log_probs - old_log_probs) safe_advantages = importance_sampling_ratio * advantages
3. 裁剪大的更新
书中最古老的技巧。如果你面临梯度过大的风险,只需裁剪它。
old_log_probs = get_old_log_probs(prompts, responses).detach() # Log probs from previous policy importance_sampling_ratio = torch.exp(log_probs - old_log_probs) clipped_sampling_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon) even_safer_advantages = clipped_sampling_ratio * advantages
4. 取最小值()
这对我来说是最令人惊讶的一点。与其仅仅使用剪裁过的优势,你实际上想要运行一个剪裁过的版本和未剪裁版本之间的min。原因很微妙:强化学习会试图最大化其奖励,如果你只提供剪裁过的奖励,它会将奖励推高到尽可能接近剪裁阈值,这仍然会破坏整个过程的稳定性(更多细节此处)。
old_log_probs = get_old_log_probs(prompts, responses).detach() # Log probs from previous policy
importance_sampling_ratio = torch.exp(log_probs - old_log_probs) clipped_sampling_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon) safe_advantages_final_final = torch.min(ratio * advantages, clipped_sampling_ratio * advantages)
把它们组合在一起
epsilon = 0.2 # Clipping threshold for batch in dataloader: prompts = batch # prev_log_probs are part of the loss - non-differentiable with torch.no_grad(): responses, prev_log_probs = model.generate(prompts) rewards = discount(get_feedback(responses)) values = value_network(prompts) advantages = rewards - values advantages = (advantages - advantages.mean()) / (advantages.std() + 1e-8) # ref_log_probs are used for regularization with torch.no_grad(): ref_log_probs = get_old_log_probs(prompts, responses).detach() for n in range(epochs): for batch in make_minibatches(...): log_probs = model(batch.prompts)[1] ratio = torch.exp(log_probs - batch.prev_log_probs) # Importance ratio clipped_ratio = torch.clamp(ratio, 1 - epsilon, 1 + epsilon) # The min() function prevents the model from "gaming" the clipped update loss = -torch.min(ratio * batch.advantages, clipped_ratio * batch.advantages).mean() # + add value_network loss, ref model regularization and entropy boost... optimizer.zero_grad() loss.backward() optimizer.step()
如果现在你看到它写成一个方程式,希望它看起来不那么可怕了!
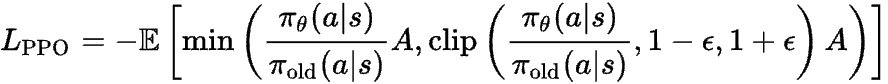
在 PPO 中,还有两个额外的损失。
在训练策略网络的同时,价值损失用于协同训练价值网络。简单来说,你可以使用在各种生成中获得的实际收益来持续训练价值网络,所以这只是它们之间的 MSE 损失:
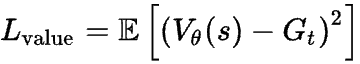
最后,作为又一道防护措施,我们还将阻止强化学习过多地改变模型的权重:毕竟,在预训练中花费数百万美元的计算来教导模型关于世界的信息,我们不希望强化学习偏离这些太多。
一个简单的方法是简单地添加一个 KL 散度损失项。
![]()
最终的 PPO 损失是这个
![]()
其中 c1 和 c2 是你通过实验设置的超参数,用于平衡这些项(通常它们很小)。
DeepSeek 的 GRPO
现在你已经掌握了所有能够打开论文阅读可怕公式的要素。这是 DeepSeek 的 GRPO 的公式(取自他们的论文)

基于蒙特卡洛的优势估计
GRPO 的“创新”(对奖励进行蒙特卡洛采样)实际上是一个老技巧——人们在拥有价值网络之前就这么做了!价值网络应该更稳定,但你可以想象,也昂贵得多。社区中关于如何处理这个问题有一些讨论,批评网络不会很快从灰烬中崛起,这并非板上钉钉!
运行这个东西有多贵?
总结一下,在最坏的情况下,我们必须按顺序运行以下模型(我只展示了精简的网络操作)
1. 运行推理模型,获取 token 和log-probs推理
1 次前向传播
2. 给定生成的 token 运行参考模型,获取 log-probs参考
1 次前向传播
3. 给定生成的 token 运行奖励模型,获取奖励
1 次前向传播
4. (运行批评者以获取价值 -> 优势估计)
1 次前向传播
5. 给定一批 token 运行图内模型副本,获取log-probs训练
6. 计算
lp0 = f(log-probs训练, log-probs推理, 优势) + c1 L(log-probs训练, log-probs参考)
7. 反向传播 lp0,对模型权重进行 adam 步进
8. 计算
lp1 = c2 L(价值, 优势)
9. 反向传播 lp1,对评论者网络权重进行 adam 步进
去除批评者(如 GRPO)可以消除第 4 步(1 次前向传播)和第 8-9 步(1 次反向传播 + 优化器步进)的成本,从而节省大量的内存和计算。
附录 B:为什么生成比处理提示更昂贵
如果你查看 LLM 云服务提供商的价格,你会注意到他们对输出 token的收费总是比对输入 token的收费高得多,例如:GPT5费用为 100 万输入 token 1.25 美元,但 100 万输出 token 10.00 美元。为什么会这样?
原因是自回归生成比处理已经写好的文本昂贵得多!这是由于 Transformer 的工作方式。它们总是需要消耗整个序列,因此要处理一段文本,你只需要一次前向传播。要生成新文本,你生成的每个 token 都需要运行一次前向传播。然后,你获取带有刚刚生成的新单词的序列,再次将其输入以获取下一个单词,依此类推。这非常昂贵,并通过 KV Cache 得到缓解。
请注意,这与 RNN(如 LSTM)不同,在 RNN 中,如果你有一个长度为 L 的序列,并且你想处理一个额外的 token,那么前向传播将只摄取该单个 token 并重用它拥有的状态。与 LSTM 不同,Transformer 是无状态的,因此你需要摄取整个序列,并再进行一次 L+1 个 token 的前向传播!
幸运的是,大部分计算可以回收,因此 KV 缓存将大大缓解这个问题(否则,我们老实说将无法在生产中提供这些模型),但它仍然是一个问题。
举个例子。
你有一个提示
<system>You are a nice LLM, be kind</system>
然后用户写道
<user>What's the capital of France?</user>
因此模型将收到此输入以开始生成
"<system>You are a nice LLM, be kind</system><user>What's the capital of France?</user><agent>"
所有上述内容都可以通过一次前向传播进行处理,因为所有 token 都已存在。
现在,你生成一个 token
The
要生成下一个 token,你需要再次对整个序列进行另一次前向传播!!!现在,模型需要摄入
"<system>You are a nice LLM, be kind</system><user>What's the capital of France?</user><agent>The"
它将生成 capital(它实际上会生成一个空格,但是……你知道……让我们加快速度)。现在,再次
"<system>You are a nice LLM, be kind</system><user>What's the capital of France?</user><agent>The capital"=
你可以看到这有多昂贵……