Meta:Less Wright、Meet Vadakkanchery、Saurabh Mishra、Ela Krepska、Hamid Shojanazeri、Pradeep Fernando
Crusoe:Ethan Petersen、Martin Cala、Chip Smith
PyTorch DCP(分布式检查点)最近在异步检查点中启用了新的优化,通过最小化集体开销和提高整体检查点效率来减少 GPU 利用率下降。
使用 Crusoe 的 2K H200 集群,以及 TorchTitan 训练 Llama3-70B,我们能够验证这些新功能在 1856 个 GPU 规模下提供了显著的加速,将异步 DCP 检查点的后台处理时间从约 436 秒减少到约 67 秒。
这大约是后台检查点处理时间减少了 6.5 倍,使得更多的总训练时间能够以全训练吞吐量进行。
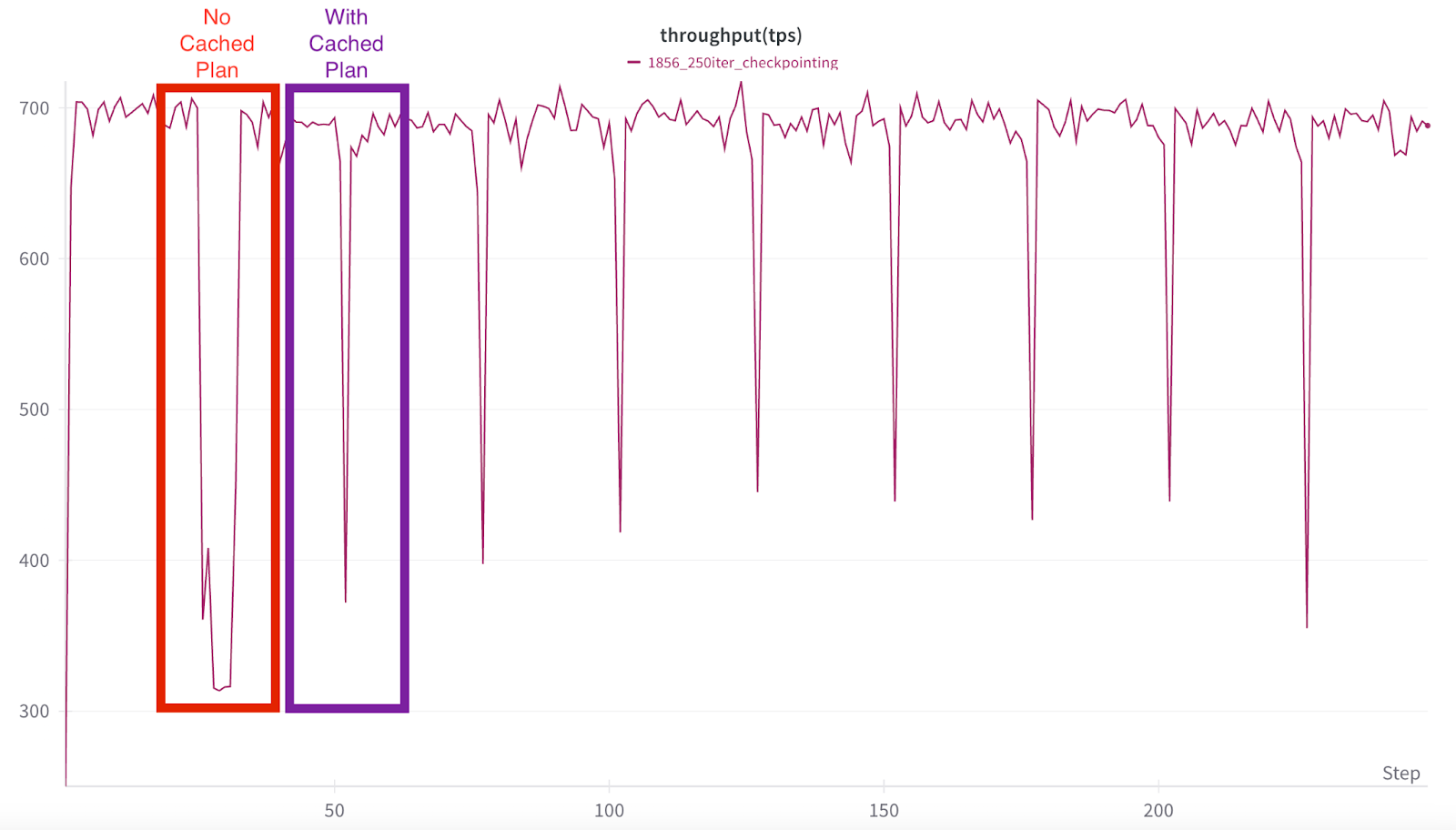
图 1:1856 次高频检查点训练运行。第一个检查点(tps 下降)没有缓存保存计划,后台处理时间远长于使用缓存计划的其余检查点。
背景:什么是异步检查点?
在标准的检查点工作流中,GPU 在检查点数据从 GPU 卸载到 CPU 并写入存储时会被阻塞。完成保存到物理介质后,训练才能恢复。
异步检查点通过允许实际保存到存储由 CPU 线程完成,大大减少了停机时间,从而使基于 GPU 的训练能够继续进行,同时检查点数据并行持久化。它主要用于中间/容错检查点,因为它比同步检查点更快地解除 GPU 阻塞。
例如,在我们的 S_A 大规模实验中,GPU 训练被阻塞不到一秒(在 1856 规模下为 0.78 秒),而检查点数据从 GPU 移动到 CPU(暂存)。此时,GPU 训练立即继续,这比传统检查点大大提高了训练时间。作为参考,异步检查点在此处有更详细的介绍。
异步检查点的挑战
然而,异步检查点固有的后台处理带来了额外的挑战,导致在存储阶段完成期间训练吞吐量暂时下降。这些挑战如下所示。
GIL 争用导致的 GPU 利用率下降
Python 中的全局解释器锁(GIL)是一种阻止多个原生线程同时执行 Python 字节码的机制。这个锁之所以必要,主要是因为 CPython 的内存管理不是线程安全的。
DCP 当前使用后台线程进行元数据收集和上传到存储。尽管这些昂贵的步骤是异步完成的,但它会导致与训练器线程争用 GIL。这会导致 GPU 利用率(QPS)显著下降,并增加端到端上传延迟。对于大规模检查点,CPU 并行处理的开销会对 GPU 训练速度产生抑制作用,因为 CPU 也通过 GPU 内核启动来驱动训练过程。
请参考我们实验中的下图
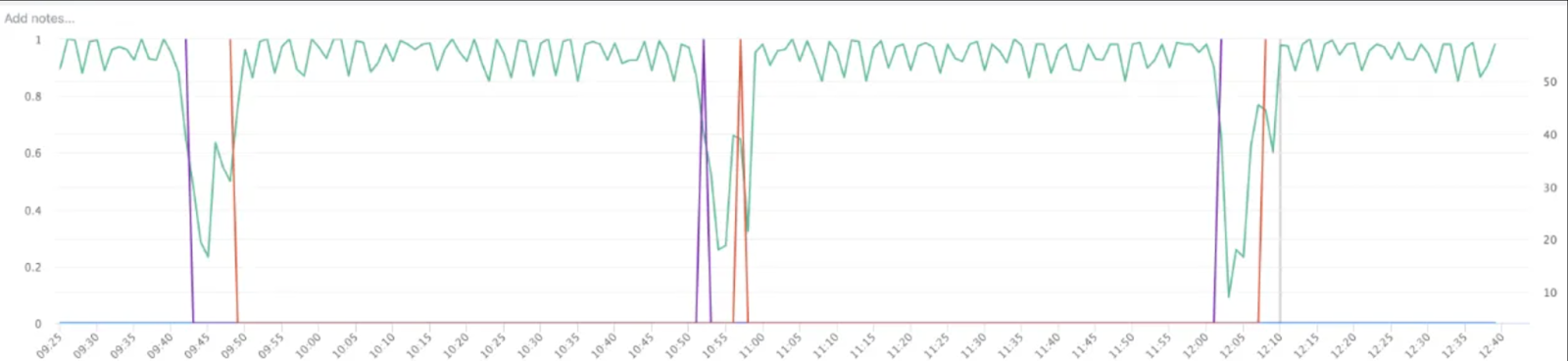 图 2:即使在暂存(即训练器的阻塞操作)完成后,训练 QPS 仍然持续下降。
图 2:即使在暂存(即训练器的阻塞操作)完成后,训练 QPS 仍然持续下降。
图 2 中的第一次下降(由紫色线标记)表示暂存完成,训练可以继续。然而,第二次下降很明显(由紫色线和黄色线之间的区域标记),这是由于训练器线程和检查点线程争用 Python GIL,导致训练 QPS 下降,直到检查点线程完成执行。
集体通信成本
DCP 目前出于各种原因执行多次集体操作:去重、检查点的全局元数据、重新分片和分布式异常处理。集体操作成本高昂,因为它们需要网络 I/O 以及跨 GPU 网络发送的大量元数据的序列化/反序列化。随着作业规模的增长,这些集体操作变得极其昂贵,导致端到端延迟显著增加和潜在的集体超时。
解决方案
基于进程的异步检查点
DCP 现在支持通过后台进程进行异步检查点保存。这有助于消除与训练器线程的 Python GIL 争用,从而避免训练 QPS 下降。请参阅图 2 了解通过线程进行检查点,图 3 了解通过后台进程进行检查点。
保存计划的缓存
DCP 在规划和存储 I/O 步骤之间有明确的界限。DCP 中的 SavePlanner 是一个有状态组件,充当 state_dict 的访问代理。规划器管理由各个等级准备的保存计划,这些计划包含执行写入 I/O 所需的元数据信息。规划步骤涉及一个集体操作,以在协调器等级上收集检查点的综合视图。协调器等级负责对参数/权重进行去重以消除冗余,验证全局计划以确保准确性和一致性,并创建全局元数据结构。随后是一个散射集体操作,协调器等级将 I/O 任务分配给每个等级。对计划进行的任何转换都会影响存储组件最终写入数据的方式。
在训练作业过程中,会保存多个检查点。在大多数情况下,不同保存实例之间只有检查点数据发生变化,因此计划保持不变。这为我们提供了一个缓存计划的机会,只在第一次保存时支付规划成本,然后将该成本分摊到所有后续尝试中。只有更新的计划(在下一次尝试中发生变化的计划)通过集体操作发送,从而显著降低集体开销。
实验结果
设置: 1856 个 H200 GPU,Llama3-70B,HSDP2 和 TorchTitan
部署上述两种解决方案后,关键结果如下
- TPS 下降幅度显著缩小,峰值下降到 372 tps(之前为 315 tps),并且持续时间大大缩短(约 67 秒对比约 437 秒)。这个时间窗口现在主要归因于 CPU 处理的阻塞。
- 由于规划阶段的开销非常低,后续的检查点保存尝试也更快。因此,端到端延迟提高了 6.5 倍以上。这将使我们的合作伙伴能够增加检查点频率并减少训练进度损失(即浪费的训练时间)。
如果您查看图 1 中的第一个下降尖峰,GPU 处理时间的这种下降使训练吞吐量从 700 降至 320 tps,并抑制了大约 7 分钟(467 秒)。一旦 CPU 完成处理,训练再次以全速继续。
以前,这种大约 7 分钟的抑制会在每个检查点重复。然而,随着新的基于进程的检查点功能,只有第一个检查点具有完整的下降时间(主要由于守护进程初始化开销),因为所有未来的检查点都通过后台进程执行,从而减轻了与训练器线程的 GIL 争用。
这在所有后续检查点中都有视觉显示,其中平均 MFU 抑制时间降至略超过一分钟,表现为急剧的尖峰几乎立即恢复到全 MFU 吞吐量。
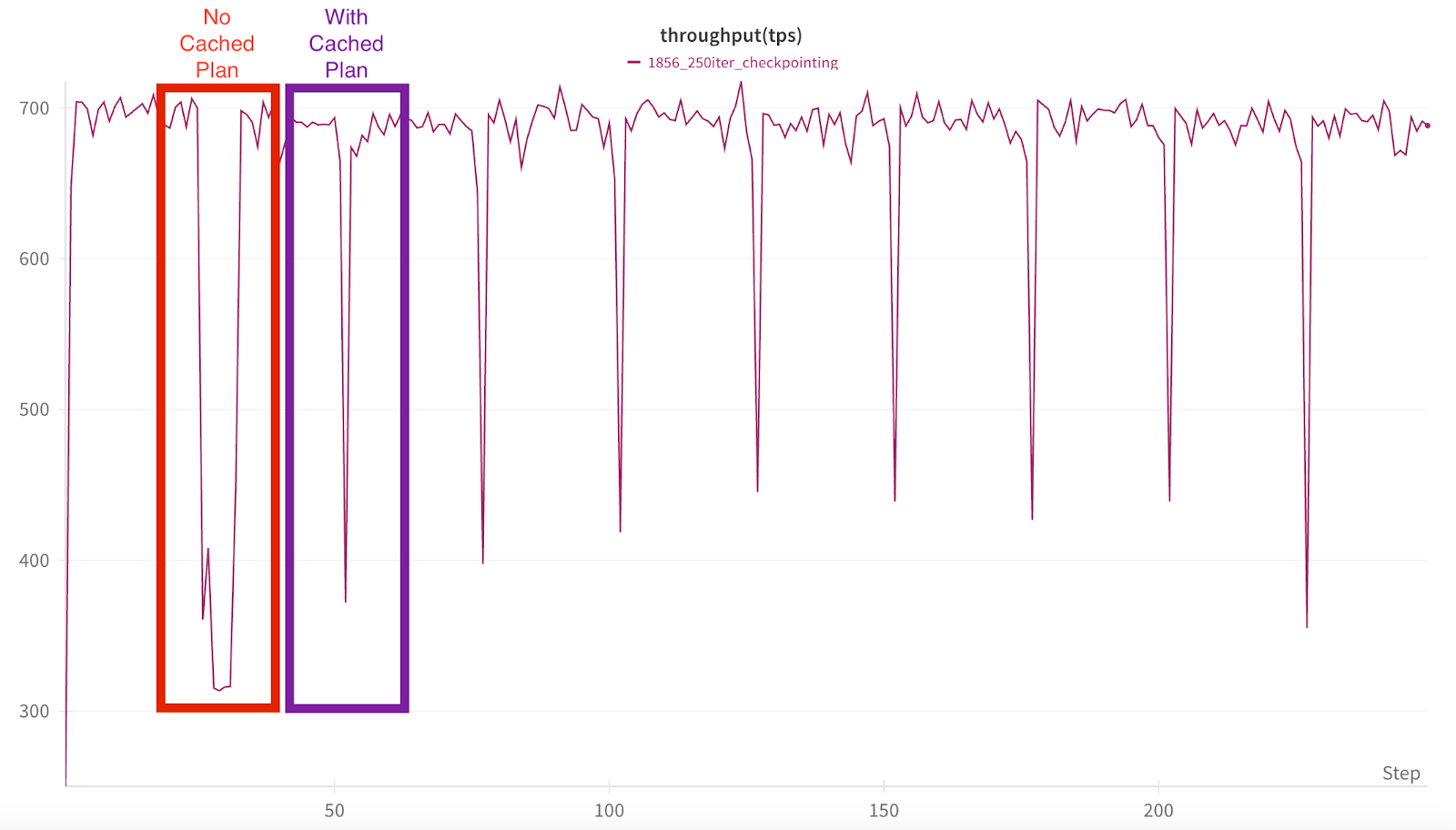 图 3:红色框显示了非缓存计划检查点,其中还包括检查点后台初始化进程开销,而紫色框突出显示了第一个使用缓存计划运行的检查点。
图 3:红色框显示了非缓存计划检查点,其中还包括检查点后台初始化进程开销,而紫色框突出显示了第一个使用缓存计划运行的检查点。
这意味着即使是图 2 中所示的 1856 个 GPU 规模的大规模检查点,也可以将训练吞吐量影响降低约 6 倍。这使得异步 DCP 检查点可以更频繁地运行(从而提供更好的回滚保护),同时相对于以前的异步检查点开销提高了总训练吞吐量。
使用 DCP 的缓存检查点
此功能已作为 PyTorch 每夜构建的一部分提供,您可以直接在 TorchTitan 中测试 PyTorch 的异步 DCP 检查点。以下是启用这些功能的说明
- 基于进程的异步检查点
- 在 async_save API 中将 async_checkpointer_type 设置为 AsyncCheckpointerType.PROCESS。(文件:pytorch/torch/distributed/checkpoint/state_dict_saver.py)
- 保存计划缓存
- 在 DefaultSavePlanner 中将 enable_plan_caching 标志设置为 true。(文件:pytorch/torch/distributed/checkpoint/default_planner.py)
未来工作
DCP 将推出更多优化,以进一步降低检查点成本。目前,即使保存计划已缓存,协调器等级仍然准备元数据。对于具有许多张量的大型作业和模型,此开销不容忽视。在下一次迭代中,DCP 将消除元数据开销并进一步提高端到端延迟。DCP 还将引入额外的优化,例如零开销检查点,以实现大规模作业中的高效检查点。
敬请期待!